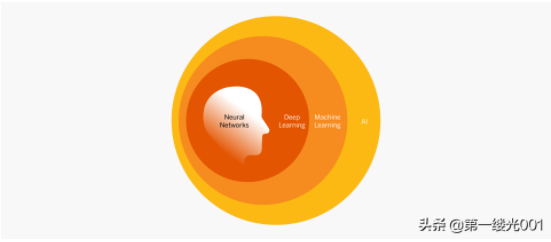
机器学习是人工智能(AI)的子集。它专注于训练计算机,以从数据中学习并根据经验进行改进,而不是为此进行显式编程。在机器学习中,对算法进行训练,以查找大型数据集中的模式和相关性,并根据该分析做出最佳决策和预测。机器学习应用程序会随着使用而改进,并且随着它们能够访问的数据越来越多而变得更加准确。机器学习的应用无处不在-在我们的家中,我们的购物车,我们的娱乐媒体和我们的医疗保健中。
人工智能和机器学习之间的关系图
什么是神经网络?
在生物大脑中的神经元上建立了一个人工神经网络(ANN)。人工神经元称为节点,并以多层形式聚集在一起,并并行运行。当人工神经元接收到数字信号时,它将对其进行处理并向与之连接的其他神经元发出信号。就像在人脑中一样,神经强化可以改善模式识别,专业知识和整体学习能力。
什么是深度学习?
这种机器学习被称为“深度学习”,因为它包括神经网络的许多层以及大量复杂而分散的数据。为了实现深度学习,该系统与网络中的多个层配合使用,提取出越来越高级的输出。例如,用于处理自然图像并寻找Gloriosa雏菊的深度学习系统将在第一层识别植物。当它在神经层中移动时,它将识别出花朵,然后是雏菊,最后是Gloriosa雏菊。深度学习应用的示例包括语音识别,图像分类和药物分析。
机器学习如何工作?
机器学习由使用各种算法技术的不同类型的机器学习模型组成。根据数据的性质和期望的结果,可以使用以下四种学习模型之一:有监督,无监督,半监督或增强。在每个模型中,相对于使用中的数据集和预期结果,可以应用一种或多种算法技术。机器学习算法的基本目的是对事物进行分类,查找模式,预测结果并做出明智的决策。当涉及复杂且更不可预测的数据时,可以一次使用一种算法,也可以组合使用这些算法以达到最佳的准确性。
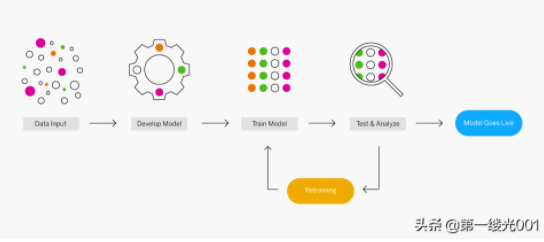
机器学习过程如何工作
什么是监督学习?
监督学习是四个机器学习模型中的第一个。在监督学习算法中,机器是通过示例进行教学的。监督学习模型由“输入”和“输出”数据对组成,其中输出标记有所需的值。例如,假设目标是让机器分辨雏菊和三色堇之间的区别。一个二进制输入数据对包括一个雏菊图像和一个三色堇图像。该特定对的理想结果是选择雏菊,因此它将被预先标识为正确的结果。
通过一种算法,系统会随着时间的推移编译所有这些训练数据,并开始确定相关的相似性,差异和其他逻辑点-直到它可以完全自己预测雏菊或三色堇问题的答案为止。这相当于给孩子一个答案键来解决一系列问题,然后要求他们展示他们的工作并解释他们的逻辑。我们每天与之交互的许多应用程序中都使用了监督学习模型,例如产品的推荐引擎和流量分析应用程序(例如Waze),它们预测了一天中不同时间的最快路线。
什么是无监督学习?
无监督学习是四种机器学习模型中的第二种。在无监督学习模型中,没有答案键。机器研究输入的数据(其中许多是未标记和非结构化的),并开始使用所有相关的可访问数据来识别模式和相关性。在许多方面,无监督学习都以人类如何观察世界为模型。我们使用直觉和经验将事物组合在一起。随着我们遇到越来越多的事物示例,我们对事物进行分类和识别的能力变得越来越准确。对于机器,“经验”是由输入的数据量和可用的数据量定义的。无监督学习应用的常见示例包括面部识别,基因序列分析,市场研究和网络安全。
什么是半监督学习?
半监督学习是四种机器学习模型中的第三种。在理想情况下,所有数据在输入到系统之前都将进行结构化和标记。但这显然不可行,因此,当存在大量原始的,非结构化的数据时,半监督学习成为可行的解决方案。该模型包括输入少量标记数据以扩充未标记数据集。从本质上讲,标记的数据起着使系统运行的作用,并且可以大大提高学习速度和准确性。半监督学习算法指示机器分析标记数据的相关属性,以将其应用于未标记数据。
正如本MIT Press研究论文中深入探讨的那样但是,存在与该模型相关的风险,其中标记的数据中的缺陷会被系统获悉并复制。最成功地使用半监督学习的公司,请确保已制定最佳实践协议。半监督学习用于语音和语言分析,复杂医学研究(例如蛋白质分类)和高级欺诈检测。
什么是强化学习?
强化学习是第四种机器学习模型。在监督学习中,机器会获得答案键并通过查找所有正确结果之间的相关性来学习。强化学习模型不包括答案键,而是输入一组允许的动作,规则和潜在的最终状态。当算法的期望目标是固定的或二进制的时,机器可以通过示例学习。但是,在期望的结果是可变的情况下,系统必须通过经验和奖励来学习。在强化学习模型中,“奖励”是数字,并作为系统寻求收集的内容编程到算法中。
在许多方面,该模型类似于教别人如何下棋。当然,不可能试图向他们展示所有可能的举动。取而代之的是,您解释规则,然后它们通过实践来增强技能。奖励的形式不仅是赢得比赛,还包括获得对手的棋子。强化学习的应用包括针对在线广告,计算机游戏开发和高风险股票市场交易的买方的自动价格竞标。
机器学习挑战
数据科学家和哈佛大学毕业生泰勒·维甘(Tyler Vigan)在他的《虚假关联》一书中指出:“并非所有的关联都表明潜在的因果关系。” 为了说明这一点,他提供了一张图表,显示了人造黄油消费量与缅因州的离婚率之间很明显的相关性。当然,此图表旨在说明一个幽默点。但是,更重要的是,机器学习应用程序容易受到人为和算法偏见和错误的影响。而且由于其学习和适应的倾向,错误和虚假相关性可以在整个神经网络中快速传播和污染结果。