近几年来语音识别技术得到了迅速发展,从手机中的Siri语音智能助手、微软的小娜以及各种平台的智能音箱等等,各种语音识别的项目得到了广泛应用。
语音识别属于感知智能,而让机器从简单的识别语音到理解语音,则上升到了认知智能层面,机器的自然语言理解能力如何,也成为了其是否有智慧的标志,而自然语言理解正是目前难点。
同时考虑到目前大多数的语音识别平台都是借助于智能云,对于语音识别的训练对于大多数人而言还较为神秘,故今天我们将利用python搭建自己的语音识别系统。
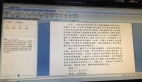
最终模型的识别效果如下:

实验前的准备
首先我们使用的python版本是3.6.5所用到的库有cv2库用来图像处理;
Numpy库用来矩阵运算;Keras框架用来训练和加载模型。Librosa和python_speech_features库用于提取音频特征。Glob和pickle库用来读取本地数据集。
数据集准备
首先数据集使用的是清华大学的thchs30中文数据。
这些录音根据其文本内容分成了四部分,A(句子的ID是1~250),B(句子的ID是251~500),C(501~750),D(751~1000)。ABC三组包括30个人的10893句发音,用来做训练,D包括10个人的2496句发音,用来做测试。
data文件夹中包含(.wav文件和.trn文件;trn文件里存放的是.wav文件的文字描述:第一行为词,第二行为拼音,第三行为音素);
数据集如下:
模型训练
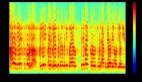
1、提取语音数据集的MFCC特征:
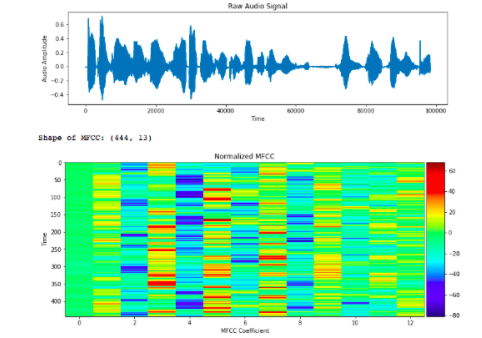
首先人的声音是通过声道产生的,声道的形状决定了发出怎样的声音。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素进行准确的描述。声道的形状在语音短时功率谱的包络中显示出来。而MFCCs就是一种准确描述这个包络的一种特征。
其中提取的MFCC特征如下图可见。
故我们在读取数据集的基础上,要将其语音特征提取存储以方便加载入神经网络进行训练。
其对应的代码如下:
#读取数据集文件
text_paths = glob.glob('data/*.trn')
total = len(text_paths)
print(total)
with open(text_paths[0], 'r', encoding='utf8') as fr:
lines = fr.readlines
print(lines)
#数据集文件trn内容读取保存到数组中
texts =
paths =
for path in text_paths:
with open(path, 'r', encoding='utf8') as fr:
lines = fr.readlines
line = lines[0].strip('\n').replace(' ', '')
texts.append(line)
paths.append(path.rstrip('.trn'))
print(paths[0], texts[0])
#定义mfcc数
mfcc_dim = 13
#根据数据集标定的音素读入
def load_and_trim(path):
audio, sr = librosa.load(path)
energy = librosa.feature.rmse(audio)
frames = np.nonzero(energy >= np.max(energy) / 5)
indices = librosa.core.frames_to_samples(frames)[1]
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0]
return audio, sr
#提取音频特征并存储
features =
for i in tqdm(range(total)):
path = paths[i]
audio, sr = load_and_trim(path)
features.append(mfcc(audio, sr, numcep=mfcc_dim, nfft=551))
print(len(features), features[0].shape)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
2、神经网络预处理:
在进行神经网络加载训练前,我们需要对读取的MFCC特征进行归一化,主要目的是为了加快收敛,提高效果和减少干扰。然后处理好数据集和标签定义输入和输出即可。
对应代码如下:
#随机选择100个数据集
samples = random.sample(features, 100)
samples = np.vstack(samples)
#平均MFCC的值为了归一化处理
mfcc_mean = np.mean(samples, axis=0)
#计算标准差为了归一化
mfcc_std = np.std(samples, axis=0)
print(mfcc_mean)
print(mfcc_std)
#归一化特征
features = [(feature - mfcc_mean) / (mfcc_std + 1e-14) for feature in features]
#将数据集读入的标签和对应id存储列表
chars = {}
for text in texts:
for c in text:
chars[c] = chars.get(c, 0) + 1
chars = sorted(chars.items, key=lambda x: x[1], reverse=True)
chars = [char[0] for char in chars]
print(len(chars), chars[:100])
char2id = {c: i for i, c in enumerate(chars)}
id2char = {i: c for i, c in enumerate(chars)}
data_index = np.arange(total)
np.random.shuffle(data_index)
train_size = int(0.9 * total)
test_size = total - train_size
train_index = data_index[:train_size]
test_index = data_index[train_size:]
#神经网络输入和输出X,Y的读入数据集特征
X_train = [features[i] for i in train_index]
Y_train = [texts[i] for i in train_index]
X_test = [features[i] for i in test_index]
Y_test = [texts[i] for i in test_index]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
3、神经网络函数定义:
其中包括训练的批次,卷积层函数、标准化函数、激活层函数等等。
其中第⼀个维度为⼩⽚段的个数,原始语⾳越长,第⼀个维度也越⼤, 第⼆个维度为 MFCC 特征的维度。得到原始语⾳的数值表⽰后,就可以使⽤ WaveNet 实现。由于 MFCC 特征为⼀维序列,所以使⽤ Conv1D 进⾏卷积。 因果是指,卷积的输出只和当前位置之前的输⼊有关,即不使⽤未来的 特征,可以理解为将卷积的位置向前偏移。WaveNet 模型结构如下所⽰:
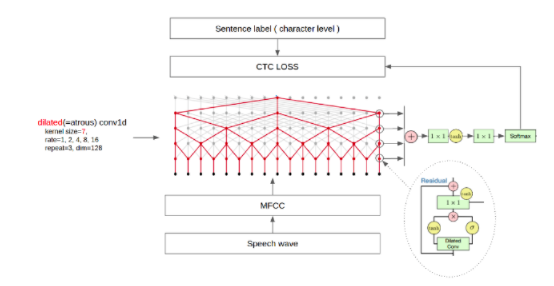
具体如下可见:
batch_size = 16
#定义训练批次的产生,一次训练16个
def batch_generator(x, y, batch_size=batch_size):
offset = 0
while True:
offset += batch_size
if offset == batch_size or offset >= len(x):
data_index = np.arange(len(x))
np.random.shuffle(data_index)
x = [x[i] for i in data_index]
y = [y[i] for i in data_index]
offset = batch_size
X_data = x[offset - batch_size: offset]
Y_data = y[offset - batch_size: offset]
X_maxlen = max([X_data[i].shape[0] for i in range(batch_size)])
Y_maxlen = max([len(Y_data[i]) for i in range(batch_size)])
X_batch = np.zeros([batch_size, X_maxlen, mfcc_dim])
Y_batch = np.ones([batch_size, Y_maxlen]) * len(char2id)
X_length = np.zeros([batch_size, 1], dtype='int32')
Y_length = np.zeros([batch_size, 1], dtype='int32')
for i in range(batch_size):
X_length[i, 0] = X_data[i].shape[0]
X_batch[i, :X_length[i, 0], :] = X_data[i]
Y_length[i, 0] = len(Y_data[i])
Y_batch[i, :Y_length[i, 0]] = [char2id[c] for c in Y_data[i]]
inputs = {'X': X_batch, 'Y': Y_batch, 'X_length': X_length, 'Y_length': Y_length}
outputs = {'ctc': np.zeros([batch_size])}
epochs = 50
num_blocks = 3
filters = 128
X = Input(shape=(None, mfcc_dim,), dtype='float32', name='X')
Y = Input(shape=(None,), dtype='float32', name='Y')
X_length = Input(shape=(1,), dtype='int32', name='X_length')
Y_length = Input(shape=(1,), dtype='int32', name='Y_length')
#卷积1层
def conv1d(inputs, filters, kernel_size, dilation_rate):
return Conv1D(filters=filters, kernel_size=kernel_size, strides=1, padding='causal', activation=None,
dilation_rate=dilation_rate)(inputs)
#标准化函数
def batchnorm(inputs):
return BatchNormalization(inputs)
#激活层函数
def activation(inputs, activation):
return Activation(activation)(inputs)
#全连接层函数
def res_block(inputs, filters, kernel_size, dilation_rate):
hf = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'tanh')
hg = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'sigmoid')
h0 = Multiply([hf, hg])
ha = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')
hs = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')
return Add([ha, inputs]), hs
h0 = activation(batchnorm(conv1d(X, filters, 1, 1)), 'tanh')
shortcut =
for i in range(num_blocks):
for r in [1, 2, 4, 8, 16]:
h0, s = res_block(h0, filters, 7, r)
shortcut.append(s)
h1 = activation(Add(shortcut), 'relu')
h1 = activation(batchnorm(conv1d(h1, filters, 1, 1)), 'relu')
#softmax损失函数输出结果
Y_pred = activation(batchnorm(conv1d(h1, len(char2id) + 1, 1, 1)), 'softmax')
sub_model = Model(inputs=X, outputs=Y_pred)
#计算损失函数
def calc_ctc_loss(args):
y, yp, ypl, yl = args
return K.ctc_batch_cost(y, yp, ypl, yl)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
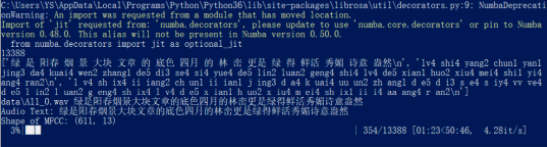
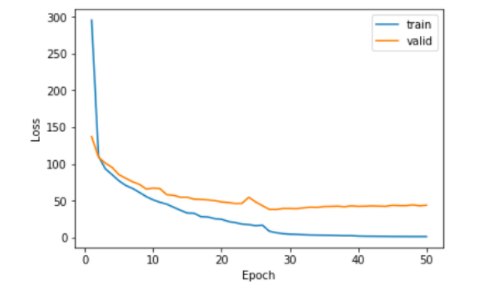
4、模型的训练:
训练的过程如下可见:
ctc_loss = Lambda(calc_ctc_loss, output_shape=(1,), name='ctc')([Y, Y_pred, X_length, Y_length])
#加载模型训练
model = Model(inputs=[X, Y, X_length, Y_length], outputs=ctc_loss)
#建立优化器
optimizer = SGD(lr=0.02, momentum=0.9, nesterov=True, clipnorm=5)
#激活模型开始计算
model.compile(loss={'ctc': lambda ctc_true, ctc_pred: ctc_pred}, optimizer=optimizer)
checkpointer = ModelCheckpoint(filepath='asr.h5', verbose=0)
lr_decay = ReduceLROnPlateau(monitor='loss', factor=0.2, patience=1, min_lr=0.000)
#开始训练
history = model.fit_generator(
generator=batch_generator(X_train, Y_train),
steps_per_epoch=len(X_train) // batch_size,
epochs=epochs,
validation_data=batch_generator(X_test, Y_test),
validation_steps=len(X_test) // batch_size,
callbacks=[checkpointer, lr_decay])
#保存模型
sub_model.save('asr.h5')
#将字保存在pl=pkl中
with open('dictionary.pkl', 'wb') as fw:
pickle.dump([char2id, id2char, mfcc_mean, mfcc_std], fw)
train_loss = history.history['loss']
valid_loss = history.history['val_loss']
plt.plot(np.linspace(1, epochs, epochs), train_loss, label='train')
plt.plot(np.linspace(1, epochs, epochs), valid_loss, label='valid')
plt.legend(loc='upper right')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
测试模型
读取我们语音数据集生成的字典,通过调用模型来对音频特征识别。
代码如下:
wavs = glob.glob('A2_103.wav')
print(wavs)
with open('dictionary.pkl', 'rb') as fr:
[char2id, id2char, mfcc_mean, mfcc_std] = pickle.load(fr)
mfcc_dim = 13
model = load_model('asr.h5')
index = np.random.randint(len(wavs))
print(wavs[index])
audio, sr = librosa.load(wavs[index])
energy = librosa.feature.rmse(audio)
frames = np.nonzero(energy >= np.max(energy) / 5)
indices = librosa.core.frames_to_samples(frames)[1]
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0]
X_data = mfcc(audio, sr, numcep=mfcc_dim, nfft=551)
X_data = (X_data - mfcc_mean) / (mfcc_std + 1e-14)
print(X_data.shape)
pred = model.predict(np.expand_dims(X_data, axis=0))
pred_ids = K.eval(K.ctc_decode(pred, [X_data.shape[0]], greedy=False, beam_width=10, top_paths=1)[0][0])
pred_ids = pred_ids.flatten.tolist
print(''.join([id2char[i] for i in pred_ids]))
yield (inputs, outputs)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
到这里,我们整体的程序就搭建完成,下面为我们程序的运行结果:

源码地址:
https://pan.baidu.com/s/1tFlZkMJmrMTD05cd_zxmAg
提取码:ndrr
数据集需要自行下载。