在异地多活的实现上,数据能够在三个及以上中心间进行双向同步,才是解决真正异地多活的核心技术所在。本文基于三中心且跨海外的场景,分享一种多中心容灾架构及实现方式,介绍几种分布式ID生成算法,以及在数据同步上最终一致性的实现过程。
一、背景
为什么称之为真正的异地多活?异地多活已经不是什么新鲜词,但似乎一直都没有实现真正意义上的异地多活。一般有两种形式:一种是应用部署在同城两地或多地,数据库一写多读(主要是为了保证数据一致性),当主写库挂掉,再切换到备库上;另一种是单元化服务,各个单元的数据并不是全量数据,一个单元挂掉,并不能切换到其他单元。目前还能看到双中心的形式,两个中心都是全量数据,但双跟多还是有很大差距的,这里其实主要受限于数据同步能力,数据能够在3个及以上中心间进行双向同步,才是解决真正异地多活的核心技术所在。
提到数据同步,这里不得不提一下DTS(Data Transmission Service),最初阿里的DTS并没有双向同步的能力,后来有了云上版本后,也只限于两个数据库之间的双向同步,做不到A-B-C这种形式,所以我们自研了数据同步组件,虽然不想重复造轮子,但也是没办法,后面会介绍一些实现细节。
再谈谈为什么要做多中心容灾,以我所在的CDN&视频云团队为例,首先是海外业务的需要,为了能够让海外用户就近访问我们的服务,我们需要提供一个海外中心。但大多数业务还都是以国内为主的,所以国内要建双中心,防止核心库挂掉整个管控就都挂掉了。同时海外的环境比较复杂,一旦海外中心挂掉了,还可以用国内中心顶上。国内的双中心还有个非常大的好处是可以通过一些路由策略,分散单中心系统的压力。这种三个中心且跨海外的场景,应该是目前异地多活最难实现的了。
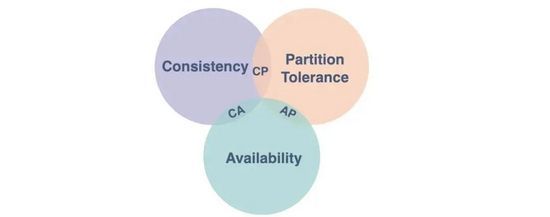
二、系统CAP
面对这种全球性跨地域的分布式系统,我们不得不谈到CAP理论,为了能够多中心全量数据提供服务,Partition tolerance(分区容错性)是必须要解决的,但是根据CAP的理论,Consistency(一致性)和Availability(可用性)就只能满足一个。对于线上应用,可用性自不用说了,那面对这样一个问题,最终一致性是最好的选择。