之前跟大家分享过SQL和EXCEL效率提升的小技巧,链接放在了文章末尾,今天跟大家分享一下多年来一直用的python效率提升的方法。这个方法是某位上古大神传授于我师傅,师傅又传授于我。
我们平时在跑数据的时候可能会将数据结果存储在txt文件中,不知道大家平时是怎么处理txt文件中的数据的,相信各位同学都有自己的方法,用python的pandas包或者把数据塞进数据库再用sql等等。无论是用哪种方法在处理数据的时候有很多方法是通用的,比如where,join等等,可以先将这些常用方法写成python脚本,需要对txt文件的数据进行处理时直接用脚本来处理txt文件。优点在于省掉了txt和数据库之间来回倒腾数据的时间,也省掉了用pandas读取数据写脚本的时间,能够快速方便地验证和处理数据。
在举例子之前要先介绍一个linux中“管道” 的概念,熟悉linux的人应该对这个概念不陌生,符号为“|” ,管道的作用在于连接多条命令比如命令:cat data.txt|wc -l 的含义就是查看data中数据条数,其中“|”就是管道,将cat data.txt的输出作为wc -l的输入。总结来说只要第一个命令向标准输出写入,而第二个命令是从标准输入读取,那么这两个命令就可以形成一个管道。同样我们可以用将输出传递给python脚本。
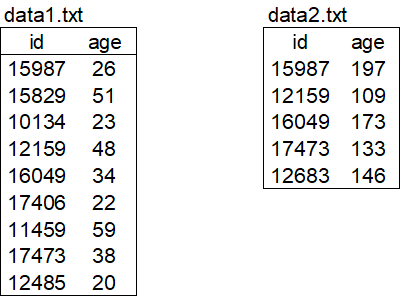
明白了管道的概念,那我们开始吧,案例数据如下:
data1.txt记录用户的id以及年龄,data2.txt记录用户的消费信息
首先我们写一个实现where功能的python脚本,脚本如下:
where.py
#!/usr/bin/env python
# -*- encoding:utf-8 -*-
import sys
import re
import cutmode
def where(col, cmpexpr, val, cmptype):
sw ={
'>': lambda y, x: y > x,
'>=': lambda y, x: y >= x,
'<': lambda y, x: y < x,
'<=': lambda y, x: y <= x,
'==': lambda y, x: y == x,
'!=': lambda y, x: y != x,
}
for line in sys.stdin:
line = line.strip()
#data= re.split('\s+',line)
data = line.split('\t')
if len(data) <= col : continue
if cmptype == 'int':
number = int(data[col])
val = int(val)
elif cmptype == 'float':
number = float(data[col])
val = float(val)
else:
number = data[col]
if sw[cmpexpr](number,val):
print line.strip()
if __name__ == '__main__':
col = int(sys.argv[1])
cmpexpr = sys.argv[2]
val = sys.argv[3]
cmptype = sys.argv[4]
where(col, cmpexpr, val, cmptype)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
程序就不一行行解释了,简单来说一下几个参数,其中 python 程序的四个参数
- col 表示第几列
- cmpexpr 表示比较运算符(>,>=,<,<=,=,!=)
- val表示要比较的数字
- cmptype表示数据类型
我们筛选年龄大于24岁的用户,指令和结果如下:
cat data.txt|python where.py 1 '>=' 25 int
- 1.

join.py
#!/usr/bin/env python
# -*- encoding:utf-8 -*-
import sys
import re
def makeJoin(joinfields, file_list=[]):
dict = {}
file_last = open(file_list[-1])
k, v = joinfields[-1].split(':')
k, v = int(k),int(v)
for line in file_last:
sps = re.split('\s+', line)
if len(sps) >= max(k,v):
val = sps[v] if v >= 0 else ''
dict.setdefault(sps[k], val)
file_last.close()
for i in xrange(len(file_list)-1):
fd = open(file_list[i], 'r')
field = joinfields[i].split(':')[0]
for data in fd.readlines():
attr = re.split('\t', data.strip())
if len(attr) <= int(field):continue
joinid = attr[int(field)]
appendix = dict[joinid] if joinid in dict else 'noright'
print data.strip() + '\t' + appendix
fd.close()
if __name__ == '__main__':
joinfields = sys.argv[1].split(',')
file_list = sys.argv[2:]
makeJoin(joinfields, file_list)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
下面将两个数据进行join,计算出每个用户的年龄以及对应的花费。
指令如下:python join.py '0:1,0:1' 'data1.txt' 'data2.txt'
- 第一个0:1 表示data1.txt的链接主键为0列,值为1列
- 第二个0:1 表示data2.txt的链接主键为0列,值为1列
- data1.txt 和data2.txt 分别为需要链接的文件

select.py
#!/usr/bin/env python
# -*- encoding:utf-8 -*-
import sys
import re
def cut(files,col1,col2):
col1=int(col1)
col2=int(col2)
f=open
for line in sys.stdin:
line_list=line.split()
if(len(line_list)>=max(col1,col2)):
if col1>=0 and col2>=0 and col1<=col2:
print("\t".join(line_list[col1:col2]))
else:
print("参数输入错误")
else:
print("参数超出范围")
if __name__=="__main__":
col1=sys.argv[1]
col2=sys.argv[2]
cut(col1,col2)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
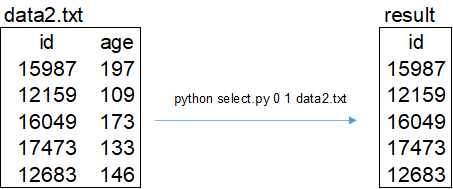
取出有花费的用户id,指令如下:
- col1:开始列
- col2:结束列
python select.py 0 1 data2.txt
综合使用
选出data1中付过费,且年龄大于35岁的用户id
python join.py '0:1,0:1' 'data1.txt' 'data2.txt'|python where.py 2 '!=' null string|python where.py 1 '>' 35 int|python select.py 0 1
12159
17473
- 1.
- 2.
- 3.
- 4.
- 5.