近日,蚂蚁安全天筭实验室安全专家蕉雪与复旦大学自然语言处理团队(Fudan NLP)魏忠钰教授合作的学术论文《基于小样本学习的个性化Hashtag推荐》被中国计算机学会推荐B类期刊《中文信息学报》录取。
《中文信息学报》创刊于1986年,作为国内计算机、计算技术类83种中文期刊评出的十五种核心期刊之一,及时反映着我国中文信息处理的先进水平 。数据显示,《中文信息学报》每年在各个相关子方向录取文章平均为10篇左右, 代表了我国最新的中文信息处理进展和学术动向。
一、快速学习:从“题海战术”到“触类旁通”
当你在社交媒体上发表内容时,在打出#时,社交媒体会推荐给你一个合适的Hashtag (话题词) ,把内容划分到相应的话题下面去,方便对社交媒体的内容进行分类管理。
为什么要在Hashtag推荐算法里引入小样本学习算法?复旦大学自然语言处理团队的曾兰君同学向我们介绍:举个例子,现有的Hashtag推荐算法,一般是使用分类框架来做的, 当你 使用属于100个类别的社交媒体文本来对模型进行训练,后面在做推荐时,模型也只能将待 推荐的文本分到这100个类别中来。 没有进行重新训练的情况下,模型不能处理训练不可见的Hashtag。
然而,Hashtag会随着时事热点不断快速更新。课题组 希 望社交媒体在你写下#时,就会根据你社交媒体文本的历史特征和当前输入的文本内容,猜到你可能需要的Hashtag,并将合适的Hashtag推荐给你。
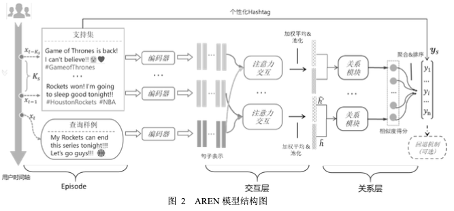
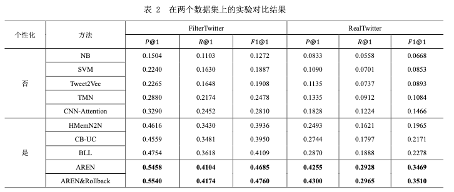
为了解决这一问题,论文提出将Hashtag推荐任务建模成小样本学习任务。 同时,结合用户使用Hashtag的 偏好降低推荐的复杂度。 通过互联网公开授权的API获取的数据集上的 实验表明, 与目前最优方法相比,该模型不仅可以取得更好的推荐结果,而且表现更为鲁棒 (即稳定性更强) 。
一般模型在认识一个类别的时候,需要非常多的数据才能够正确地识别一个类别,这种依赖于数据学习的识别,就像一个高考机器,通过题海战术来提高做题效率,却缺乏有效的推理逻辑。而对于人类来说,即便是儿童,当你告诉他看到的一张图片是什么的话,他就能很快地认识这个类别。
小样本学习就是希望机器能够拥有这样一个能力,在见到一个只有少量样本的类别之后,通过数据学习举一反三,就拥有对这个类别的识别能力。它可以根据用户的历史特征,之前学到的经验和当前的少量样本,能够快速的认识这个新类别,从而使识别的效率得到提升。
在未来,小样本学习可以运用到更多的领域当中。在欺诈风险防控中,欺诈手法识别对于欺诈风险形势感知以及欺诈管控至关重要。而新欺诈手法会不断出现,对于新手法的样本积累往往不足以训练好的识别模型,如何在少数样本积累的情况下对新手法进行准确识别也是一个问题。这篇对于小样本学习进行研究的工作后续计划迁移到欺诈手法识别的场景中。
二、知识驱动:从“填鸭式接受”到“主动推理”
在小样本学习领域以外,魏忠钰教授和蚂蚁天筭安全实验室还在欺诈要素识别的领域进行了合作。魏忠钰教授表示,此项目是希望模型在面对大量用户的欺诈投诉文本时,能够通过举报文本来判定欺诈要素是否满足进而判定欺诈事实是否成立。
项目的创新之处在于:之前的模型识别是数据来驱动;现在模型能在模型识别文本要素后主动推理,通过数据学习和知识推理的双驱动,更有效地将风险防范于未然。
因为该项目跟业务场景有很高的关联度,但团队没有法律方面的专家,在前期对欺诈文本的标注及识别上遇到困难,只能通过对信息检索系统和相关文献的调研,来设计初步的文本标注的框架。
而蚂蚁在合作中引入了司法团队,提供了相对专业的关于欺诈识别的框架设计,使标签体系的建立更符合业务场景,在此框架上,校方团队再进行数据的标注、模型自动化识别等算法的设计来完成模型。蚂蚁前期提供的框架基础,相当于在业务上对研究团队有了一次很实际的指导,最后呈现出来的效果甚至超出双方的预期。
目前团队对于欺诈要素的识别准确率已超过85%,主要识别举报者是否被诱骗转账、收款方是否有非法占有目的等欺诈司法审理的关键证据。研究团队目前完成欺诈投诉样本的要素标注达到4万条,通过欺诈要素识别模型判断引导用户主动去补充遗漏点,加强用户在举报流程中的体验感和主观能动性。在这过程中用户完成举报率相对提高了10%,举报的信息质量提升了8%。确保了欺诈定性的准确率稳定增长,对于欺诈的防控效率也得到提升。
据课题组的研究成果显示,在对用户举证文本的欺诈证据要素的识别基础上,进一步通过数据+知识推理实现智能抗辩审理,模型根据用户举证与大数据信息为用户输出可解释性更强的审理逻辑链条和结果 (即模型不仅能给出结论,还能告诉你它的分析思路,提供有说服力的理由) 。
相较于传统的依赖数据学习的欺诈识别算法,本次与蚂蚁的联合创新性地提出了将人的知识、经验、规则都输入到欺诈识别算法体系中,模型将实现基于推理的智能判断。相信课题组在这一技术上的创新将更好地保障用户的资金安全,也对提升行业整体的风控水平起到重要作用。
魏忠钰教授表示: 这样全新的校企合作模式,不仅带来了团队研究一直所需的应用落地场景,还将蚂蚁的实际业务经验与团队在算法上的创新互相补益,成为往后科研项目运营的一次很好的示范。 期待与蚂蚁日后能够有更进一步的长期合作,同时也期待这项研究在多个场景中得到应用,为用户推荐更为精准的信息内容。