












在SQL Server中使用 select into 可以创建一张新表的同时将原有表数据追加到新表中,现在创建一张测试表,里面存放各城市大学名称:
create table [dbo].[school](
[id] [bigint] identity(1,1) not null,
[name] [varchar](50) not null,
[cityid] [bigint] not null,
constraint [school_primary] primary key clustered
[id] asc
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
为测试表创建以cityid为索引列的非聚集索引:
create nonclustered index [index_school_cityid] on [dbo].[school] ([cityid] asc)
- 1.
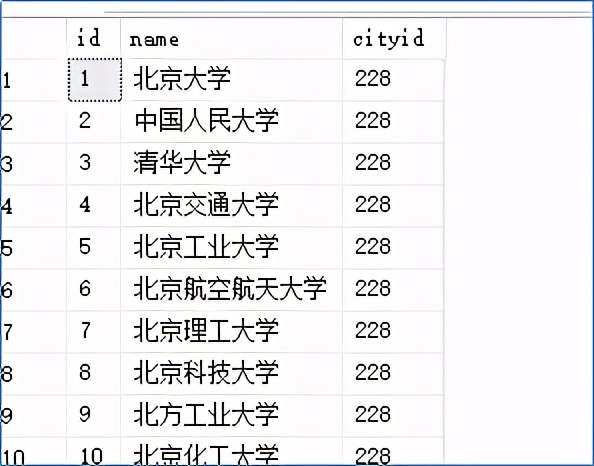
追加数据后,查看该表的数据:
select * from school
- 1.
现在使用 select into 复制一张新表school_test:
select * into school_test from school
- 1.
查看新表school_test的数据,和原有表schoo相同:
select * from school_test
- 1.
再来看看新表的结构,发现id的自增属性被复制了:
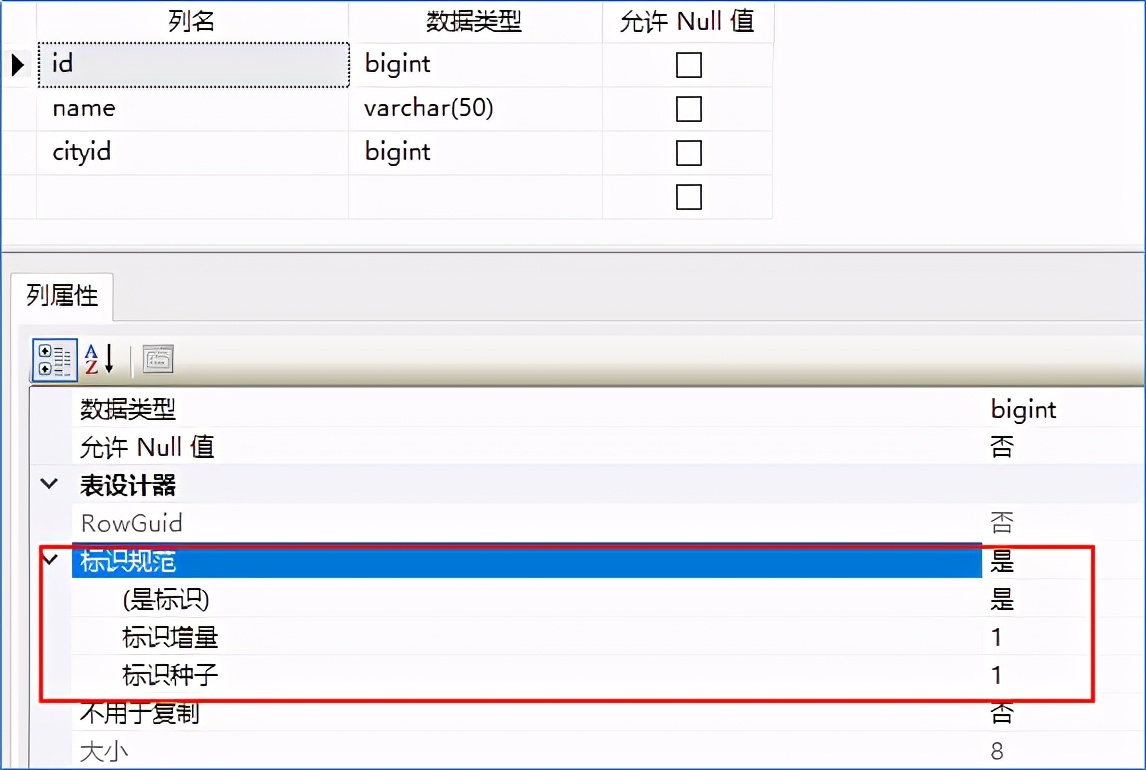
而其他的属性,如原表的主键和索引却没有被复制到新表:

说明使用select into 可以复制原表的数据、字段和自增属性,而主键和索引等却无法被复制。











