你拿着手机拍视频时,最大的困扰是什么?
抖……
视频抖动似乎成为亟需解决的一大问题。
近日的一项研究可以很好地解决视频抖动问题。它的效果是这样的:
从画面看,右边的视频抖动明显减少,即使是疾走拍摄,看起来也不那么晃眼。

人潮汹涌的公共场所拍摄视频进行对比,右边的动图明显稳定了很多。
引言
随着 YouTube、Vimeo 和 Instagram 等网络平台上视频内容的快速增长,视频的稳定变得越来越重要。没有专业视频稳定器捕获的手机视频通常不稳定且观看效果不佳, 这对视频稳定算法提出了重大挑战。现有的视频稳定方法要么需要主动裁剪帧边界,要么会在稳定的帧上产生失真伪像。
所以,如何解决视频抖动,产生稳定的视频拍摄效果呢?来自台湾大学、谷歌、弗吉尼亚理工大学和加州大学默塞德分校等研究机构的研究者提出了一种无需裁剪的全帧视频稳定算法。

论文地址:
https://arxiv.org/pdf/2102.06205.pdf
项目地址:
https://github.com/alex04072000/NeRViS
具体而言,该研究提出了一种通过估计稠密的扭曲场来实现全帧视频稳定的算法,既可以融合来自相邻帧的扭曲内容,也能合成全帧稳定的帧。这种算法的核心技术为基于学习的混合空间融合,它可以减轻因光流不精确和快速移动物体造成的伪影影响。研究者在 NUS 和 selfie 视频数据集上验证了该方法的有效性。此外,大量的实验结果表明,该研究提出的方法优于以往的视频稳定方法。
本研究的主要贡献如下:
将神经渲染技术应用于视频稳定中,以缓解对流不准确的敏感性问题;
提出了一种混合融合机制,用于在特征和图像级别上组合来自多帧的信息,并通过消融研究系统地验证了各种设计选择;
在两个公共数据集上展示了与代表性视频稳定技术相比较而言,该研究所提出的方法具有良好性能。
算法实现
本研究提出的视频稳定方法一般分为三个阶段:1)运动估计;2)运动平滑;3) 帧扭曲以及渲染。该研究重点集中在第三阶段,即渲染高质量的帧而不需要任何裁剪。算法不依赖于特定的运动估计 / 平滑技术。
研究假设从真实相机空间到虚拟相机空间的扭曲场可用于每一帧视频。对于给定的输入视频,首先对每帧的图像特征进行编码,在特定的目标时间戳处将相邻帧扭曲到虚拟摄像机空间,然后融合这些特征来渲染一个稳定的帧。
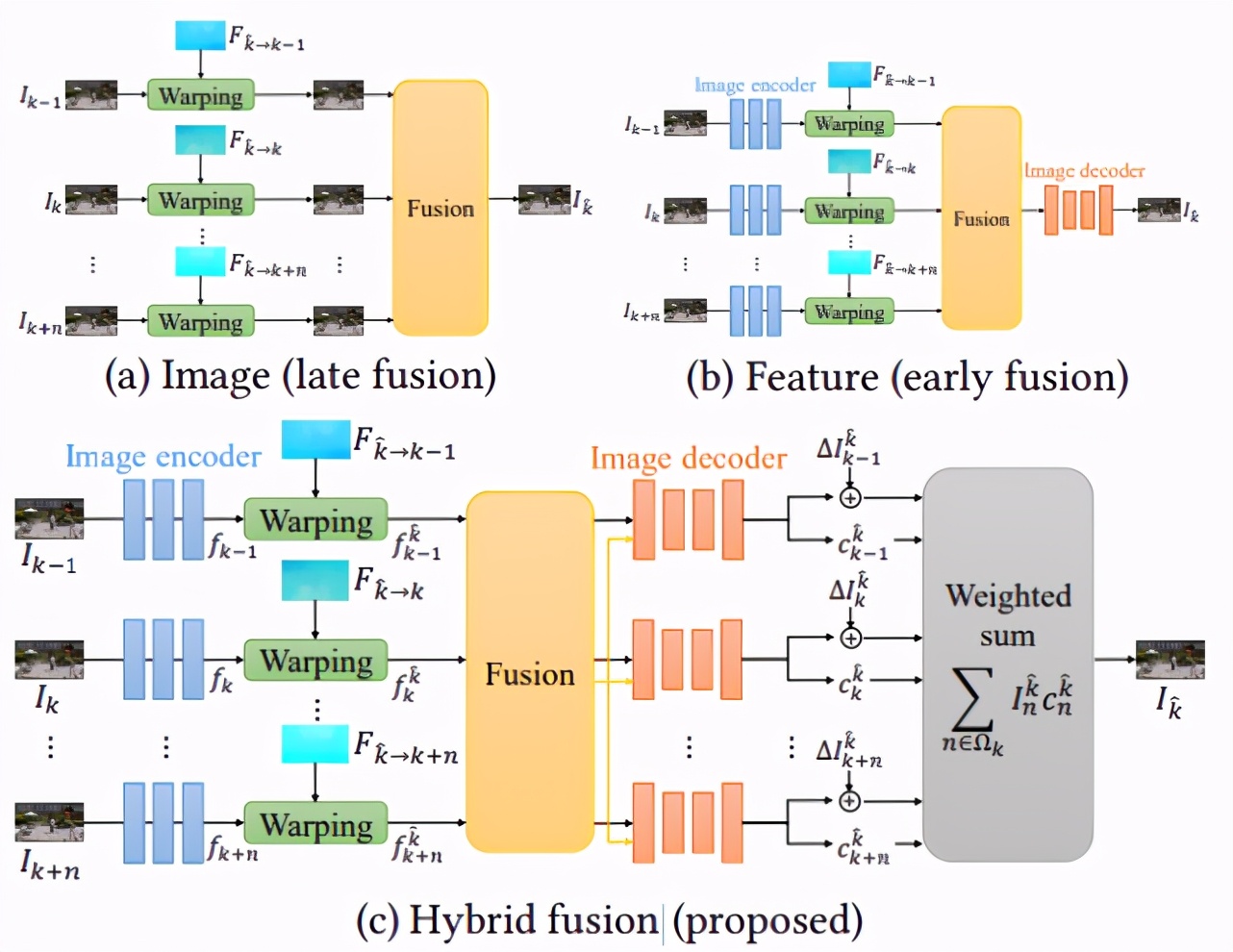
图 3:融合多个帧的设计选择。
为了合成全帧稳定的视频,需要对输入的不稳定视频中多个相邻帧的内容进行对齐和融合。如图 3 所示,主要包括三个部分:
传统的全景图像拼接(或基于图像的渲染)方法通常在图像级别对扭曲(稳定)的图像进行融合。在对齐比较准确时图像级融合效果良好,但在流估计不可靠时可能产生混合伪影;
可以将图像编码为抽象的 CNN 特征,在特征空间中进行融合,并学习到一个解码器,可将融合后的特征转换为输出帧。这种方法对流不准确性具有较好的鲁棒性,但通常会产生过度模糊的图像;
该研究提出的算法结合了这两种策略的优点。首先提取抽象的图像特征(公式(6));然后融合多帧扭曲的特征。对于每一个源帧,将融合后的特征映射和各个扭曲的特征一起解码为输出帧和相关的置信度映射。最后使用公式(8)中生成图像的加权平均值生成最终输出帧。
扭曲和融合
扭曲:在虚拟像机空间中,扭曲相邻帧,使其与目标帧对齐。因为已经有了从目标帧到关键帧的扭曲场,以及从关键帧到相邻帧的估计光流,然后可以通过链接流向量来计算从目标帧到相邻帧的扭曲场。因此可以使用向后扭曲来扭曲相邻帧 I_n 以对齐目标帧。
由于遮挡或超出边界,目标帧中的一些像素在邻近帧中不可见。因此,该研究计算每个相邻帧的可见性掩码 {}∈ω,来表示一个像素在源帧中是否有效(标记为 1)。该研究使用[Sundaram 等人. 2010] 方法来识别遮挡像素(标记为 0)。
融合空间:研究者探讨了几种融合策略来处理对齐的帧。首先,他们可以在图像空间中直接混合扭曲的颜色帧产生输出稳定帧,如图 3(a)所示。这种图像空间融合方法在图像拼接、视频外插和新视角合成中很常用。
为了结合图像空间和特征空间最佳融合,该研究提出了一种用于视频稳定的混合空间融合机制(图 3(c))。与特征空间融合相似,该研究首先从每个相邻帧中提取高维特征,然后利用流对特征进行扭曲。之后学习 CNN 来预测最能融合特征的混合权重。研究者将融合后的特征映射和每个相邻帧的扭曲特征连接起来,形成图像解码器输入。图像解码器学习预测目标帧和每个相邻帧的置信图。最后采用图像空间融合的方法,根据预测权重对所有预测的目标帧进行融合,得到最终的稳定帧。
混合空间融合和特征空间融合的核心区别在于图像解码器的输入。下图 5(b)中的图像解码器仅将融合特征作为输入来预测输出帧。融合的特征映射已经包含来自多个帧的混合信息。因此,图像解码器可能难以合成锐利的图像内容。相比之下,图 5(c)中的图像解码器以融合的特征映射为指导,从扭曲的特征重构目标帧。实证研究发现,这提高了输出帧的锐度,同时避免了重影和毛刺伪影。

图 5:不同混合空间的效果。
实验结果
控制变量实验
融合功能。该研究使用图像空间融合、特征空间融合和混合空间融合来训练所提出的模型。对于图像空间融合,该研究还包括两种传统的融合方法:多波段融合和图切割。结果如下表 1 所示:
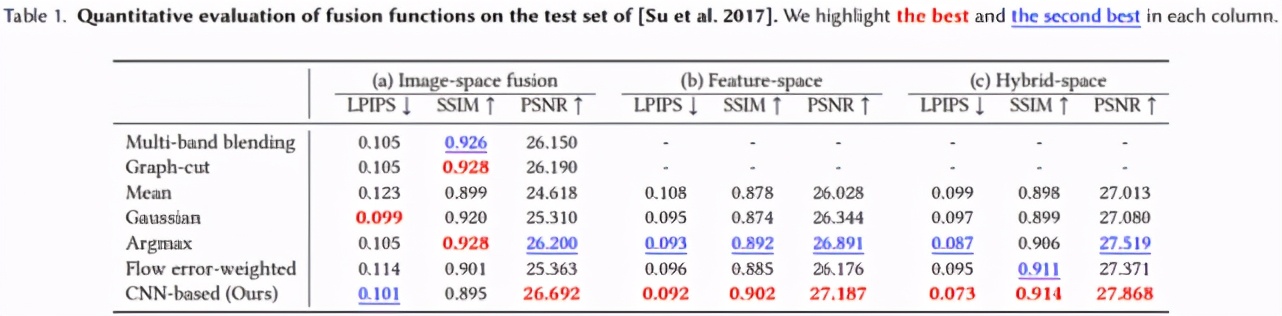
量化评估
该研究使用以前提出的一些 SOTA 视频稳定算法对所提出的方法进行了评估,结果如下表 4 所示:
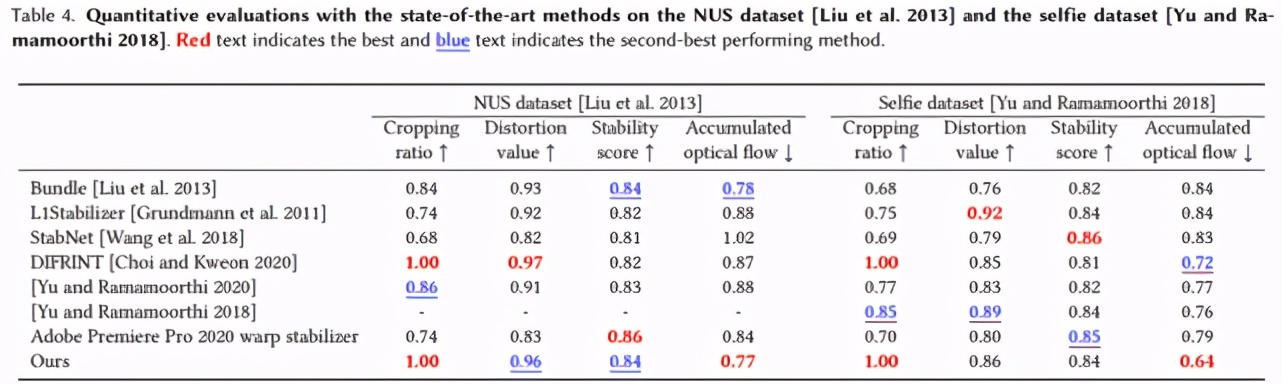
视觉比较
在下图 10 中展示了该研究所用方法的一个稳定框架和来自 Selfie 数据集的最新方法。该方法生成的全帧稳定视频具有较少的视觉伪影。

图 10:与 SOTA 方法的视觉效果对比。
由结果可得,该研究提出的融合方法不会受到严重裁剪帧边界的影响,并且渲染稳定帧时的伪影明显少于 DIFRINT。
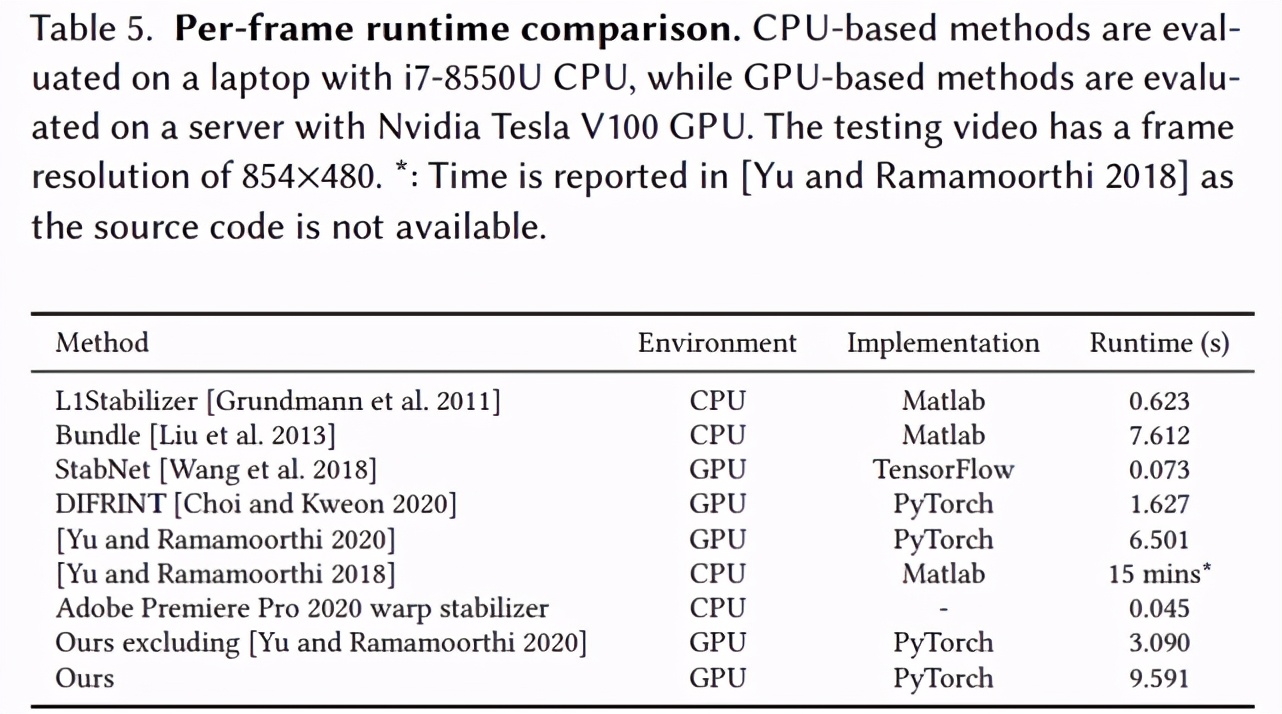
运行时间分析
该研究在基于 CPU 方法 [Grundmann et al. 2011; Liu et al. 2013; Yu and Ramamoorthi 2018] 以及 i7-8550U CPU 笔记本上对运行时间进行了实验。此外,该研究还在基于 GPU 方法 [Choi and Kweon 2020; Wang et al. 2018; Yu and Ramamoorthi 2020]以及 Nvidia Tesla V100 GPU 上对运行时间进行了实验。测试视频的帧分辨率为 854×480。结果如下表 5 所示: