












本文转载自微信公众号「问其」,作者陈少文。转载本文请联系问其公众号。
1. 本文主要讨论什么
勿在浮沙筑高台。业务量的增长、业务形态的进化都需要坚实强劲的 IT 系统支撑。业务内容对市场是透明的,但是 IT 系统不是一朝一夕能建设完善的。未来公司之间的竞争主要也会来自于 IT 系统之间的竞争,能不能快速响应业务需求是决胜的关键。
IT 系统也在不断进化。建设高效、智能的 IT 系统成本是很高的。刚开始只需要够用,接着是好用,最后成为核心竞争力。
变化并不可怕,可怕的是沉重的历史包袱。对于技术人员来说,新需求不是什么难事,难的是在高速飞行状态下更换部件。既能保证原有功能正常,又能满足新的需求,还要更替 IT 基础设施。
在进行容器化、Kubernetes 化转变的过程中,如何直接给虚拟机 (VM) 分发文件,在虚拟机上执行脚本是本文思考的重点。直接操作虚拟机,不符合云原生不可变的基础设施定义,但历史业务场景要求,作为 IT 平台方需要提供解决方案。本文将对此给出答案。
2. 为什么需要一个 PaaS 平台
当一个 IT 运维团队开始建设 PaaS 时,他们才真正算站起来了。
在目前的环境下,业务模式、形态不再是商业机密。信息、人员的快速流动,让公司之间赤裸对峙。你有的业务,我也可以有;我有的功能,你也可以加。业务短时间爆发增长的时代已过,我们正处于一个精细化运营、数据化决策的时代。
新时代对 IT 系统有着更多的需求,这些需求在传统模式下是无法满足的。传统的模式是针对特定的场景开发 SaaS 服务,将技能封装在固定的流程中,降本增效,控制风险。这在早期也够用,但随着业务规模发展,运维人员会陷入无休止地加班改功能、加功能的状态。
PaaS 的目的是为了抽象一些公共的功能。中台也是这样建设的,不变的领域实现落地到平台,对外提供服务接口。让前端直接与业务绑定在一起,应对市场的快速变化。
当有 PaaS 平台时,IT 技能才会有一个沉淀的方向,IT 人员才能从重复、繁杂的任务中抽离出来思考业务,通过拼装才能快速支撑业务。
3. 如何实现文件分发、脚本执行
3.1 在传统 PaaS 平台下
如果让一个运维人员批量分发一个文件、执行一个脚本,他使用 Ansible 可以很快实现。
但是上面提到要解放双手,建设 PaaS 平台。下面是一张传统的 IT 设施架构图:
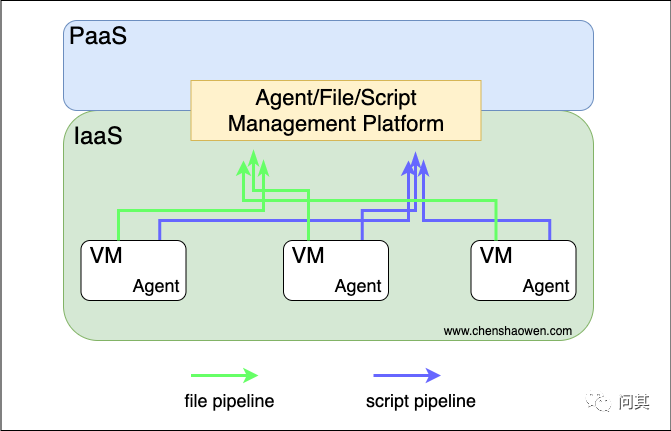
在传统的 IT 流程中,购买的每一台机器都需要在 CMDB 中注册登记,然后安装 Agent 进行管理。通过 Agent 提供的文件、脚本管道,上层的平台可以实现文件分发、脚本执行的功能。
但 Agent 的开发成本很高。无数次的业务故障才能打磨出一个高并发、高性能、高可用、高稳定性、高安全性的 Agent。在一些开源的解决方案中,Agent 作为公司 IT 核心不会开放源码。
3.2 在 Kubernetes 下
在云原生的背景下,直接修改 IaaS 层 VM 的状态是不被允许的,称之为不可变的基础设施。在有些实践中,甚至会禁用容器的 SSHD,一旦有 SSH 登录,容器会即刻退出。
在 Kubernetes 下是不提倡直接向节点分发文件、执行脚本的。
不可变的基础设施 (IaC) 的逻辑是为了保证状态能复现,符合声明式的语义。直接修改基础设施是一个过程式的操作,基础设施处于正在运行的状态,存在很多的不确定性,无法准确描述。
下面是云原生下的 IT 设施架构图:
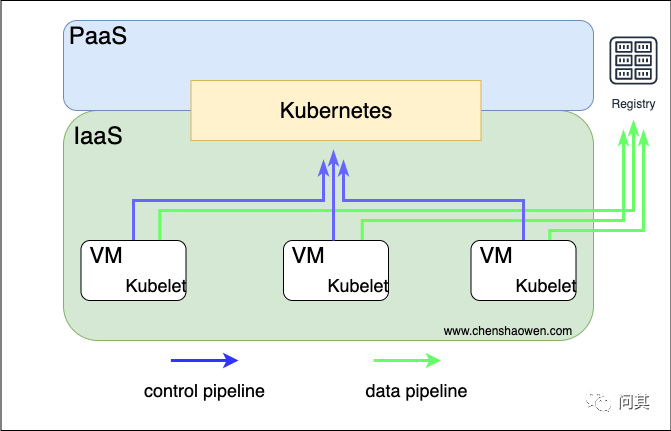
Kubernetes 接管了 IaaS 层的资源,控制着整个系统的运作。而业务的服务主要通过镜像仓库下发,业务的日志采集和监控还需要借助其他开源组件。
4. Kubernetes 分发文件、执行脚本计划
4.1 演练的准备
下面是清单:
- 一个 Kuberentes 集群,需要能执行 kubectl 命令
- 待分发的 VM 已经添加到集群节点中
- Docker 环境以及 Dockerhub 账户
4.2 演练的内容
- 演练分为如下步骤:
- 准备执行的脚本和文件
- 构建并推送镜像
创建 Kubernetes Job 进行分发
4.3 演练的目标
- 演练的目标如下:
- 在虚拟机上运行一个 Web 服务,提供文件下载功能
将一个文件分发到虚拟机,并添加到下载服务中
5. Kubernetes 分发文件、执行脚本
5.1 集群描述
- kubectl get node -o wide
- NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
- test Ready master,worker 6d2h v1.17.9 10.160.6.35 <none> CentOS Linux 7 (Core) 3.10.0-957.21.3.el7.x86_64 docker://20.10.6
由于预算有限,这里没有布置多节点的环境。但为了贴合真实场景,在执行 Job 时会使用 nodeSelector 选择指定的节点,而不会让分发过程失控。
5.2 准备分发文件、执行脚本
1.文件目录结构
- demo
- Dockerfile
- start.sh
以下构建镜像相关的命令都是在 demo 目录中执行。
2.脚本 start.sh 内容
- cd /data
- nohup python -m SimpleHTTPServer 8000&
Kubernetes 集群使用的是 CentOS 7 操作系统,自带 Python 2 的解释器。这里为了简单,使用 SimpleHTTPServer 提供下载服务。
3.Dockerfile 内容
- FROM docker.io/alpine:3.12
- ARG file
- ADD ${file} /data/
4.待分发的文件内容
文件可以是构建环境中的本地文件,也可以是任意的 URL 文件链接。这里我选择的是一个 PDF 的文件链接:https://www.chenshaowen.com/static/file/ui-autotest.pdf
5.3 构建镜像
在 Kubernetes 中通用的是 OCI 镜像,因此需要对文件、脚本进行封装,将文件、脚本打包到镜像中,通过镜像仓库进行分发。
将待分发的文件打包到镜像中
- docker build --build-arg file=https://www.chenshaowen.com/static/file/ui-autotest.pdf -t shaowenchen/file-1:latest ./
推送镜像:
- docker push shaowenchen/file-1:latest
将待执行的脚本打包到镜像中
- docker build --build-arg file=./start.sh -t shaowenchen/shell-1:latest ./
推送镜像:
- docker push shaowenchen/shell-1:latest
- 查看 Dockerhub 中的镜像
5.4 Kubernetes 节点预处理
除了待分发的节点需要添加到 Kubernetes 集群,另外一个重要的地方是需要对节点进行预处理。
节点预处理主要是给节点添加 label,对节点进行标记,便于准确分发。在生产中,通常网络是分区的,因此引入两个维度的标记:zone 和 ip。
- 标记节点 zone 、ip
zone 表示分区,这里标记为 a。ip 表示虚拟机在这个分区中的 IP 地址。在实践过程中,可以在安装 Kubernetes 集群时批量处理。
- kubectl label node test zone=a
- kubectl label node test ip=10.160.6.35
- 查看标记的标签
- kubectl get nodes --show-labels
- NAME STATUS ROLES AGE VERSION LABELS
- test Ready master,worker 6d2h v1.17.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,ip=10.160.6.35,kubernetes.io/arch=amd64,kubernetes.io/hostname=test,kubernetes.io/os=linux,node-role.kubernetes.io/master=,node-role.kubernetes.io/worker=,zone=a
5.5 向指定节点分发脚本并执行
- cat <<EOF | kubectl apply -f -
- apiVersion: batch/v1
- kind: Job
- metadata:
- name: shell-1
- spec:
- template:
- spec:
- containers:
- - name: shell-1
- spec:
- containers:
- - name: shell-1
- command: ["sh"]
- args: ["-c", "cp /data/start.sh /hostdata/; echo 'sh /data/start.sh&' | nsenter -t 1 -m -u -i -n;sleep 99999"]
- image: shaowenchen/shell-1:latest
- securityContext:
- privileged: true
- volumeMounts:
- - name: hostdata
- mountPath: /hostdata
- hostIPC: true
- hostNetwork: true
- hostPID: true
- volumes:
- - name: hostdata
- hostPath:
- path: /data/
- restartPolicy: Never
- nodeSelector:
- zone: a
- ip: 10.160.6.35
- EOF
由于镜像很小,很快脚本就能得到执行。登录到虚拟机上,查看是否有相关的服务进程:
- ps aux |grep SimpleHTTPServer
- root 16523 0.1 0.0 198028 10120 ? S 22:38 0:00 python -m SimpleHTTPServer 8000
- root 17558 0.0 0.0 112684 1000 pts/1 S+ 22:39 0:00 grep --color=auto SimpleHTTPServer
表明 SimpleHTTPServer 服务已经在虚拟机上运行成功
5.6 向指定节点分发文件
- cat <<EOF | kubectl apply -f -
- apiVersion: batch/v1
- kind: Job
- metadata:
- name: file-1
- spec:
- template:
- spec:
- containers:
- - name: file-1
- spec:
- containers:
- - name: file-1
- command: ["sh"]
- args: ["-c", "cp -R /data/* /hostdata/; sleep 10"]
- image: shaowenchen/file-1:latest
- securityContext:
- privileged: true
- volumeMounts:
- - name: hostdata
- mountPath: /hostdata
- hostIPC: true
- hostNetwork: true
- hostPID: true
- volumes:
- - name: hostdata
- hostPath:
- path: /data/
- restartPolicy: Never
- nodeSelector:
- zone: a
- ip: 10.160.6.35
- EOF
通过页面访问,可以查看到提供的下载页面:
在虚拟机上查看分发的文件:
- ls /data/
- start.sh ui-autotest.pdf
6. 总结
本文主要是在 Kubernetes 下,演示了面向虚拟机如何进行文件分发、脚本执行,给大家在设计 PaaS 平台时提供一点思路。
将 Kubelet 当做传统的 Agent 使用。Kubelet 管理 Pod ,而 Agent 管理 IaaS。两者之间有共同点可以思考。另外,Kubernetes 单集群支持高达 5000 个节点,能满足绝大部分需求场景。通过多集群可以支持更多节点。
可以支持更多来源的二进制分发。示例中使用的是 https 文件,也可以使用本地文件,还可以将 S3 中的文件下载到本地再打包。同时,最终的镜像只比原始文件大几 M。
脚本执行可以继续优化。当 Job 执行完成时,脚本执行也会结束。在实践过程中,应该向主机添加托管的服务。这里为了演示简便,没有深究。
直接使用 hostIPC/hostPID 的 Pod 替代传统虚拟机上的服务进程也是一种方案。
















