












CMU 联合复旦、俄亥俄州立大学的研究者推出了一个将模型可理解分析和模型评价排行榜结合起来的科研辅助工具 ExplainaBoard,能够完成单系统诊断、数据集分析以及可信度分析等任务,有效提升科研人员的学术体验。
你是否在读论文的时候觉得别人的 idea 很有道理,可自己设计 idea 时却无从下手?你是否经常因为「模型效果好,但是没有给出有深度且全面的解释」而被审稿人给低分?
当你厌倦了挖掘新的模型结构时,是否对数据集特性的挖掘感兴趣,从而引领一个更加健康的领域发展方向?在刚接触一个新领域时,如何做到:既能快速了解该领域目前发展的状况,又能快速了解它的瓶颈?
还记得不久前引起网络热议的自动审稿系统么?这支来自 CMU 的 团队日前又发布了一个可解释的系统排行榜(ExplainaBoard),它被定位成一个科研辅助产品,巧妙地把「模型可理解分析」和「模型评价排行榜」两个看似无关的元素结合,将平时科研中很多被我们忽略却很重要的部分转化成「一键式」操作,从而提升科研人员做学术的体验。

系统链接:
http://explainaboard.nlpedia.ai/
论文链接:
https://arxiv.org/pdf/2104.06387.pdf
目前,ExplainaBoard 在单任务上支持分类、抽取、生成在内的9个主流 NLP 任务,涉及40多个数据集、300多个模型;在多任务上,支持多语言评价基准,包含40多种语言和9个跨语言任务。
技术解读
随着深度学习模型的快速发展,排行榜(Leaderboard)已经成为一种用来追踪各种系统性能的主流工具。然而,由于在排行榜上排名靠前的模型所具有的声望,很多研究人员只关注提高评估指标的数字,而忽略了对模型特性更深入的科学理解。
ExplainaBoard 就是在这样的背景下诞生的,它不仅可以排序不同的模型,还提供了很多与模型和数据集相关的——可理解、可交互和可信赖的分析机制(如下图所示):
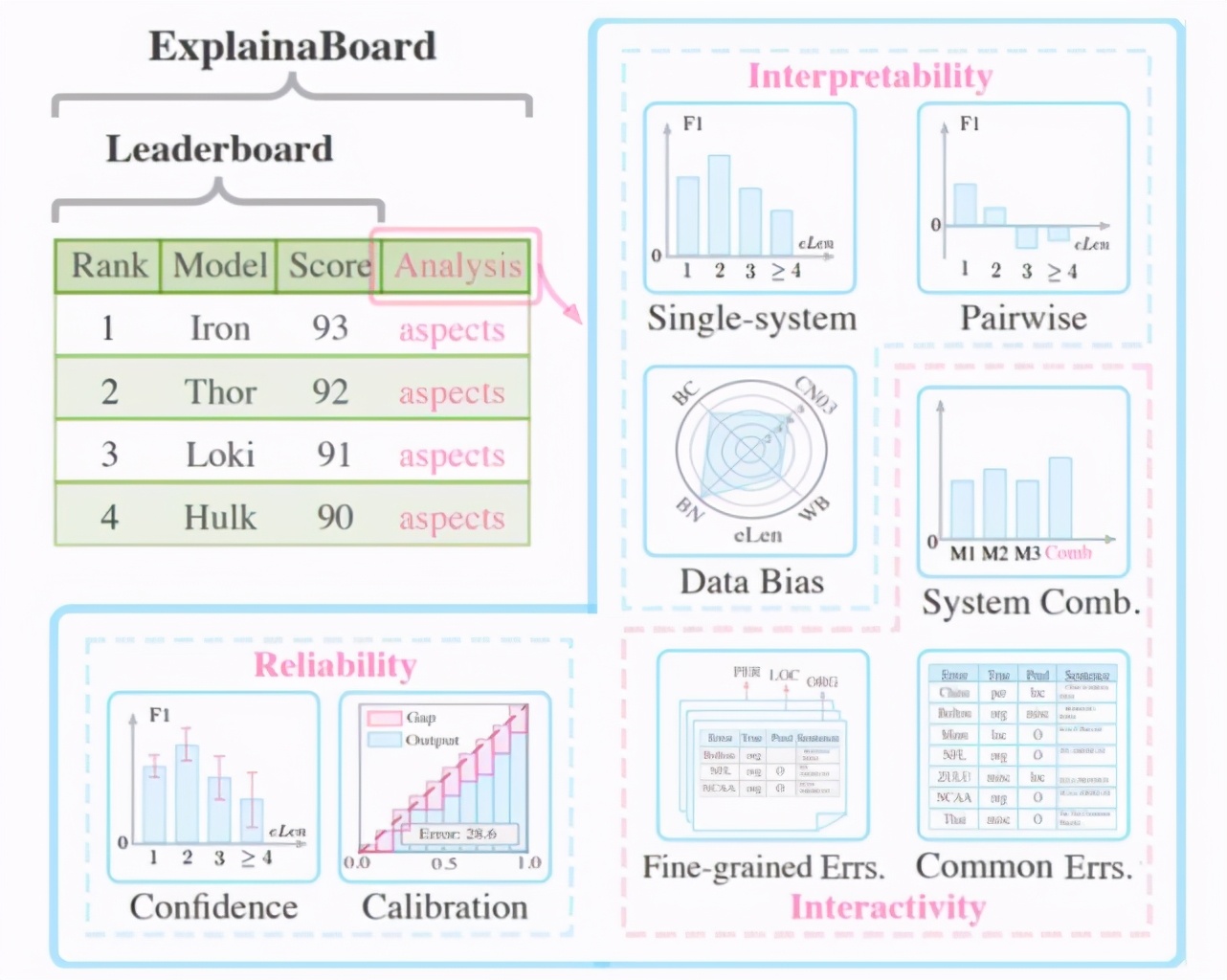
具体说来,它可以完成以下功能:
单系统诊断
可以解决的问题:「我设计的模型擅长 / 不擅长做什么?」

系统对诊断
可以解决的问题:「我设计的模型比别人的好在哪里?」
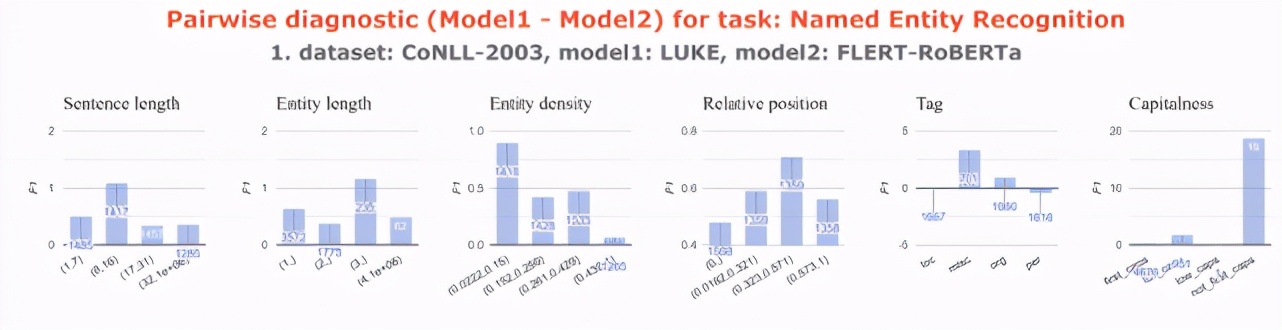
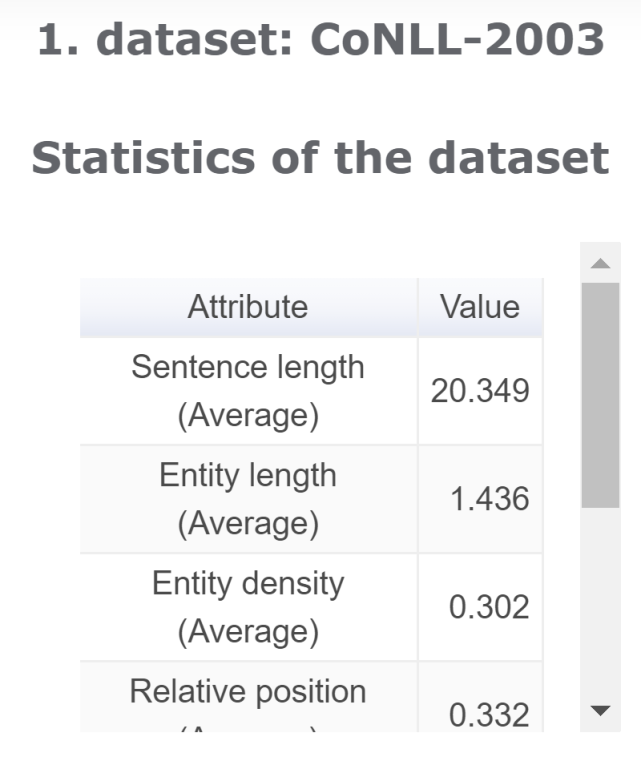
数据集分析
可以解决的问题:「数据集的特点是什么?」
共有错误分析
可以解决的问题:「排名 Top-5 的系统共同错误预测是什么?」

细粒度错误分析
可以解决的问题:「模型错误预测主要发生在哪儿,以及具体是哪些错误?」

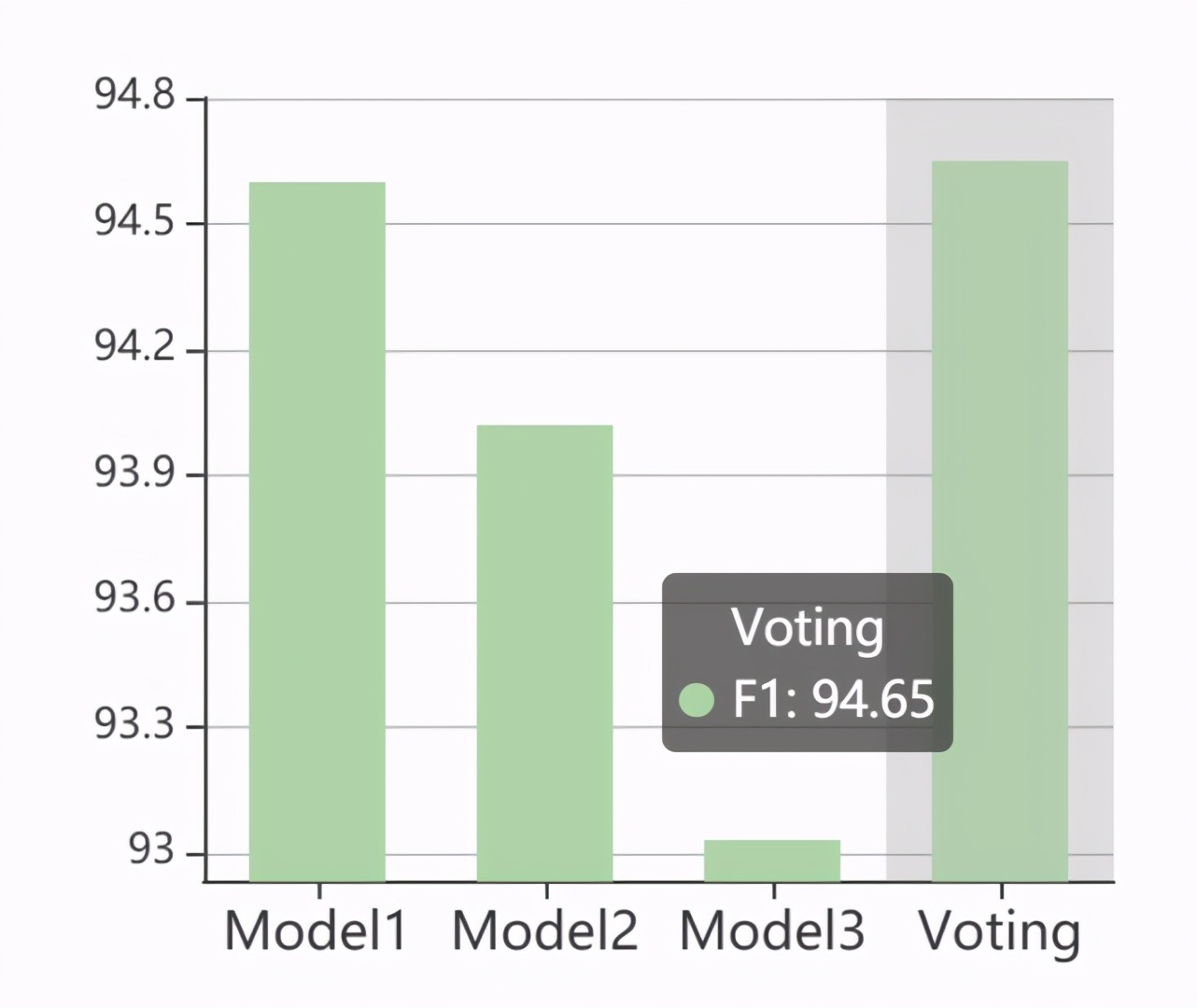
系统组合
可以解决的问题:「将排名 Top-5 的系统组合在一起,会得到一个更强大的系统么?」

可信度分析
可以解决的问题:「模型预测结果的可信程度有多高?」
校准分析
可以解决的问题:「预测的可信度是如何校准其正确性的?」
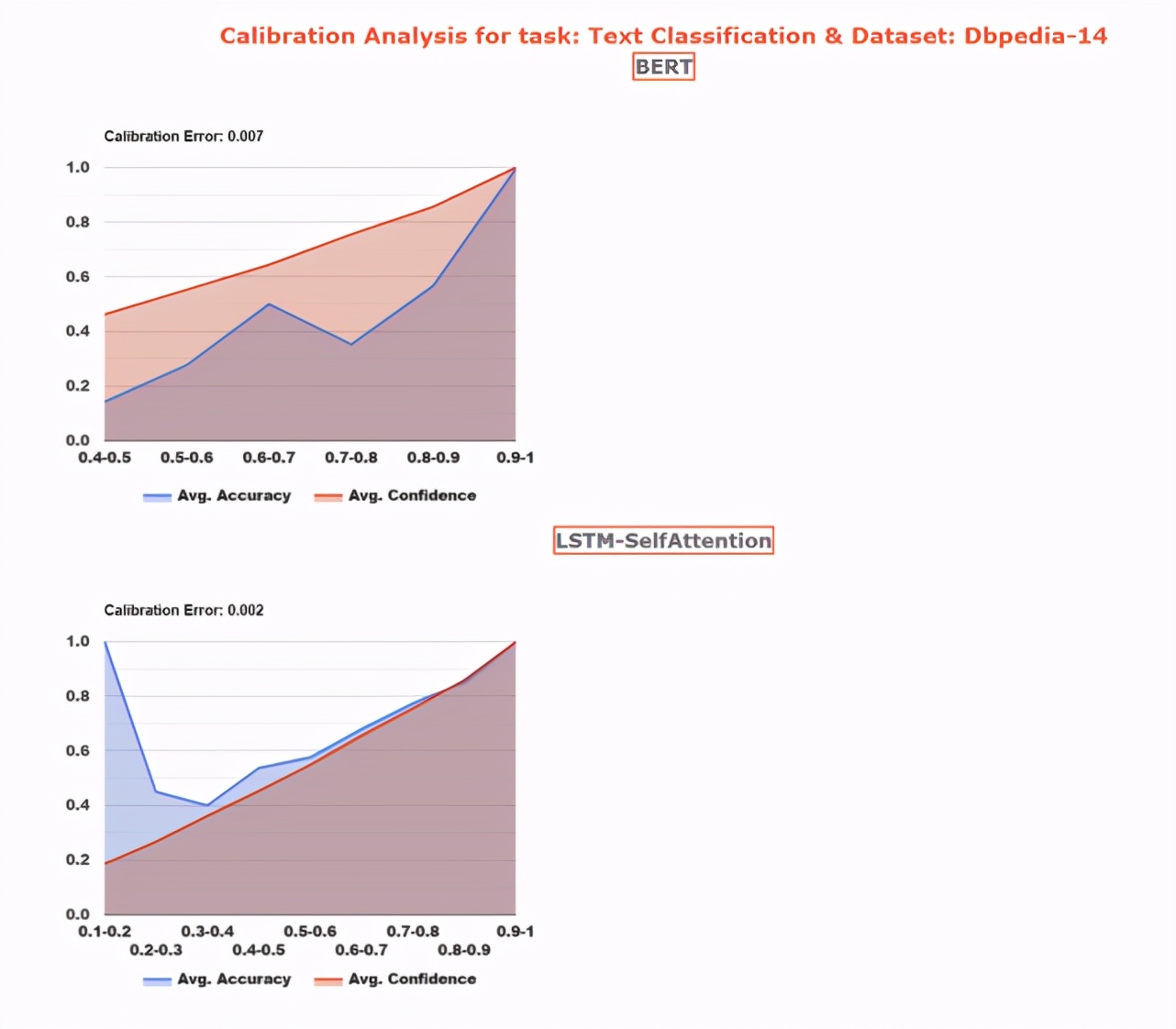
应用前景
在应用上,据该项目负责人刘鹏飞博士介绍,ExplainaBoard 目前收到了 DeepMind、Google、Huggingface 和 Paperswithcode 等多家企业的合作邀请以及投资人的青睐。
比如,Google & Deepmind 最新 arXiv 工作 XTREME-R: Towards More Challenging and Nuanced Multilingual Evaluation 使用 ExplainaBoard 升级了他们的多语言评测基准。





















