本文主要是详细介绍一下跨域推荐,包含但不局限于以下几个部分:
-
迁移学习
-
跨域推荐
-
跨域推荐可以怎么做
-
冷启动的其他一些方法
-
-
可以参考的论文有哪些
1. 迁移学习
以下内容参考【推荐系统中的多任务学习-卢明冬】进行修改和介绍,更多详细内容可以阅读:https://lumingdong.cn/multi-task-learning-in-recommendation-system.html。
1.1 迁移学习介绍
迁移学习(Transfer Learning,TL)**是属于机器学习的一种研究领域。它专注于存储已有问题的解决模型,并将其利用在其他不同但相关问题上。比如说,用来辨识汽车的知识(或者是模型)也可以被用来提升识别卡车的能力。
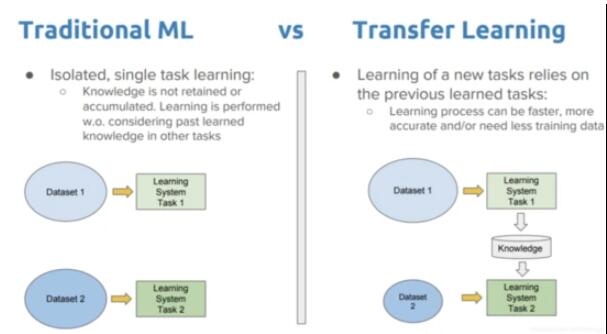
ML vs TL
迁移学习设计用于解决这些相互隔离的学习方式,可以利用先前训练模型中的知识(即特征,权重等)训练新的模型,实现从其它任务获取的知识去解决相关的问题,甚至可以解决诸如新任务具有较少数据等问题。
1.2 迁移学习可以解决哪些问题
-
大数据与少标注的矛盾:虽然有大量的数据,但很多都是没有标签的,这些数据应用无监督模型会比较好,但是当使用有监督模型时就不太友好了,而如果选择人工标注则会耗时耗力
-
大数据与弱计算的矛盾:普通人无法拥有庞大的数据量与计算资源。因此需要借助于模型的迁移,比如图像识别中进行对训练好的模型进行 fine-tuning 完成自己的任务
-
普适化模型与个性化需求的矛盾:即使是在同一个任务上,一个模型也往往难以满足每个人的个性化需求,比如特定的隐私设置。这就需要在不同人之间做模型的适配
-
特定应用(如冷启动)的需求
迁移学习中还有三个比较重要的问题,即:
-
迁移什么(What To Transfer):如何选择我们的先验知识进行迁移,并不是所有的源域都可以迁移到目标域,比如说一个文本分类的经验知识迁移到图像分类上显然是不合适的,因此在选定迁移的源域和目标域时一定要判断两者有相关性,不论是用户还是item
-
何时迁移(When To Transfer):什么时候可以进行迁移,什么时候不能迁移?在某些场景中,迁移知识可能要比改进知识更糟糕(该问题也称为 “负迁移”)。我们的目标是通过迁移学习改善目标任务的性能或结果,而不是降低它们。(避免负迁移)
-
如何迁移(How To Transter):如何进行迁移学习?我们需要确定跨域或跨任务实现知识实际迁移的方法。该问题涉及如何改进现有的算法和各种技术(设计迁移方法)
1.3 迁移学习基本概念
迁移学习中有两个很重要的概念:域(domain)和任务(Task)。
域:数据特征和特征分布组成,是学习的主体
-
源域 (Source domain):已有知识的域
-
目标域 (Target domain):要进行学习的域
任务:由目标函数和学习结果组成,是学习的结果
域的不同有两种可能的场景:
-
特征空间不同
例如文本分类任务中,中文文本和英文文本的特征空间不同
图像识别任务中,人脸图片和鸟类图片的特征空间不同
-
边缘概率分布不同
例如文本分类任务中,文本都是中文语言的特征空间,但讨论的是不同的主题,如政治和娱乐
图片识别任务中,图片都是鸟类的特征空间,但一个是在城市中拍到的鸟,一个是在大自然中拍到的
任务的不同也有两种可能的场景:
-
标签空间不同
例如在文本分类任务中,一个标签是新闻类别标签,一个标签是文本情感标签;
人脸识别任务中,一个标签是性别,一个标签是人名。
-
条件概率不同
例如源和目标数据类别分布不均衡。这种情况非常普遍,可用过采样(over-sampling)、欠采样(under-sampling)、SMOTE 等方法进行处理。
一般标签不同,条件概率分布也会不同,因为很少会出现两个不同的任务有不同的标签空间而条件概率分布完全相同的情况。
也有论文将域(domain)和 任务(task)合二为一称之为一个 dataset,cross-dataset 指的就是 domain 或者 task 不同
1.4 迁移学习分类
按特征空间分
-
同构迁移学习(Homogeneous TL): 源域和目标域的特征空间相同
-
异构迁移学习(Heterogeneous TL):源域和目标域的特征空间不同
按迁移情景分
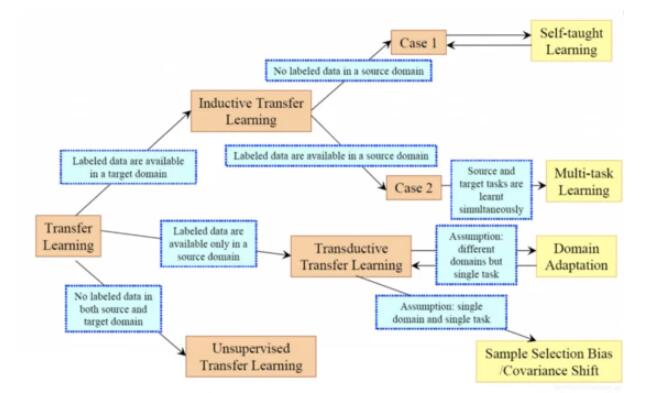
参考上图,根据所使用的传统机器学习算法,迁移学习方法可分类为:
-
归纳式迁移学习(Inductive Transfer learning):在该场景中,源域和目标域相同,但源任务和目标任务彼此不同。算法尝试利用来自源域的归纳偏差帮助改进目标任务。根据源域中是否包含标记数据,归纳式迁移学习可以进一步分为类似于**多任务学习(Multi-task Learning) 和 自学习(Self-taught Learning)**这两类方法
-
直推式迁移学习(Transductive Transfer Learning):源域和目标域不同,学习任务相同。在该场景中,源任务和目标任务之间存在一些相似之处,但相应的域不同。通常源域具有大量标记数据,而目标域没有。根据特征空间或边缘概率的设置不同,直推式迁移学习可进一步分类为多个子类
-
无监督迁移学习(Unsupervised Transfer Learning):源域和目标域均没有标签。该场景类似于归纳式迁移学习,重点关注目标域中的无监督任务
下表总结了上述迁移学习策略在不同场景和领域下的对比:

-
基于样本的迁移学习(Instance transfer):通常,理想场景是源域中的知识可重用到目标任务。但是在大多数情况下,源域数据是不能直接重用的。然而,源域中的某些实例是可以与目标数据一起重用,达到改善结果的目的。对于归纳式迁移,已有一些研究利用来自源域的训练实例来改进目标任务,例如 Dai 及其合作研究者对 AdaBoost 的改进工作
-
基于特征表示的迁移学习(Feature-representation transfer): 该类方法旨在通过识别可以从源域应用于目标域的良好特征表示,实现域差异最小化,并降低错误率。根据标记数据的可用性情况,基于特征表示的迁移可采用有监督学习或无监督学习
-
基于参数的迁移学习(Parameter transfer): 该类方法基于如下假设:针对相关任务的模型间共享部分参数,或超参数的先验分布。不同于同时学习源和目标任务的多任务学习,在迁移学习中我们可以对目标域的应用额外的权重以提高整体性能
-
基于关系知识的迁移学习(Relational-knowledge transfer): 与前面三类方法不同,基于关系知识的迁移意在处理非独立同分布(i.i.d)数据即每个数据点均与其他数据点存在关联。例如,社交网络数据就需要采用基于关系知识的迁移学习技术
下表清晰地总结了不同迁移内容分类和不同迁移学习策略间关系:

OK上边的便是关于迁移学习的介绍了,相信你读完之后会有自己的理解!
2. 跨域推荐
那什么是跨域推荐呢?一句话概括就是:当迁移学习应用到推荐系统中时就被称为跨域推荐(Cross-Domain Recommendation)。
跨域推荐的目的一般是有下面几个:
-
冷启动:比如一个公司的两个APP业务,用户群体交叉很大,但是item不同,当A业务的用户首次来访B业务时,如何做出有效的推荐,从而提升留存、转化率,跨域推荐为冷启动提供了一种新的思路,但其局限性也很强,对于一些一个公司只有一个业务的场景是很难适用的
-
跳出信息茧房:基于同业务的推荐,往往会让用户的兴趣越变越窄,因为都是基于用户的行为进行挖掘的,当使用跨域推荐时可以跳出原先的舒适圈,从而改善推荐系统的平衡性、多样性和新奇性
-
减少数据稀疏性,提高准确度:同样是针对两个不同业务场景而言的,新业务或者其中一个业务由于某些原因数据比较稀疏,通过引入跨域推荐,丰富数据
-
强化用户偏好:新用户的偏好是很弱的,通过跨域推荐强化用户偏好
3.跨域推荐可以怎么做
3.1 基于频繁模式挖掘
获取用户在域A和域B中的共现行为,构造共现pair对 <itemA, itemB>,当其共现次数大于某个值时,认为其有效,最终可以得到域A中item的“相似”域B中的item list
或者计算itemA与itemB的相关性,计算公式为:
其中:
-
为物品的共现次数,为对物品有行为的用户数,为对物品有行为的用户数
-
表示总的用户数
3.2 簇类热门
-
获取域A item的embedding,userID的embedding向量则由用户最近行为的item序列的平均得到
-
对域A的用户进行聚类,得到每个簇类的top 热门
-
用户访问域B时 推荐其所在簇类下的热门
这里不一定使用embedding进行聚类,也可以根据属性进行聚类
3.3 基于属性标签映射
通过源域的属性标签和目标域的属性标签在用户访问序列的共现,构建属性映射,有两种方法:
-
基于统计的方法,计算源域属性和目标域属性的相关性
-
word2vec,通过属性序列,生成属性的embedding
例如,用户的属性点击序列数据为
-
user1: cate1, cate2, cate2, tag1, cate2, tag2,...
-
user1: cate3, cate4, tag1, cate2, tag3,...
基于统计的方法计算
统计包含(cate1,tag1)(cate2,tag2)(cate3,tag1)....的用户数作为分子
统计包含cate1,cate2,....,tag1,tag2的用户数作为分母,计算相关性
基于word2vec的方式
基于word2vec、skip-gram的方式,按天划分session,计算得到cate和tag的embedding
3.4 基于FM
可以参考论文:2014_Cross-Domain Collaborative Filtering with Factorization Machines
这个后期会单独出一篇文章来介绍其原理和实战应用!欢迎关注!
3.5 基于隐因子映射
参考论文:Cross-Domain Recommendation: An Embedding and Mapping Approach
-
分别构建源域和目标域的user、item embedding
-
构建源域和目标域 user embedding的映射函数 f
-
使用映射函数f将源域中的user embedding表示成 目标域中的user embedding,然后根据 embedding相似进行召回
参考文章: 论文|一种基于Embedding和Mapping的跨域推荐方法
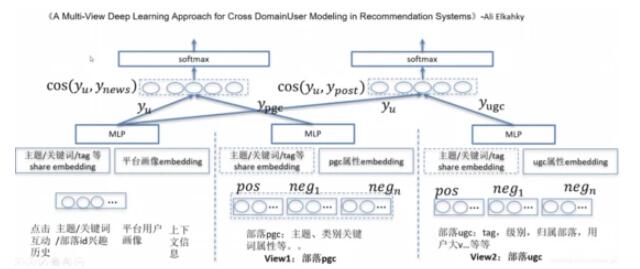
3.6 基于DNN
4.参考的论文有哪些
跨域推荐在业界被关注的比较多,发表的论文也很多,这里列举了一些比较经典的论文,可以在公众号回复【跨域推荐论文】获取。
-
2014_Cross-Domain Collaborative Filtering with Factorization Machines
-
2015_Cross-domain recommendation without shared users or items by sharing latent vector distributions
-
2016_A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
-
2016_WRAP-connecting-social-media-e-commerce-He-2018
-
2017_CCCFNet- A Content-Boosted Collaborative Filtering Neural Network for Cross Domain Recommender Systems
-
2017_Cross-Domain Recommendation via Clustering on Multi-Layer Graphs
-
2017_Cross-Domain Recommendation- An Embedding and Mapping Approach
-
2018_Cross-Domain Recommendation for Cold-Start Users via Neighborhood Based Feature Mapping
-
2018_Cross-domain Recommendation via Deep Domain Adaptation
-
2019_DDTCDR- Deep Dual Transfer Cross Domain Recommendation
-
2019_Easy Transfer Learning by Exploiting Intar-domain Structures
-
2019_Transfer Learning with Domain-aware Attention Network for Item Recommendation in E-commerce
-
2020_MiNet- Mixed Interest Network for Cross-Domain Click-Through Rate Prediction
5. 参考
-
https://lumingdong.cn/multi-task-learning-in-recommendation-system.html#%E8%BF%81%E7%A7%BB%E5%AD%A6%E4%B9%A0
-
https://xmzzyo.github.io/2020/04/12/Cross-domain-Recommendation/