












本文转载自微信公众号「三太子敖丙」,作者三太子敖丙。转载本文请联系三太子敖丙公众号。
正文
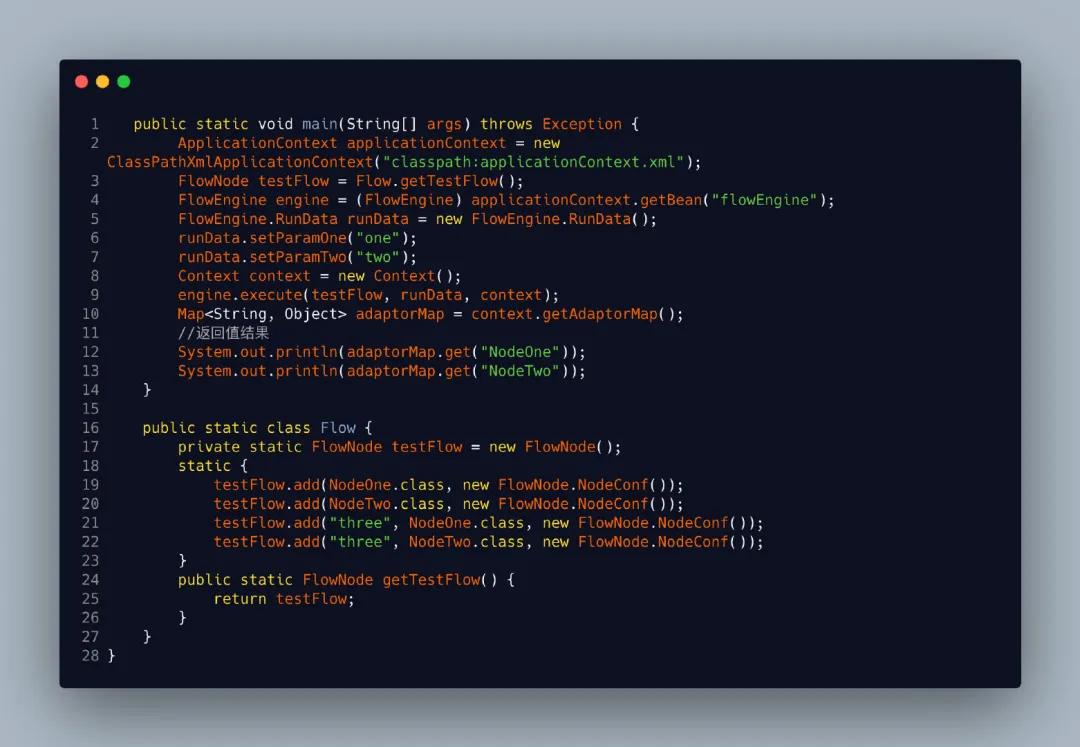
在电商里面处理复杂的业务逻辑场景很多,我们还是以创建商品为列子。很多人可能会问创建商品很复杂吗?我们接着往下看就知道了。
创建商品流程:
- 参数必填性校验
- 参数数据转换
- 商品基础信息校验
- 商品与商家之间的校验
- 类目信息校验
- 商品交易信息校验(这个看公司业务决定)
- SKU相关信息校验
- 商品是否需要有特定标签校验(看公司业务决定)
- 商品类型校验(普通,卡片,视频.......)
- 商品风控校验
- 保存商品信息
- 保存SKU信息
- 保存商品详情信息
- 重量模版
- 运费
- 配送区域
- 。。。。。。。
大家现在看看觉得创建一个上还简单吗?这里商品类型里面还涉及到各个业务场景校验,我们就先不谈了。针对这样的情况我们应该怎么去写这个代码呢?我翻看了一下以前大学写的一些代码整体的代码格式大概也就是这个样子
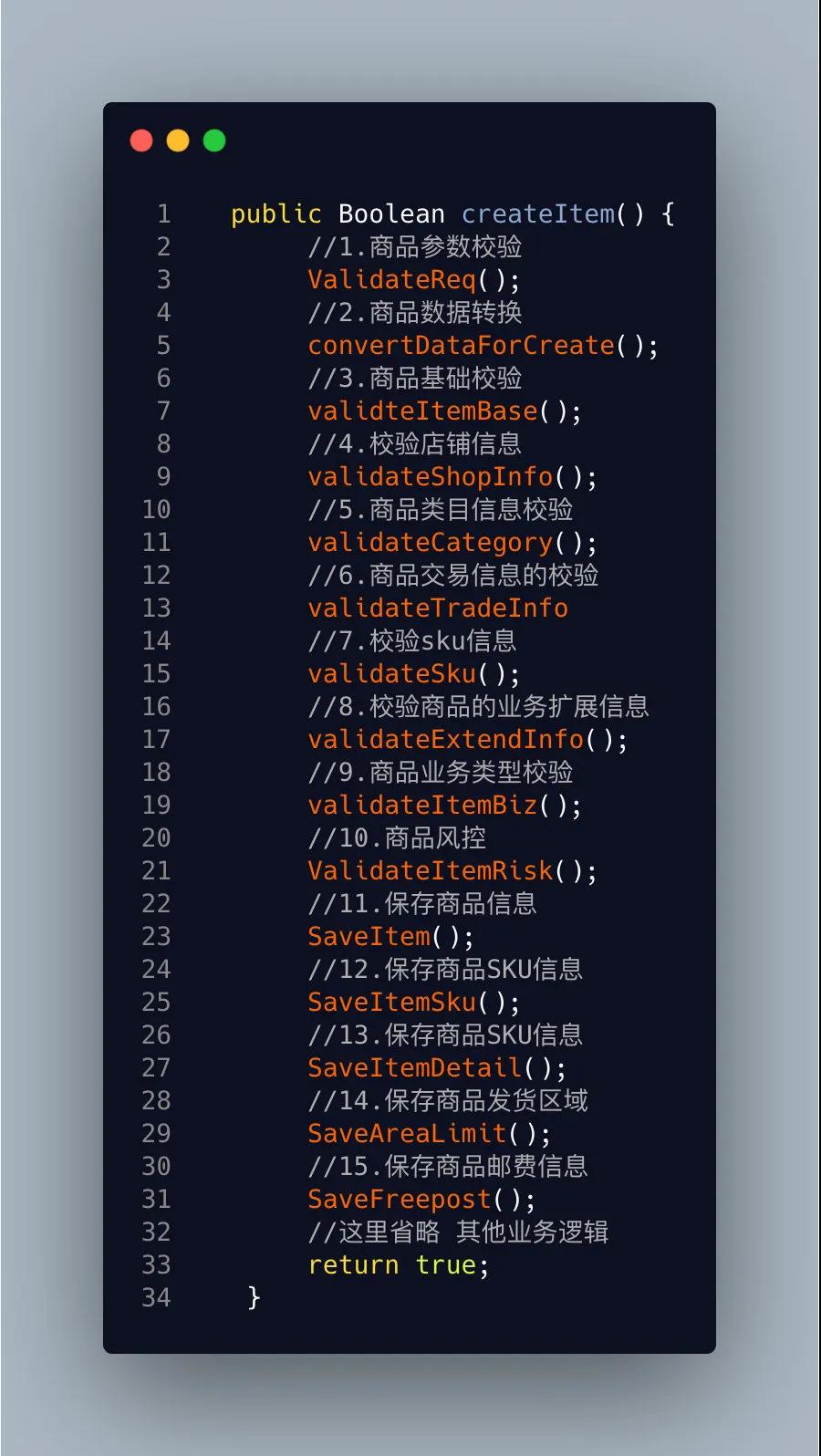
这么写其实也没有什么问题,功能也能实现。但是这么写其实有很多弊端的:
- 代码可读性不高
- 代码扩展性不高
- 耦合性太强,有些东西不好公用
- (重点)整体创建执行流程时间太长,串行调用下游服务
看到这样代码我们首先都是吐槽一顿,然后还是老老实实是去改。有动手能力强的同学可能会想着去优化一下。再看看这个流程,其实在创建商品的时候我们很多校验和保存数据是m没有依赖且互不影响的,我们完全可以去并行执行。
节省创建商品的流程时间,提高用户体验。(PS:就好比两条高速一条堵车,一条畅通无阻,选哪条?)所以针对这么并行问题我还是给大家画了一个流程图:
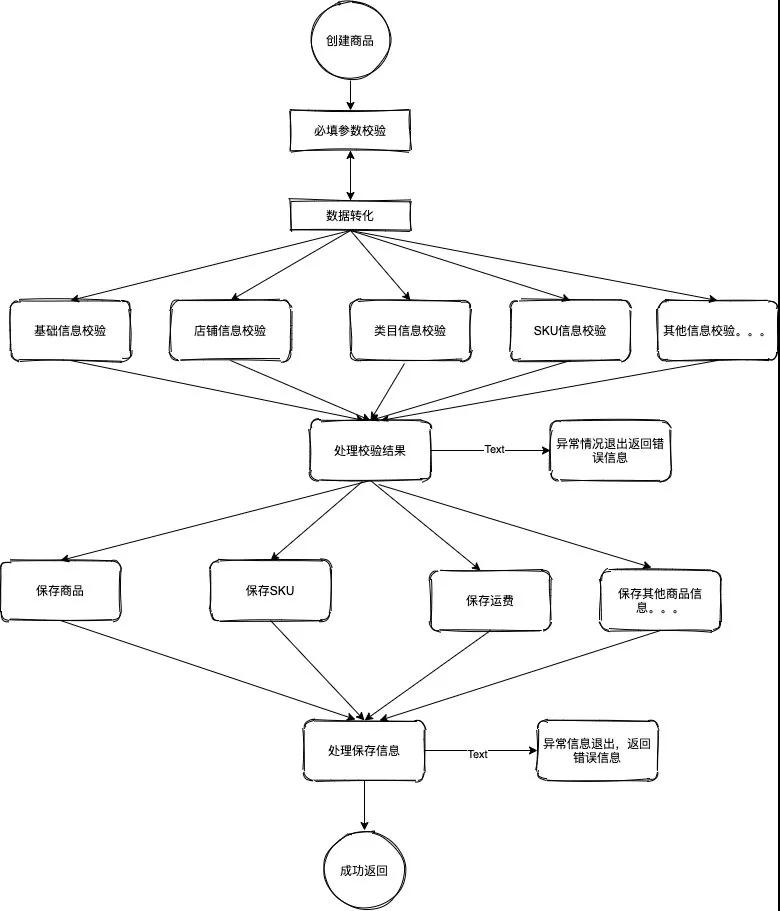
通过这图我们看到创建一个商品流程,我们调用的下游服务可能是有十几二十个或者更多,假设我们一次RPC调用的平均返回时间是50毫秒,串行执行时间可能就到1-2秒了,那么我们并行执行话也就200到300毫秒了。
所以本着这种思想可能有人会问,为什么我不能异步,不能用消息?创建商品假设用异步消息的话,如果消费失败那用户创建的商品成功保存其他信息失败了,那对用户来说不是更加体验不好了?
说了这么多我们开始撸代码了
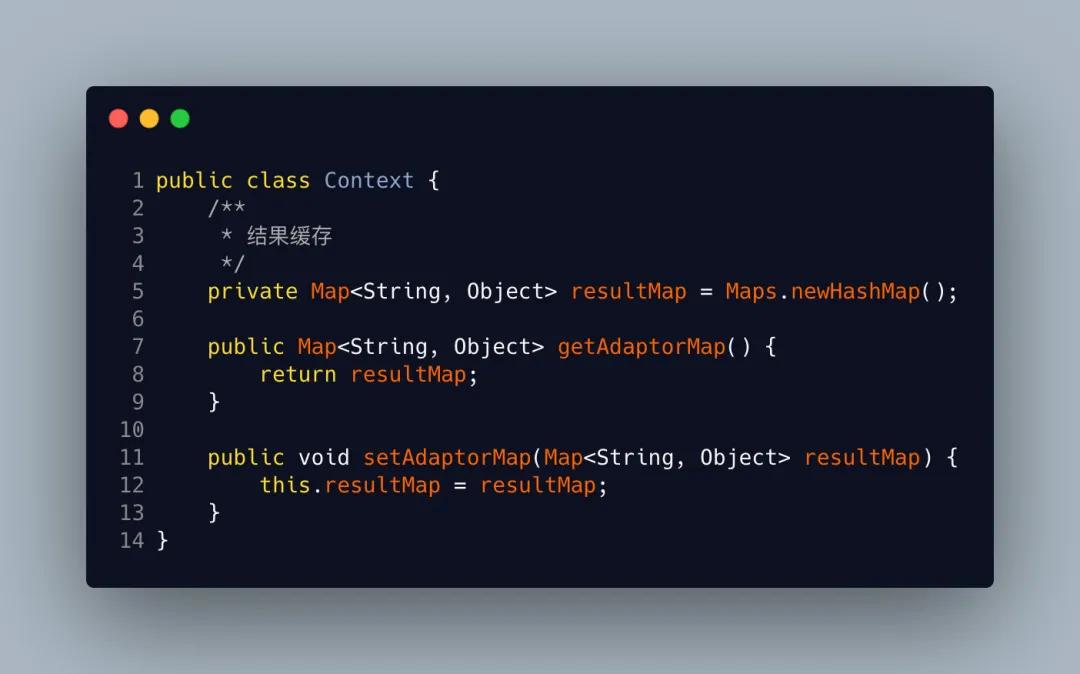
先创建一个Context 上下文,作为我们的调用下游服务的返回结果
图片
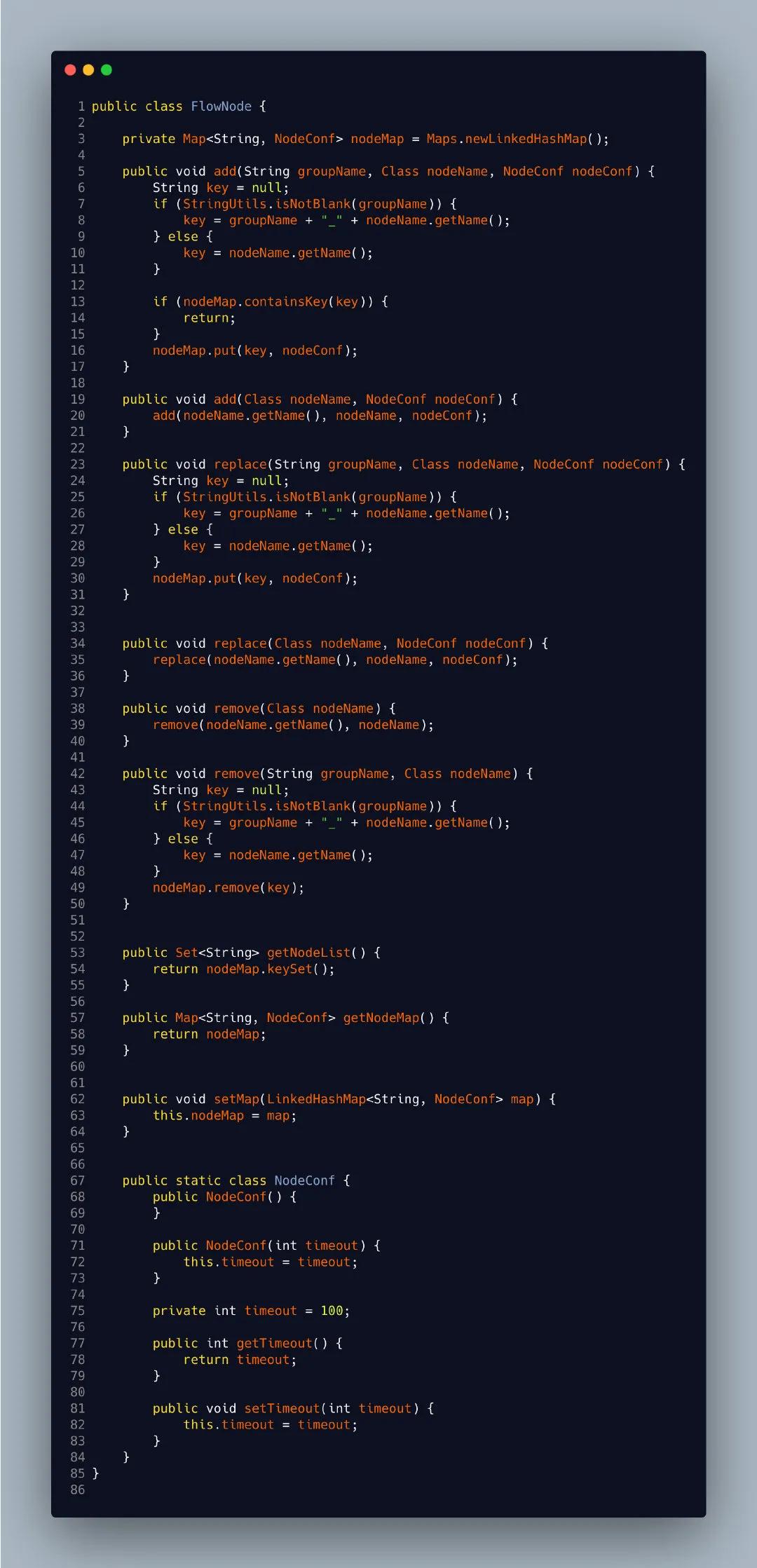
第二步创建我们的流程节点,这相当于就是保存我们整个流程中需要执行下游服务的节点,以Map作为保存数据,NodeConf 节点设置参数,自定义请求服务超时时间(因为并行我们是用的线程池或者通过get设置时间get返回值结果)
第三步引擎类,这个也是我们的核心类。通过我们添加的node节点判断我们哪些流程是需要串行的那些是需要并行的,通过线程池创建线程放入Feature中,来达到同步执行的效果。
在使用线程池的时候我们需要考虑不要设置的参数过大,开启另外的线程也是会占用机器内脆的,一个线程按1兆来算,你开启几百上千个,也会占用很大的一部分内存。尽可能的去采用池化思想,这里就按大家实际场景去做测试。
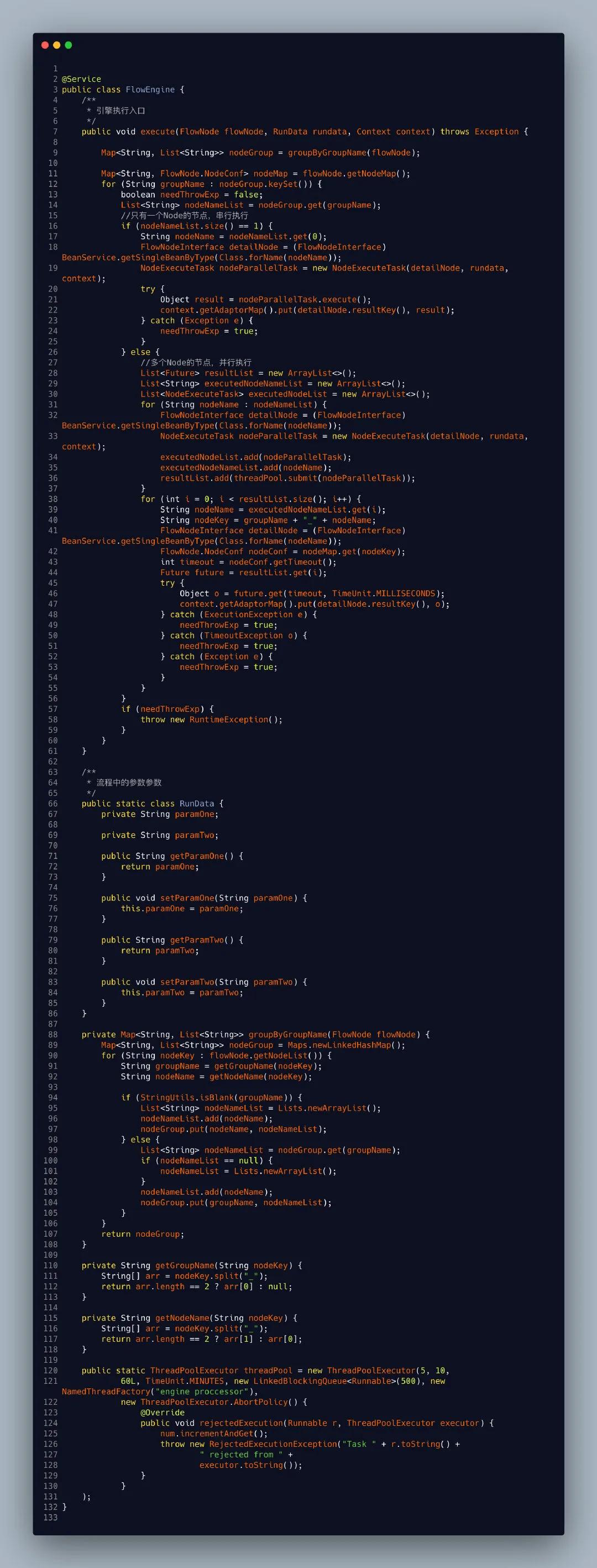
第四步执行Call方法,也就是执行我们的node节点。
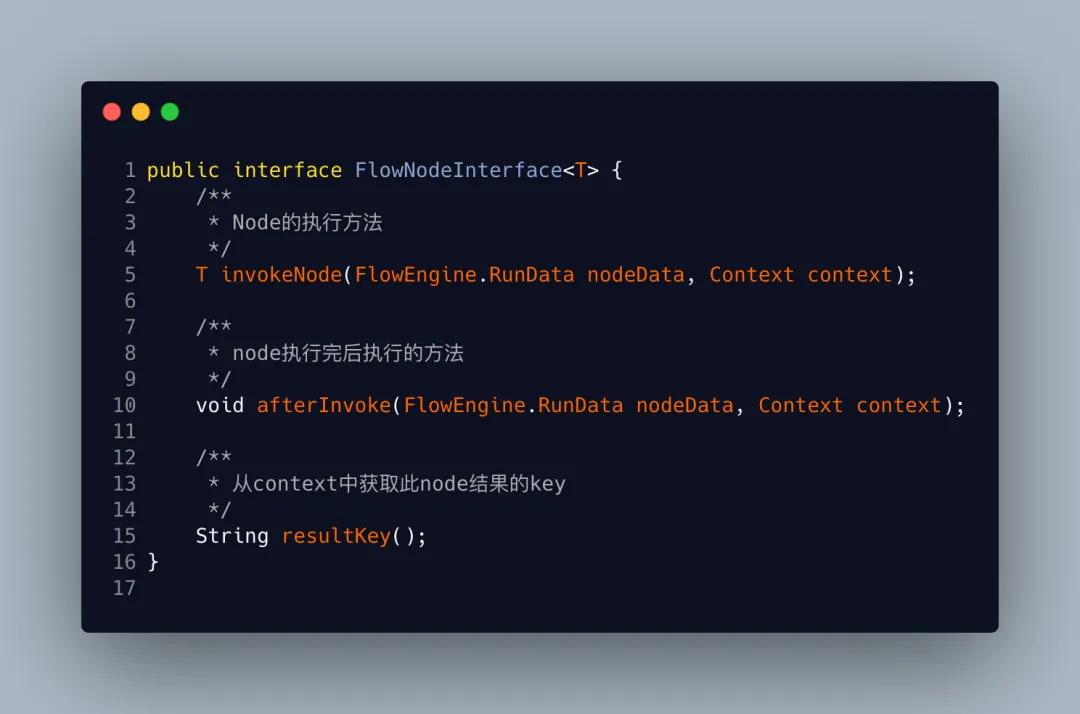
第5步创建节点接口,这里我们要定义一个ResultKey,这个Key也就是跟我流程中的这个节点所绑定,在获取数据的时候也就是通过者key来标识
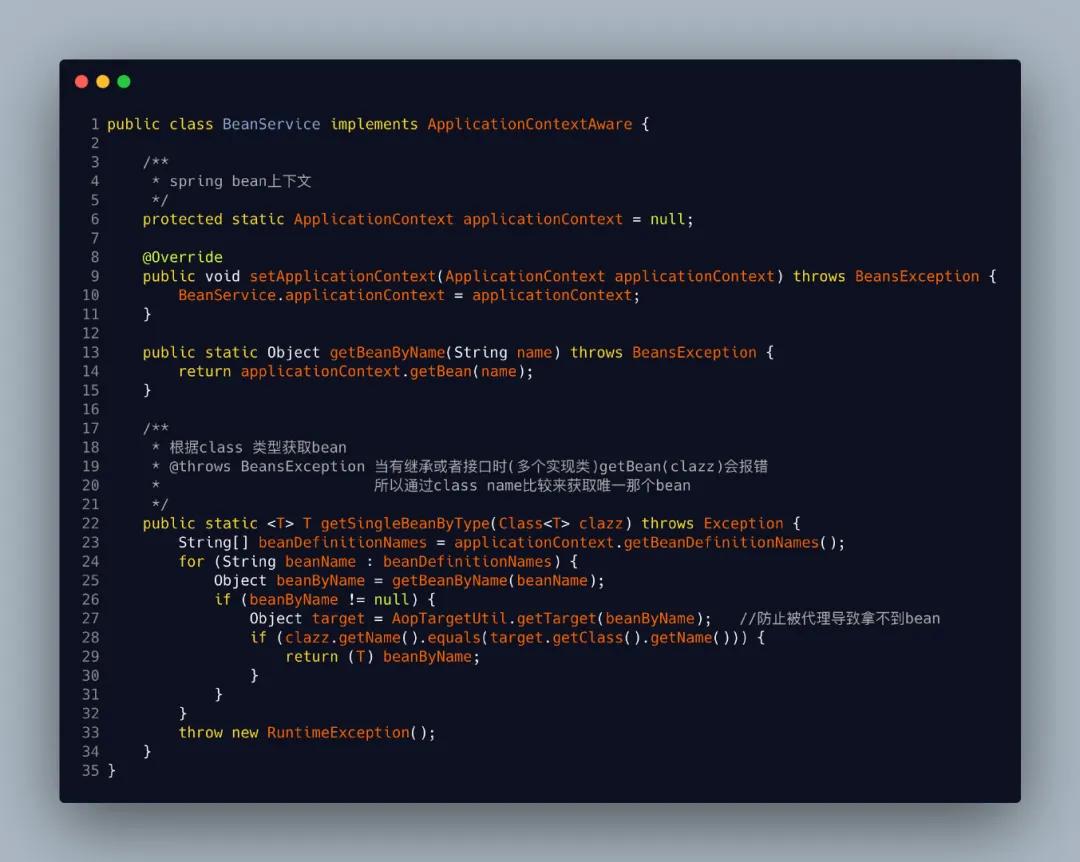
第6步因为我们在节点里面存的Class类,所以我们得通过实现ApplicationContextAware类来获取Spring容器中的bean实例
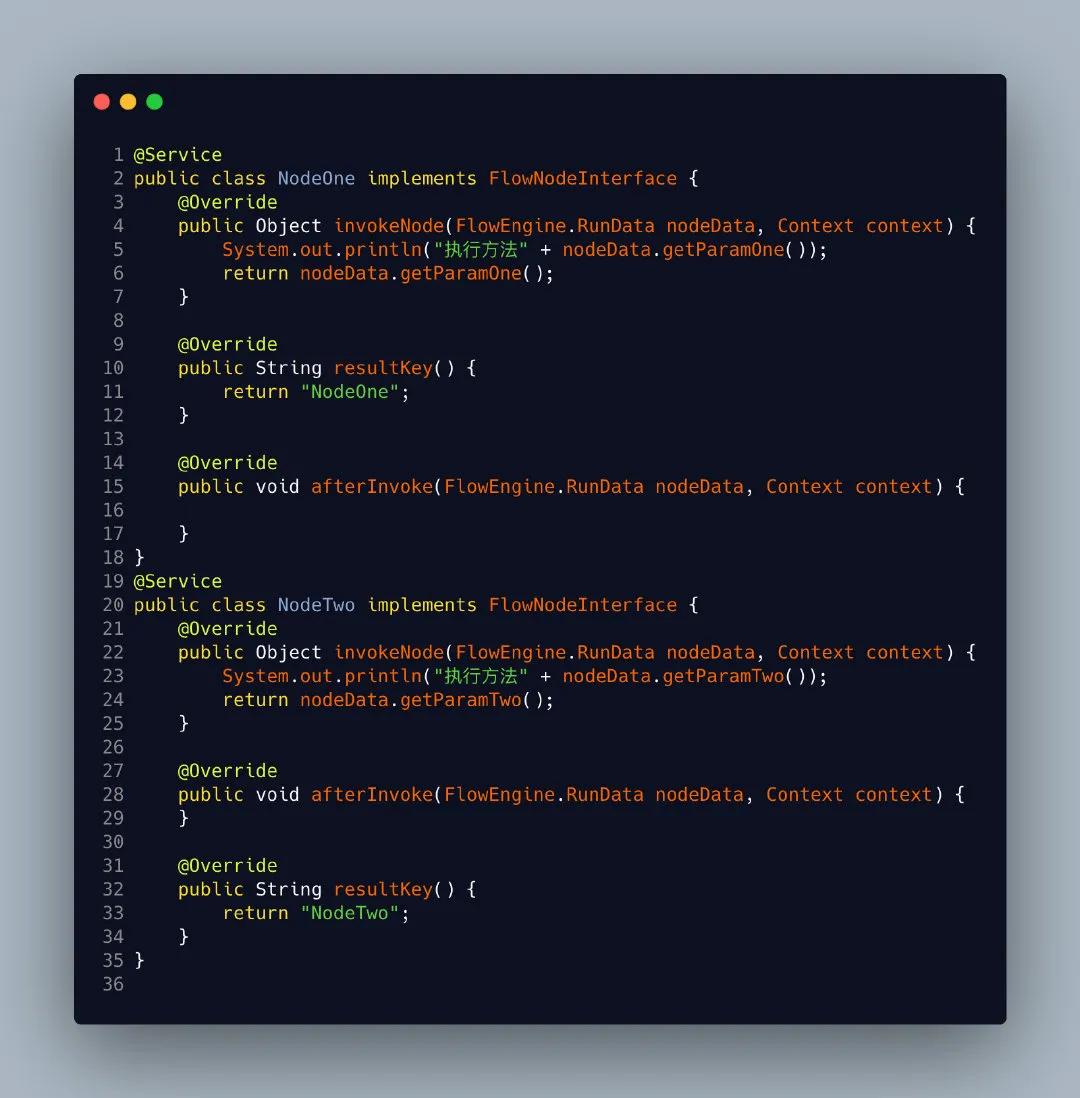
第7步那就是来创建两个测试node节点
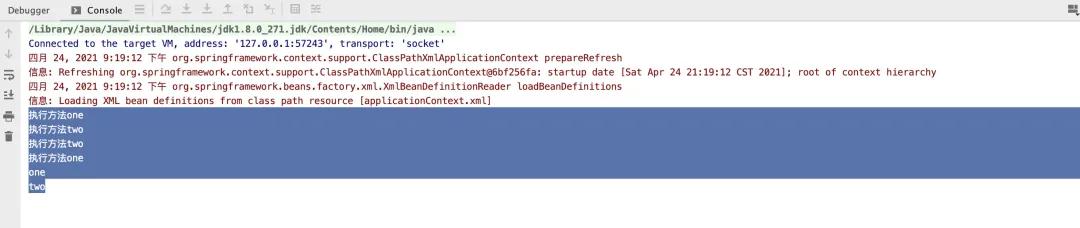
最后当然就是我们的测试结果啦,这里我们创建两个节点NodeOne 和NodeTwo 作为模拟真实业务场景的节点,通过一个后面的three作为一个group 需要并行执行的节点。
看完代码最后再给大家来一个总体的流程图吧
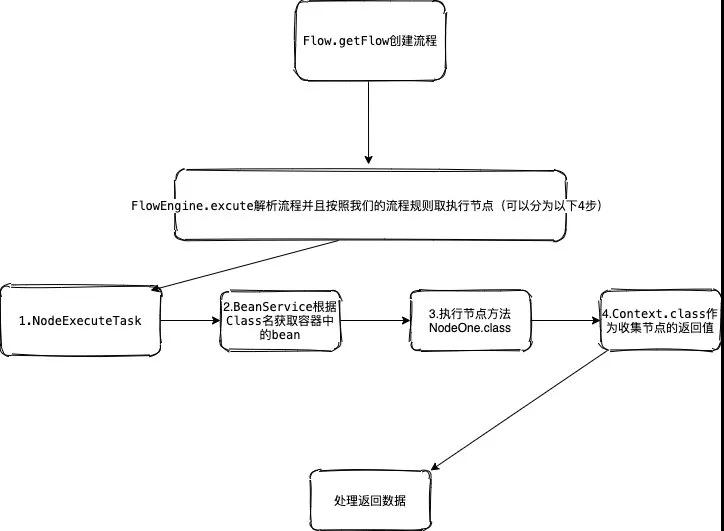
看完是不是觉得感觉自己顿悟,以后再面对复杂流程的业务也就OK拿下了。
思考
其实这里还有很多优化点,每个人遇到复杂的场景可能也不一样,只能说给大家提供一个思想吧,针对不同的场景大家再去做改造吧!!!
给大家做一个扩展:
细心的同学可能会发现这都是强依赖性,能不能有弱依赖在里面呢?
答案:当然可以有弱依赖了,在 FlowNode.NodeConf中我们既然可以设置超时时间 我们也可以在添加一个参数来确定是都是弱依赖。在我们的future.get获取结果的时候当出现异常可以catch住,强依赖则终止流程返回错误信息,否则记录错误日志,流程continue
我们流程保存现在是用的静态代码块,可不可以换其他的方式保存节点呢?
答案:这个当然也可以,我们保存在数据库,ACM,Apollo等等都是可以的。这个取决于你们自己的业务和成本问题。因为流程我们一般是不会经常换的,所以我还是建议代码写死就好了
采用线程池去调用下游服务,会不会造成服务链路追踪失败呢?
答案:这个不能说绝对,但是如果是保存在ThreadLocal中那肯定是会失效的,ThreadLocal中的KEY也就跟当前线程的ID有关,都开启新的线程了,那肯定也就是丢失了
如果采用了ThreadLocal 在节点中是不是就失效了?
答案:第三点已经给出答案了
总结
今天的复杂业务逻辑的流程引擎也就完结了,在我每次看到新的技术以及知识点的时候我都有一种开悟的感觉,引用 邓宁-克鲁格的心理效应来说,在我们的这个年纪其实就是开悟之坡。后
面我会接着再为大家怒肝设计模式,完了也就会再跟大家聊聊重构。其实也就是用我们的设计模式来优化我们的代码。














