












本文转载自微信公众号「小姐姐味道」,作者小姐姐养的狗02号 。转载本文请联系小姐姐味道公众号。
今天总监很生气,原因是强调了很多年的缓存同步方案,硬是有人不按常理出牌,挑战权威。最终出了问题,这让总监很没面子。
"一群人拿着大老板的账号在哪里瞎测,结果把数据搞出问题来了吧",总监牛鼻子里喷着气,叉着腰说。自从老板的账号有一次参与测试之后,就成了大家心照不宣的终极测试账号。很多人用,硬生生把一个账号的余额操作,给搞成了高并发的。
"老板的账号不就是个测试账号么...",下面有人小声的嘀咕。
"现实中哪会有账号有这样的密集型操作的...",又有人小声嘀咕,让总监的脸色越来越沉。
"你们觉得我在开玩笑么?",总监红着眼说,“我就曾经因为这样的数据不一致问题,吃过一个一级故障。正好,今天就带你们了解一下,为什么会有数据不一致的情况吧”。
我扶着眼镜摇摇晃晃的做到台下,心中暗笑,总监又要把Cache Aside Pattern给科普一遍了。
1. 为什么数据会不一致?
数据库的瓶颈是大家有目共睹的,高并发的环境下,很容易I/O锁死。当务之急,就是把常用的数据,给捞到速度更快的存储里去。这个更快的存储,就有可能是分布式的,比如Redis,也有可能是单机的,比如Caffeine。
但一旦加入缓存,就不得不面对一个蛋疼的问题:数据的一致性。
数据不一致的问题,人世间多了去了。进修过Java多线程的同学,肯定会对JMM的模型记忆犹新。一个数值,只要同时在两个地方存储,那就会产生问题。
但缓存系统和数据库,比JMM更加的不可靠。因为分布式组件更加的脆弱,它随时都可能发生问题。
2. Cache Aside Pattern
怎样保证数据在DB和缓存中的一致性呢?现在一个比较好的最佳实践方案,就是Cache Aside Pattern。
先来看一下数据的读取过程,规则是:先读cache,再读db 。详细步骤如下:
- 每次读取数据,都从cache里读
- 如果读到了,则直接返回,称作 cache hit
- 如果读不到cache的数据,则从db里面捞一份,称作cache miss
- 将读取到的数据,塞入到缓存中,下次读取的时候,就可以直接命中
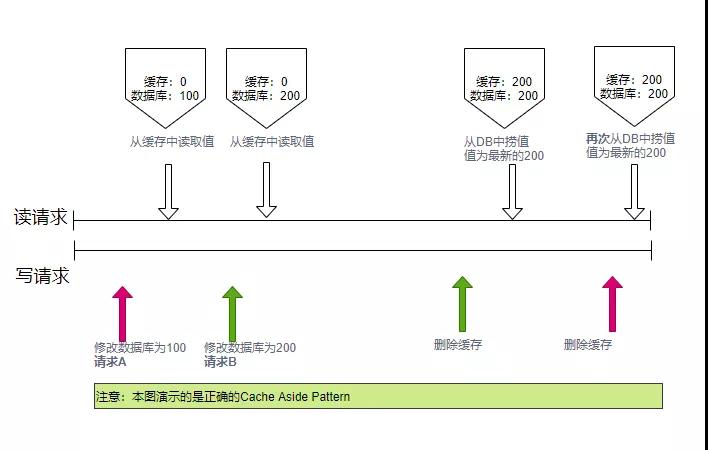
再来看一下写请求。规则是:先更新db,再删除缓存 。详细步骤如下:
- 将变更写入到数据库中
- 删除缓存里对应的数据
说到这里,我看着有几个人皱起了眉头。我知道,肯定会有人不服气,认为自己那一套是对的。比如,为什么是删除缓存,不是更新缓存呢?效率会不会更低?为什么不先删除缓存再更新数据库?
好家伙,他们要向总监发问了。
3. 为什么是删除缓存,而不是更新缓存?
这个比较好理解。当多个更新操作同时到来的时候,删除动作,产生的结果是确定的;而更新操作,则可能会产生不同的结果。
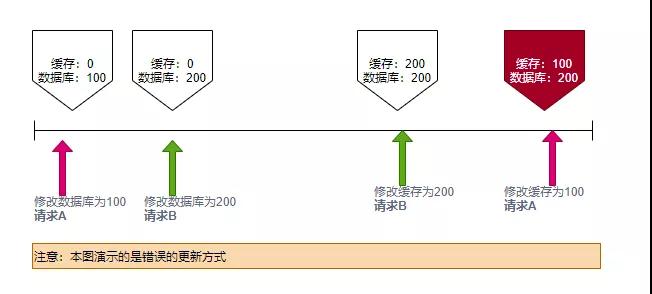
如图。两个请求A和B,请求B在请求A之后,数据是最新的。由于缓存的存在,如果在保存的时许发生稍许的偏差,就会造成A的缓存值覆盖了B的值,那么数据库中的记录值,和缓存中的就产生了不一致,直到下一次数据变更。
而使用删除的方式,由于缓存会miss,所以会每次都会从db中获取最新的数据进行填充,与缓存操作的时机关系不大。
4. 为什么不先删缓存,再更新数据库?
这个问题是类似的。我们甚至都不需要并发写的场景就能发现问题。
我们上面提到的缓存删除动作,和数据库的更新动作,明显是不在一个事务里的。如果一个请求删除了缓存,同时有另外一个请求到来,此时发现没有相关的缓存项,就从数据库里加载了一份到缓存系统。接下来,数据库的更新操作也完成了,此时数据库的内容和缓存里的内容,就产生了不一致。
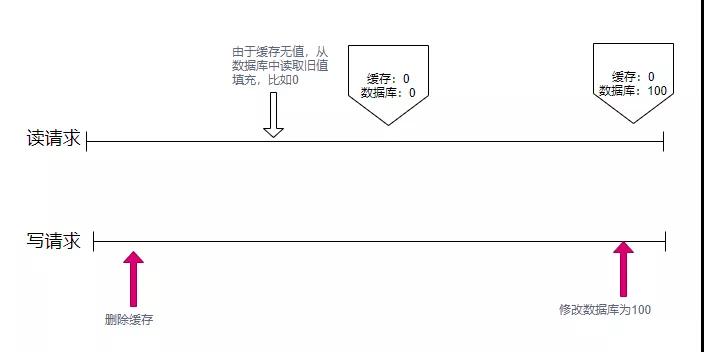
如上图,写请求首先删除了缓存。结果在这个时候,有其他的读请求,将数据库的旧值,读取到数据库中,此时缓存中的数据是0。接下来更新了DB,将数据库记录改为了100。经过这么一哆嗦,数据库和缓存中的数据,就产生了不一致。
大家都恍然大悟的点点头,不少人露出了迷之微笑。
5. Spring中的缓存注解
使用 SpringBoot 可以很容易地对 Redis 进行操作,Java 的 Redis的客户端,常用的有三个:jedis、redisson 和 lettuce,Spring 默认使用的是 lettuce。
很多人,喜欢使用Spring 抽象的缓存包 spring-cache。
它使用注解,采用 AOP的方式,对 Cache 层进行了抽象,可以在各种堆内缓存框架和分布式框架之间进行切换。这是它的 maven 坐标:
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-cache</artifactId>
- </dependency>
使用 spring-cache 有三个步骤:
- 在启动类上加入 @EnableCaching 注解;
- 使用 CacheManager 初始化要使用的缓存框架,使用 @CacheConfig 注解注入要使用的资源;
- 使用 @Cacheable 等注解对资源进行缓存。
而针对缓存操作的注解,有三个:
- @Cacheable 表示如果缓存系统里没有这个数值,就将方法的返回值缓存起来;
- @CachePut 表示每次执行该方法,都把返回值缓存起来;
- @CacheEvict 表示执行方法的时候,清除某些缓存值。
那么问题来了,spring-cache中的@CacheEvict注解,到底是先删缓存,还是后删缓存呢?不弄明白这一点,真的是让人夜不能寐。关键技术嘛,不仅要用的开心,也要用的放心。
缓存的移除,是在CacheAspectSupport中实现的,我们注意到下面的代码。
- // Process any early evictions
- processCacheEvicts(contexts.get(CacheEvictOperation.class), true,
- CacheOperationExpressionEvaluator.NO_RESULT);
- ...
- // Process any late evictions
- processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue);
它有一个前置的清除动作,还有后置的清除动作,是通过一个bool变量boolean beforeInvocation进行设置的。这个值从哪里来的呢?还是得看@CacheEvict注解。
- /**
- * Whether the eviction should occur before the method is invoked.
- * <p>Setting this attribute to {@code true}, causes the eviction to
- * occur irrespective of the method outcome (i.e., whether it threw an
- * exception or not).
- * <p>Defaults to {@code false}, meaning that the cache eviction operation
- * will occur <em>after</em> the advised method is invoked successfully (i.e.,
- * only if the invocation did not throw an exception).
- */
- boolean beforeInvocation() default false;
很好很好,它的默认值是false,证明删除动作是滞后的,践行的也是Cache Aside Pattern。
6. 还有其他模式?
我听说,还有Read Through Pattern,Write Through Pattern,Write Behind Caching Pattern等其他常见的缓存同步模式,为什么不用这些呢? 有位同学的屁股一直在椅子上来回挪动,跃跃欲试,逮住机会,他终于发言了。
其实,这些方式使用的也非常广泛,但由于对业务大多数是无感知的,所以很多人都忽略了。换句话说,这几个模式,大多数是在一些中间件,或者比较底层的数据库中实现的,写业务代码可能接触不到这些东西。
比如,Read Through,其实就是让你对读操作感知不到缓存层的存在。通常情况下,你会手动实现缓存的载入,但Read Through可能就有代理层给你捎带着做了。
再比如,Write Through,你不用再考虑数据库和缓存是不是同步了,代理层都给你做了,你只管往里塞数据就行。
Read Through和Write Through是不冲突的,它们可以同时存在,这样业务层的代码里就没有同步这个概念了。爽歪歪。
至于Write Behind Caching,意思就是先落地到缓存,然后有异步线程缓慢的将缓存中的数据落地到DB中。要用这个东西,你得评估一下你的数据是否可以丢失,以及你的缓存容量是否能够经得起业务高峰的考验。现在的操作系统、DB、甚至消息队列如Kafaka等,都会在一定程度上践行这个模式。
但它现在和我们的业务需求没半点关系。
7. Cache Aside Pattern也有问题
总监上马,一个顶俩,科普了这半天,所有的同学都心服口服。正在大家想要把掌声送给总监的时候,一个不和谐的声音传来了。
我发现了一个天大的问题。 有同学说, 如果数据库更新成功了,但缓存删除失败了,也会造成缓存不一致。
这个问题问的好啊,故障大多数就是由于这些极端情况造成的。这个时候就有意思了,我们要拼概率,毕竟没有100%的安全套。 总监笑了。
方法一:将数据更新和缓存删除动作,放在一个事务里,同进退。
方法二:缓存删除动作失败后,重试一定的次数。如果还是不行,大概率是缓存服务的故障,这时候要记录日志,在缓存服务恢复正常的时候将这些key删除掉
方法三:再多一步操作,先删缓存,再更新数据,再删缓存。这样虽然操作多一些,但也更保险一些。
是不是没有问题了? 总监环顾四周,看到大家都在点头。No no no,依然还有数据不一致的情况。
所有人都一头雾水。
上面那张看起来正确的图,其实是错误的。为什么呢?因为数据在从数据库读到缓存中的操作,并不是原子性的。
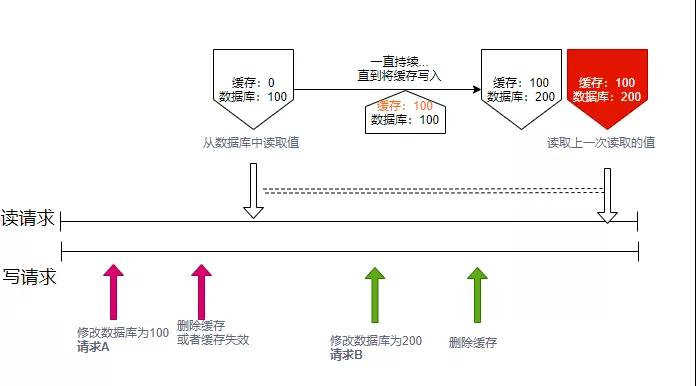
比如上图,当缓存失效(或者被删除)的时候,有一个读请求正好到来。这个读请求,拿到了旧的数据库值,但它由于多方面的原因(比如网络抽风),没有立马写入到缓存中,而是发生了延迟。在它打算写入到缓存的这段时间,发生了很多事情,有另外一个请求,将数据库的值更新为200,并删除了缓存。
直到第二个请求全部完成,第一个请求写入缓存的操作,才真正落地。但其实,这时候数据库和缓存的值,已经不是同步的了。
那么为什么大家在平常的设计中,几乎把这个场景给忽略掉了呢?因为它发生的概率实在太低了。它要求在读取数据的时候,有两个或者多个并发写操作(或者发生了数据失效),这在实际的应用场景中实在是太少了。而且,我们要注意虚线所持续的周期,是一个数据库的更新操作,加上一个cache的删除操作,这个操作一般情况下,也会比缓存的设置持续的时间长,所以进一步降低了概率。
所以,你们知道正确的操作方式了么? 总监问。
知道了!以后我们就用spring-cache的注解去完成工作,再也不在代码中手写一致性逻辑了。
很好很好,如果这么做的话,再发生问题,好像可以把锅甩给spring团队了呢。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。

















