【51CTO.com快译】
为什么如此重视?
首先
• 在表格中哈希映射、关联数组或字典数据结构如何工作?
• 什么时候适合使用哈希表存储项目?
• 如何处理哈希表中的“冲突”?
方便查找:
假设,我们想存储一个用户列表,以便以后可以根据他们的名字查找。

我们可以简单地将用户存储在一个数组中,当以后需要找人时,可通过遍历所有数据的方式查找目标用户。
当我们只有3个用户时,通过简单的方式便可以轻松的查找到。但是,如果我们有成千上万的用户,过程将会十分的慢。因此,通过使用哈希表,可以更好地完成查询。
正是因为哈希表以键值对的方式存储,使查找数据的速度比在数组中循环快得多。
创建哈希表
使用哈希表,首先需要为每个用户提供一个唯一的值-即 key(索引),将使用此索引存储该项,便于以后检索中使用。
假设每个用户都有一个唯一的名称,并将其用作主键。在实际应用中,例如使用ID作为主键。
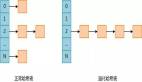
哈希表的工作原理是将键值对存储在桶(Bucket)中,Hashtable由多个Bucket组成,每个Bucket中存放着所有HashKey相同的(Key, Value),如图所示:
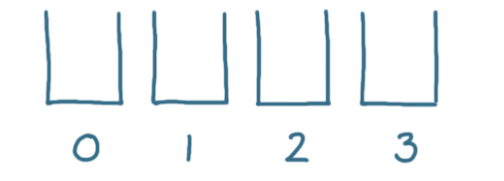
为了简单的示例,我们将使用4个存储桶(Bucket)。
当将一个用户添加到哈希表时,我们使用其索引来确定将其存储在哪个存储桶(Bucket)中。
当需要再次检索用户时,即可以直接跳到正确的桶(Bucket)以找到目标,这样比依次查找要更快。
存储表
在表中存储第一个用户“ Ada”。
首先,确定将其存储在哪个存储桶中。这意味着我们需要从一个字符串('Ada')存放在关键字的位置,代入函数后若能得到包含该关键字的记录在表中的地址。这样做的过程是我们的哈希表,函数为哈希函数。
在此示例中,我们将创建一个简单的哈希函数。以用户名中的每个字母为它分配一个数字; A=0, B=1, C=2等等。最后,把所有的值加在一起,结果就是散列值,也就是哈希值,所在的位置就是散列地址。
对于“ Ada”,该数字为3—因此我们可以将Ada存储在存储区3中:
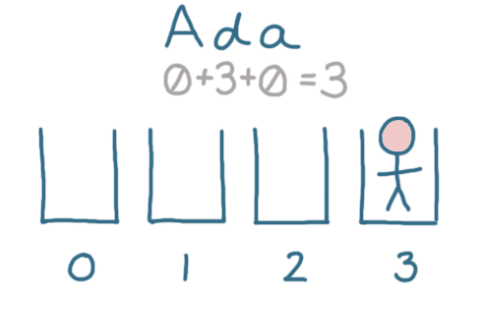
当以后需要检索“ Ada”时,可以对她的名字执行相同的哈希函数。这将告诉我们在3号存储桶中寻找她,而无需遍历数组。
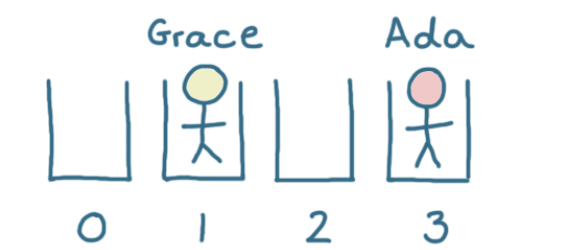
接着存储下一个用户“ Grace”:
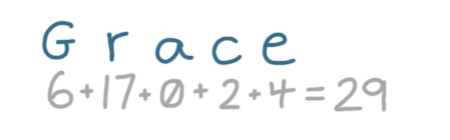
“Grace”的哈希值为29,但我们没有29个存储桶!
只使用其散列值存储数组将意味着我们将需要大量的Bucket。相反,我们需要一种方法将哈希值(29)转换为Bucket号(从0到3)。
一种常见的实现方法是将哈希值除以存储桶数,然后将其余部分用作Bucket号。
将两个数相除后得到的余数称为模。“Grace”的哈希值为29,我们有4个存储桶。将29除以4后的余数为1,因此“Grace”存储在编号为1的存储桶中。
此操作可以编写为29 % 4 = 1,或者是29 mod 4 = 1。
当我们以这种方式计算存储桶时,哈希表如下所示:
冲突
一个好的Hash函数不仅性能优越,而且还会让存储于底层数组中的值分配的更加均匀,减少冲突发生。
实际上是将输入键(定义域)映射到一个非常小的空间中,所以冲突是无法避免的,能做的只是减少Hash碰撞发生的概率。
接着存储“Tim:
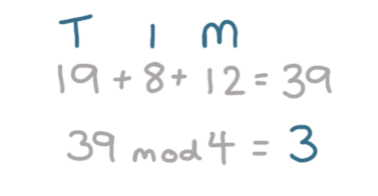
现在,我们有两个用户需要存储在存储桶3中:
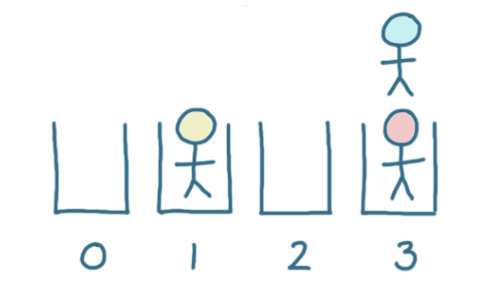
有两种方法可以解决这个问题:
我们可以使用一种算法来不断选择新的存储桶,直到找到一个空的存储桶,然后将散列地址存储在那里。每个存储桶中只有一个底层数组的方法称为 开放式寻址。
或者,存储一组散列地址,而不是在每个bucket中只存储一个散列地址。当我们使用这种方法发现碰撞时,我们只需将冲突的键值对放在同一个存储桶中即可。
当以后需要检索该数组时,我们仍然可以直接跳转到正确的存储桶。不过,这次存储桶可能包含多个数组。在这种情况下,我们将依次检查存储桶中的每个数组,寻找我们想要的数组。
这称为 公共溢出区,通常用于哈希表实现。
这就是为什么好的哈希函数对性能至关重要的原因之一 。
不好的哈希函数无法平均分配项目,因此它们最终只能集中在少数可用的存储桶中。
在最坏的情况下,如果一切都在同一个桶里,则可能会遍历每个项目来查找所需的内容。这就是我们通过使用哈希表来避免麻烦的原因!
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】