最近做了一个集群服务的在线切换,将原来的主从环境做了切换,当然后端的处理工作是比较复杂的,涉及到主从服务器的在线迁移和硬件变更。
总体来说,切换后的读延迟比原本降低了0.4毫秒左右,对于一个延迟季度敏感的业务来说,0.4毫秒是一个很高的比例,按照既定的比例规则,差不多是优化了25-30%的比例。
那么这省下来的0.4毫秒到底优化在哪个环节了呢?我们做了一些讨论和分析,不仅暗暗感叹,幸亏是优化了,如果延迟变大30%,要快速分析还是压力很大的。
这个问题分析的难点在于存在一系列的动态变量,导致服务切换前后的对比缺少了一些基准和衡量标准。
我们简单提炼了下,在服务切换前的优化工作有:
1)新从库采用了全新的硬件配置,CPU型号更高,性能提升可达30%
2)主从库采用的SATA-SSD的存储使用了不同品牌
3)主从切换前,在从库中对数据表进行了全面的碎片清理
4)原本服务器的系统盘是使用SAS的,在新从库中统一按照SATA-SSD类配置
5)中间件服务器有近2年没有重启过,这次维护做了重启维护
此外,还有一些不确定的因素,比如业务量的差异等,按照100%对等的标准是不大可能完全对等去分析的,所以我们试着通过如下的逻辑进行分析。
初步来看,我们觉得对于数据表做了碎片清理,这个改进的效果会比较高,因为碎片率在切换前统计是近20%,清理后空间释放了近20%,本来认为这样的一套指标体系是比较演进的,但是在对比了近几天的业务延迟情况之后,有一个业务的数据是说不通的。
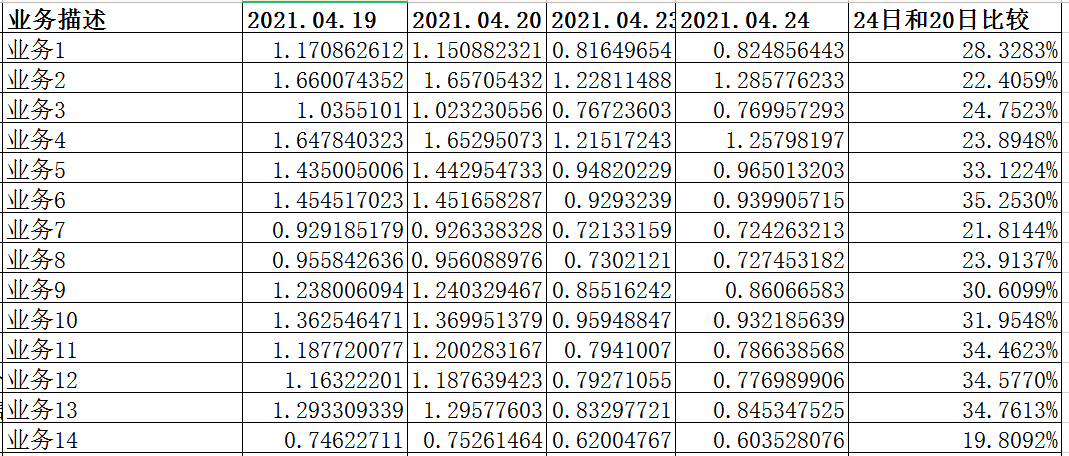
我们假设是业务2,业务2的数据表示日表,也就意味着这张表没有所谓的碎片,因为每天都会有一张新的数据表写入数据。所以业务2的延迟应该没有变化或者有细小的差异才说得通,但是在这里可以很清楚的看到,延迟是有近30%的提升,这就说不通了,所以单纯的碎片清理带来的收益确实没有期望那么高。
我们分析下系统负载的情况,随机选择了一个分片节点,查看了切换前和切换后的负载数据。
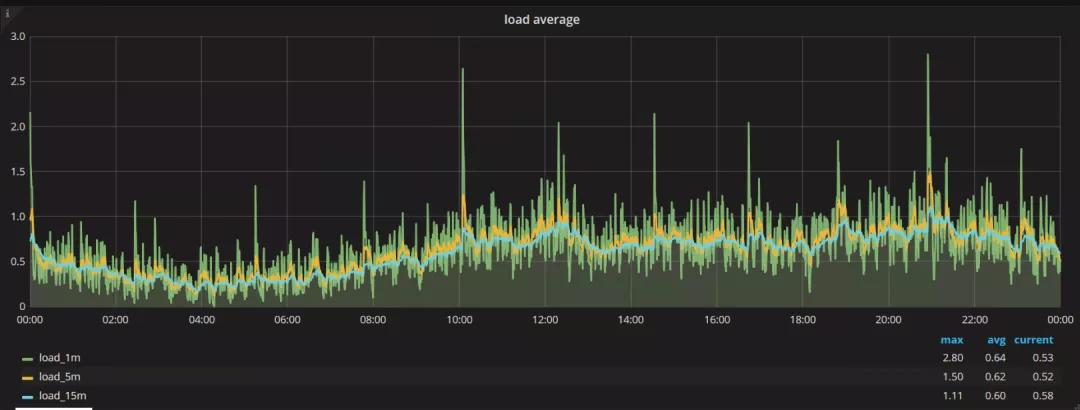
切换前
切换后
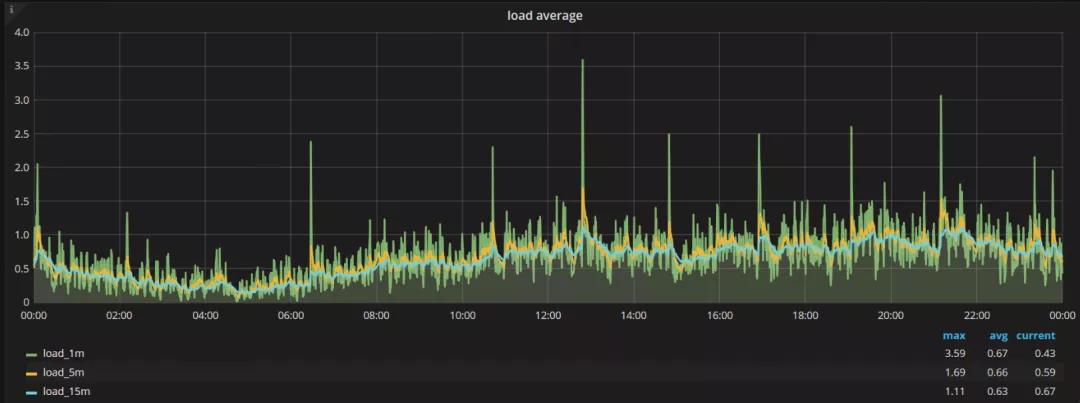
总体来说,负载的平均值是提高了0.03,这个比例是很低的一个比例,姑且认为是可以忽略的。
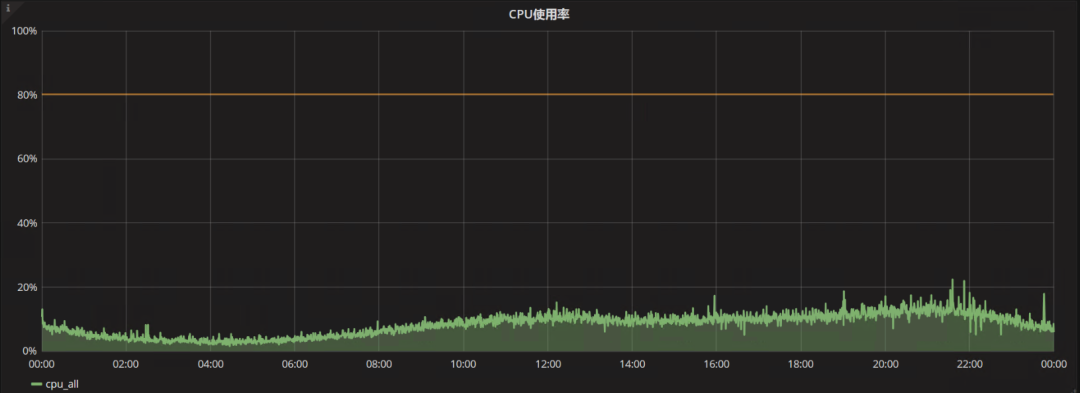
再来看看CPU的使用率,因为新的服务器CPU性能提升近30%,所以对负载情况进行了整体的比对,可以发现这个业务不是强计算相关的,所以CPU配置再好,在这里带来的收益确实没有期望那么明显。
切换后
切换前
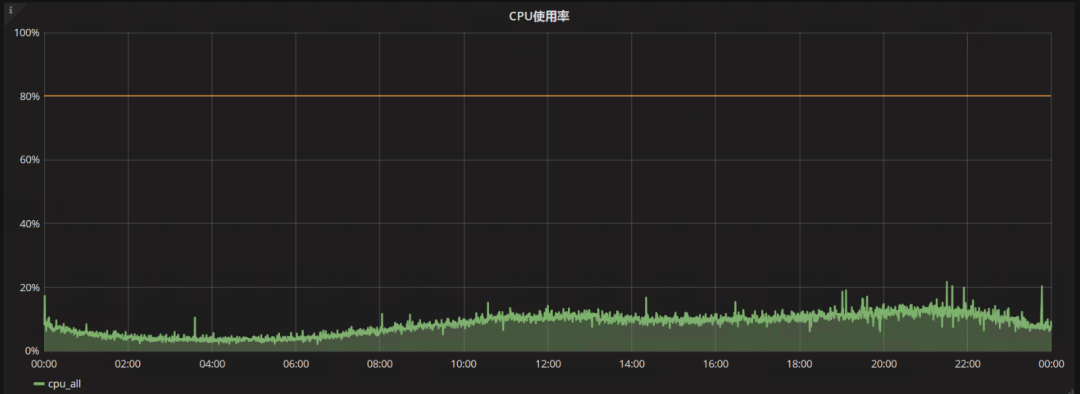
接着来看磁盘,磁盘层面有很多的指标,我们来看下util指标:
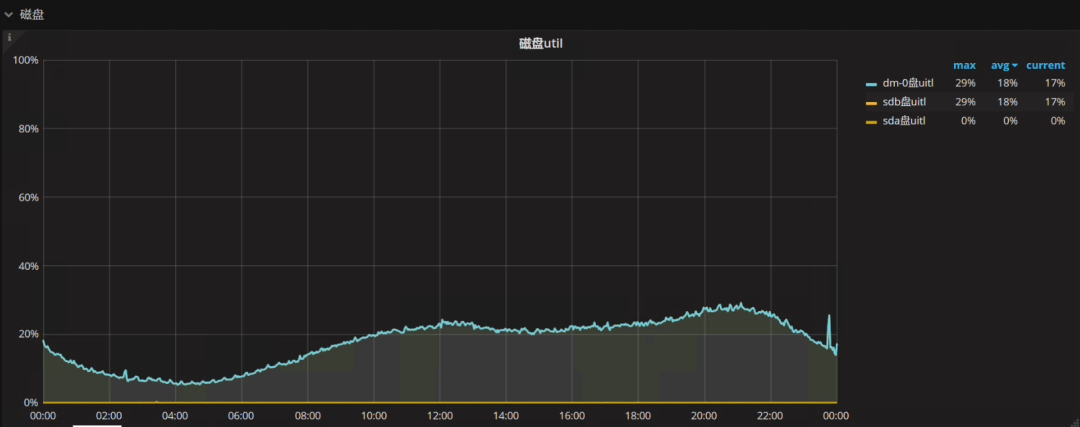
切换后:
切换前:
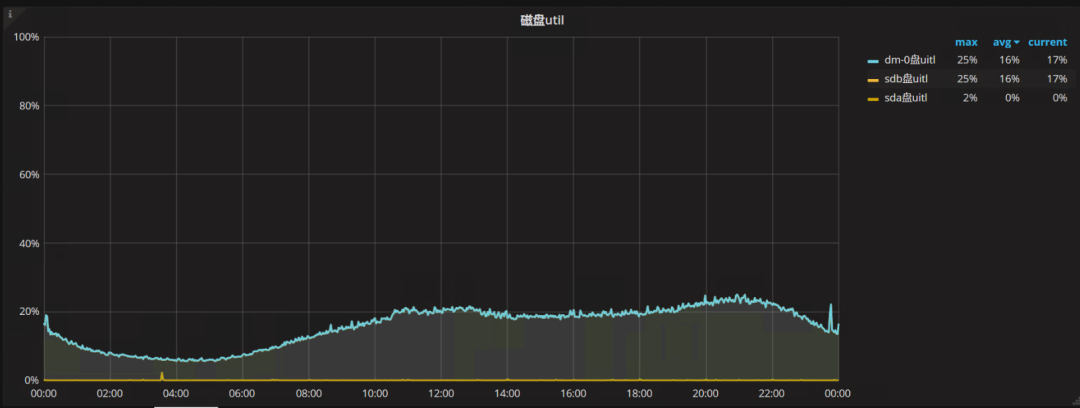
总体切换后的util从16%提高到了18%,很难可以给出一个客观的结论。
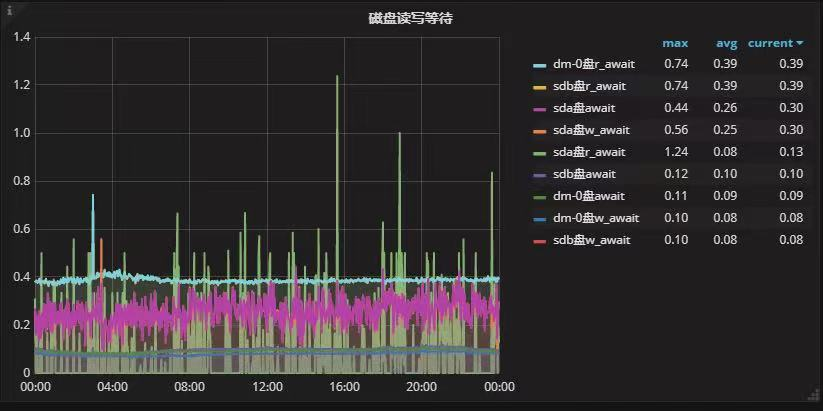
对于磁盘读写层面的分析,可以看到等待的延迟部分不是一个数量级。
切换后
切换前
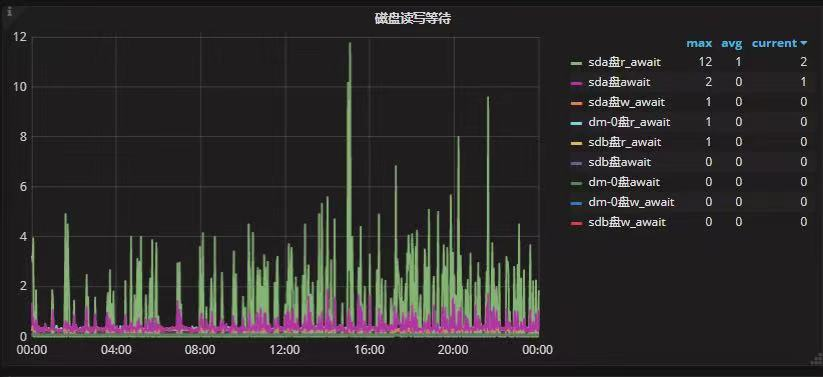
在这里可能会有一个误区,那就是切换前的指标是精确度不够,是0,我们可把指标放大,即选择其中一个指标,就可以看到右侧的指标的相对精确的数据了。
切换后:
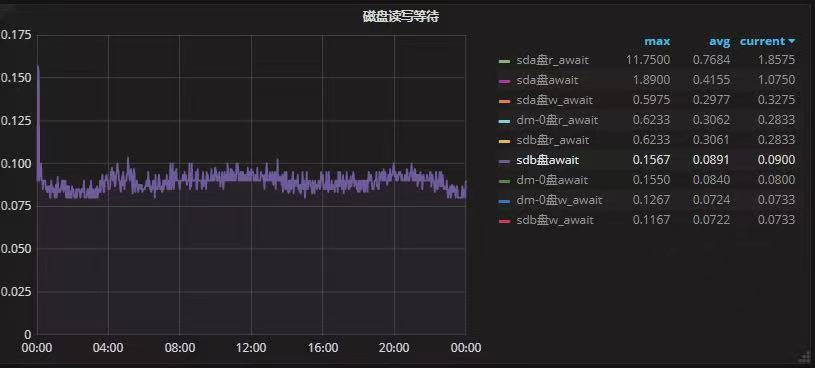
切换前:
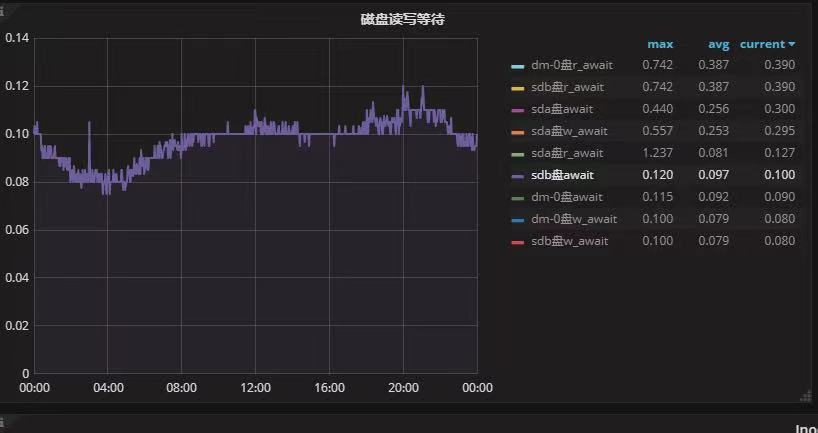
到了这里,我们可以看到延迟的指标对于逻辑卷和不同分区的差别还是很明显的,虽然单个指标的提升在10%左右,但是所有的指标都是略高一筹。
当然碎片整理确实是有提高,但是和磁盘层面的提升来说,占比确实没有那么高。
而接下来的问题就是进一步验证,需要分析不同SSD产品间的一些差异和稳定性测试数据。
总体来说,整个分析的过程可以提供一种分析的思路,而不仅仅是得到的初步结论。
本文转载自微信公众号「杨建荣的学习笔记」,可以通过以下二维码关注。转载本文请联系+杨建荣的学习笔记公众号。