













前言
先说个小事情,今天试了下做动图,就一张动图都花了我 1 个小时,还做得很难看。。在线求个做动图的好软件
本文主要内容如下:
上一篇讲到如何做性能调优的方式:《48 张图 | 手摸手教你微服务的性能监控、压测和调优》,比如给表加索引、动静分离、减少不必要的日志打印。但有一个很强大的优化方式没有提到,那就是加缓存,比如查询小程序的广告位配置,因为没什么人会去频繁的改,将广告位配置丢到缓存里面再适合不过了。那我们就给开源 Spring Cloud 实战项目 PassJava 加下缓存来提升下性能。
我把后端、前端、小程序都上传到同一个仓库里面了,大家可以通过 Github 或 码云访问。地址如下:
Github: https://github.com/Jackson0714/PassJava-Platform
码云:https://gitee.com/jayh2018/PassJava-Platform
配套教程:www.passjava.cn
在实战之前,我们先来看下使用缓存的原理和问题。
一、缓存
1.1 为什么要用缓存
20 年前常见的系统就是单机的,比如 ERP 系统,对性能要求不高,使用缓存的并不常见,但现如今,已经步入到互联网时代,高并发、高可用、高性能总是被提起,而缓存在这“三高”中立下汗马功劳。
我们通过会将部分数据放入缓存中,来提高访问速度,然后数据库承担存储的工作。
那么哪些数据适合放入缓存中呢?
- 即时性。例如查询最新的物流状态信息。
- 数据一致性要求不高。例如门店信息,修改后,数据库中已经改了,5 分钟后缓存中才是最新的,但不影响功能使用。
- 访问量大且更新频率不高。比如首页的广告信息,访问量,但是不会经常变化。
当我们想要查询数据时,使用缓存的流程如下:
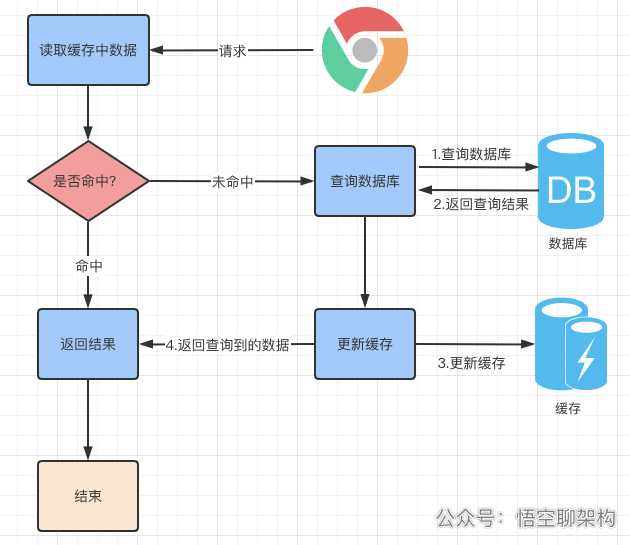
读模式缓存使用流程
1.2 本地缓存
比如现在有一个需求:前端小程序需要查询题目的类型,而题目类型放在小程序的首页在,访问量是非常高的,但是又不是经常变化的数据,所以可以将题目类型数据放到缓存中。

最简单的使用缓存的方式是使用本地缓存,也就是在内存中缓存数据,可以用 HashMap、数组等数据结构来缓存数据。
1.2.1 不使用缓存
我们先来看下不使用缓存的情况:前端的请求先经过网关,然后请求到题目微服务,然后查询数据库,返回查询结果。
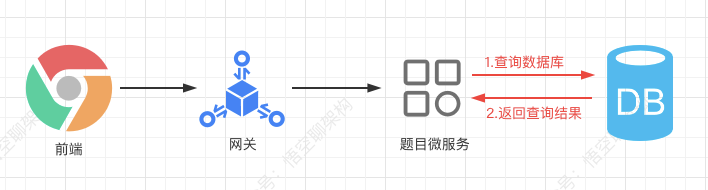
再来看下核心代码是怎么样的。
先自定义一个 Rest API 用来查询题目类型列表,数据是从数据库查询出来后直接返回给前端。
- @RequestMapping("/list")
- public R list(){
- // 从数据库中查询数据
- typeEntityList = ITypeService.list();
- return R.ok().put("typeEntityList", typeEntityList);
- }
1.2.2 使用缓存
来看下使用缓存的情况:前端先经过网关,然后到题目微服务,先判断缓存中有没有数据,如果没有,则查询数据库再更新缓存,最后返回查询到的结果。
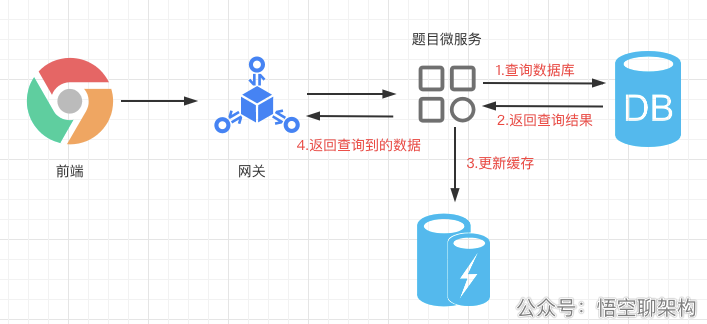
那我们现在创建一个 HashMap 来缓存题目的类型列表:
- private Map<String, Object> cache = new HashMap<>();
先获取缓存的类型列表
- List<TypeEntity> typeEntityListCache = (List<TypeEntity>) cache.get("typeEntityList");
如果缓存中没有,则先从数据库中获取。当然,第一次查询缓存时,肯定是没有这个数据的。
- // 如果缓存中没有数据
- if (typeEntityListCache == null) {
- System.out.println("The cache is empty");
- // 从数据库中查询数据
- List<TypeEntity> typeEntityList = ITypeService.list();
- // 将数据放入缓存中
- typeEntityListCache = typeEntityList;
- cache.put("typeEntityList", typeEntityList);
- }
- return R.ok().put("typeEntityList", typeEntityListCache);
我们用 Postman 工具来看下查询结果:
- 请求URL:https://github.com/Jackson0714/PassJava-Platform

返回了题目类型列表,共 14 条数据。
以后再次查询时,因为缓存中已经有该数据了,所以直接走缓存,不会再从数据库中查询数据了。
从上面的例子中我们可以知道本地缓存有哪些优点呢?
- 减少和数据库的交互,降低因磁盘 I/O 引起的性能问题。
- 避免数据库的死锁问题。
- 加速相应速度。
当然,本地缓存也存在一些问题:
- 占用本地内存资源。
- 机器宕机重启后,缓存丢失。
- 可能会存在数据库数据和缓存数据不一致的问题。
- 同一台机器中的多个微服务缓存的数据不一致。
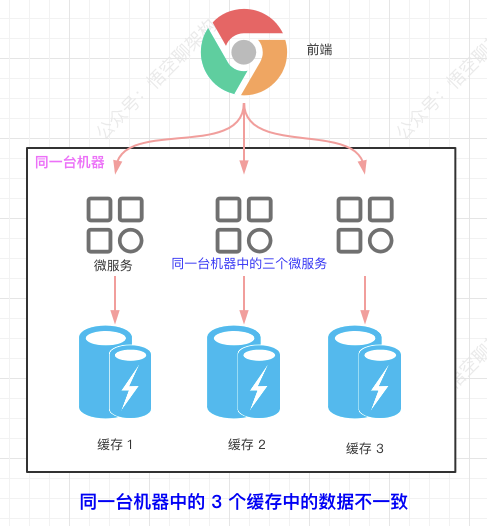
- 集群环境下存在缓存的数据不一致的问题。
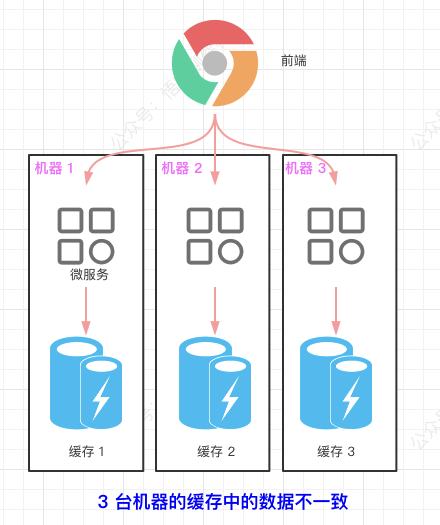
基于本地缓存的问题,我们引入了分布式缓存 Redis 来解决。
二、缓存 Redis
2.1 Docker 安装 Redis
首先需要安装 Redis,我是通过 Docker 来安装 Redis。另外我在 ubuntu 和 Mac M1 上都装过 docker 版的 Redis,大家可以参照这两篇来安装。
《Ubuntu 上到 Docker 安装redis》
《M1 和 Docker 谈了个恋爱...》
2.2 引入 Redis 组件
我用的是 passjava-question 微服务,所以是在 passjava-question 模块下的配置文件 pom.xml 中引入 redis 组件。
文件路径:/passjava-question/pom.xml
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-data-redis</artifactId>
- </dependency>
2.3 测试 Redis
我们可以写一个测试方法来测试引入的 redis 是否能存数据,以及能否查出存的数据。
我们都是使用 StringRedisTemplate 库来操作 Redis,所以可以自动装载下 StringRedisTemplate。
- @Autowired
- StringRedisTemplate stringRedisTemplate;
然后在测试方法中,测试存储方法:ops.set(),以及 查询方法:ops.get()
- @Test
- public void TestStringRedisTemplate() {
- // 初始化 redis 组件
- ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
- // 存储数据
- ops.set("悟空", "悟空聊架构_" + UUID.randomUUID().toString());
- // 查询数据
- String wukong = ops.get("悟空");
- System.out.println(wukong);
- }
set 方法的第一个参数是 key,比如示例中的 “悟空”。
get 方法的参数也是 key。
最后打印出了 redis 中 key = “悟空” 的缓存的值:
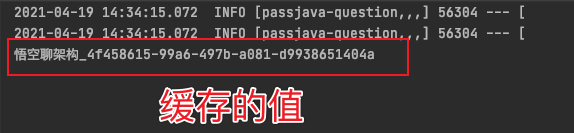
另外也可以通过客户端工具来查看,如下图所示:
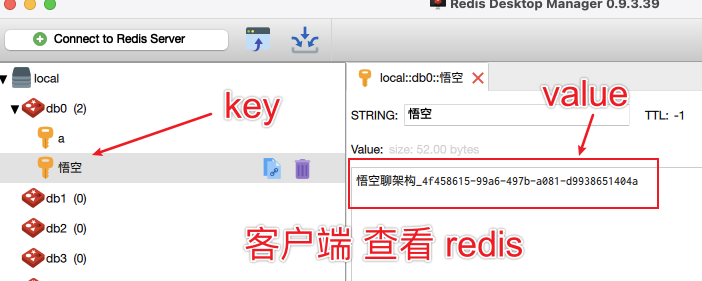
我下载的是这个软件:Redis Desktop Manager windows,Mac M1 上正常使用。下载地址:
- http://www.pc6.com/softview/SoftView_450180.html
2.4 用 Redis 改造业务逻辑
用 redis 替换 hashmap 也不难,把用到 hashmap 的地方都用 redis 改下。另外需要注意的是:
从数据库中查询到的数据先要序列化成 JSON 字符串后再存入到 Redis 中,从 Redis 中查询数据时,也需要将 JSON 字符串反序列化为对象实例。
- public List<TypeEntity> getTypeEntityList() {
- // 1.初始化 redis 组件
- ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
- // 2.从缓存中查询数据
- String typeEntityListCache = ops.get("typeEntityList");
- // 3.如果缓存中没有数据
- if (StringUtils.isEmpty(typeEntityListCache)) {
- System.out.println("The cache is empty");
- // 4.从数据库中查询数据
- List<TypeEntity> typeEntityListFromDb = this.list();
- // 5.将从数据库中查询出的数据序列化 JSON 字符串
- typeEntityListCache = JSON.toJSONString(typeEntityListFromDb);
- // 6.将序列化后的数据存入缓存中
- ops.set("typeEntityList", typeEntityListCache);
- return typeEntityListFromDb;
- }
- // 7.如果缓存中有数据,则从缓存中拿出来,并反序列化为实例对象
- List<TypeEntity> typeEntityList = JSON.parseObject(typeEntityListCache, new TypeReference<List<TypeEntity>>(){});
- return typeEntityList;
- }
整个流程如下:
- 1.初始化 redis 组件。
- 2.从缓存中查询数据。
- 3.如果缓存中没有数据,执行步骤 4、5、6。
- 4.从数据库中查询数据。
- 5.将从数据库中查询出的数据转化为 JSON 字符串。
- 6.将序列化后的数据存入缓存中,并返回数据库中查询到的数据。
- 7.如果缓存中有数据,则从缓存中拿出来,并反序列化为实例对象。
2.5 测试业务逻辑
我们还是用 postman 工具进行测试:
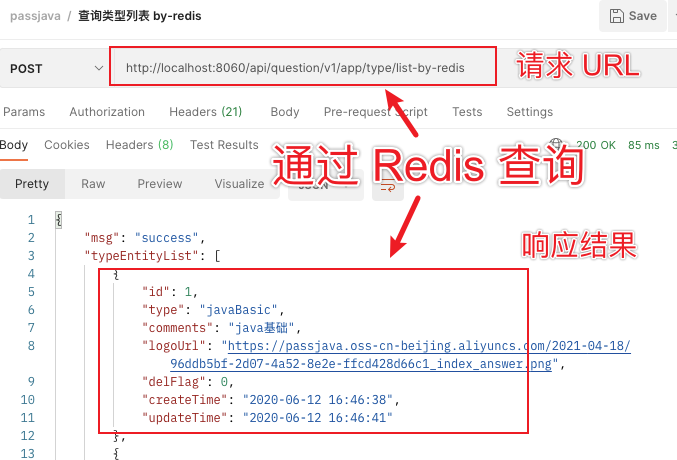
通过多次测试,第一次请求会稍微慢点,后面几次速度非常快。说明使用缓存后性能有提升。
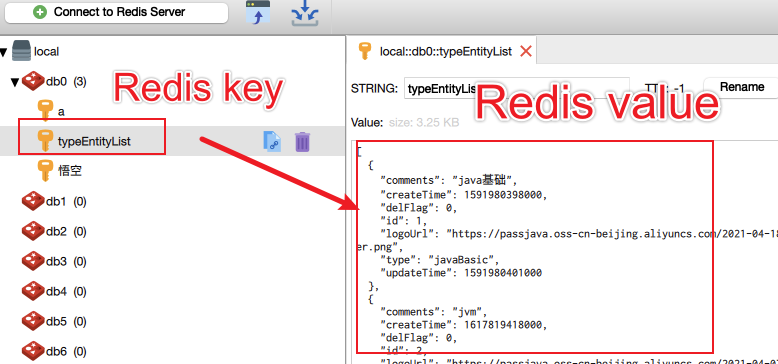
另外我们用 Redis 客户端看下结果:
Redis key = typeEntityList,Redis value 是一个 JSON 字符串,里面的内容是题目分类列表。
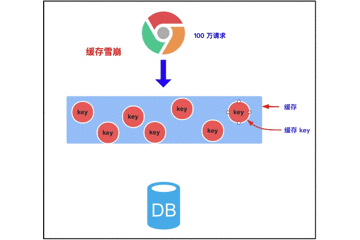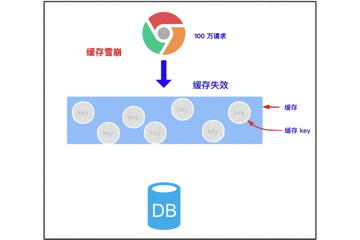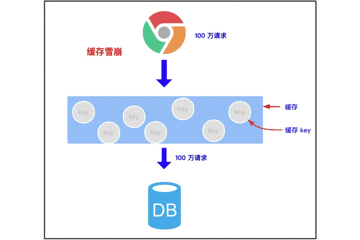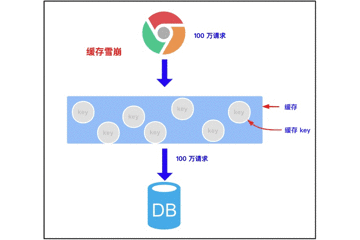
三、缓存穿透、雪崩、击穿
高并发下使用缓存会带来的几个问题:缓存穿透、雪崩、击穿。
3.1 缓存穿透
3.1.1 缓存穿透的概念
缓存穿透指一个一定不存在的数据,由于缓存未命中这条数据,就会去查询数据库,数据库也没有这条数据,所以返回结果是 null。如果每次查询都走数据库,则缓存就失去了意义,就像穿透了缓存一样。
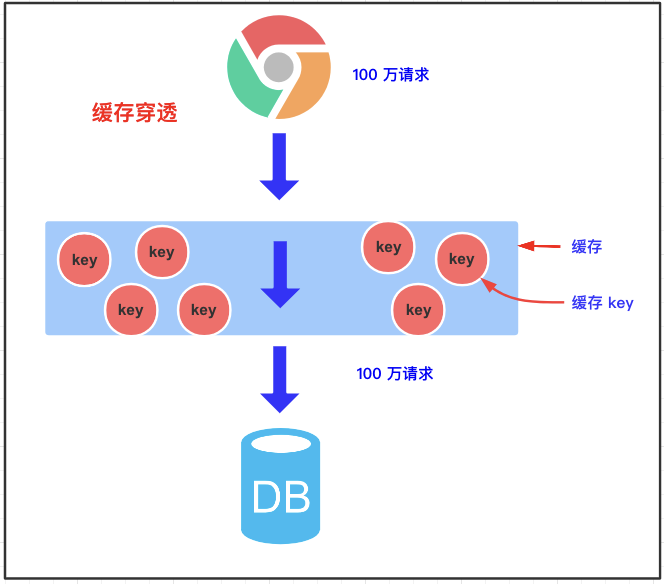
3.1.2 带来的风险
利用不存在的数据进行攻击,数据库压力增大,最终导致系统崩溃。
3.1.3 解决方案
对结果 null 进行缓存,并加入短暂的过期时间。
3.2 缓存雪崩
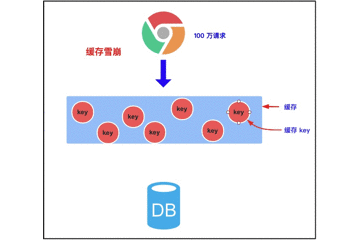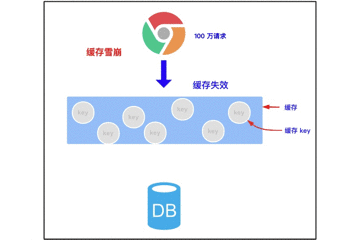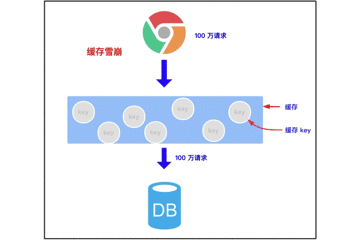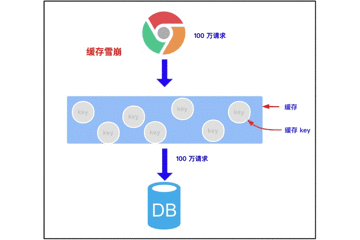
3.2.1 缓存雪崩的概念
缓存雪崩是指我们缓存多条数据时,采用了相同的过期时间,比如 00:00:00 过期,如果这个时刻缓存同时失效,而有大量请求进来了,因未缓存数据,所以都去查询数据库了,数据库压力增大,最终就会导致雪崩。
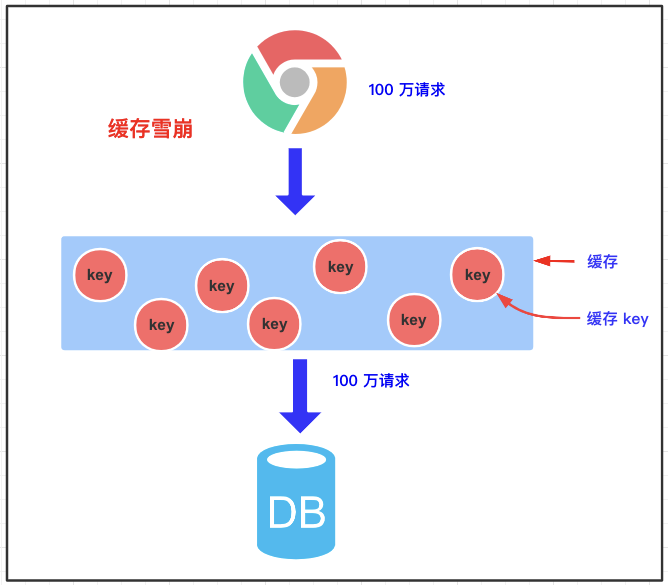
3.2.2 带来的风险
尝试找到大量 key 同时过期的时间,在某时刻进行大量攻击,数据库压力增大,最终导致系统崩溃。
3.2.3 解决方案
在原有的实效时间基础上增加一个碎挤汁,比如 1-5 分钟随机,降低缓存的过期时间的重复率,避免发生缓存集体实效。
3.3 缓存击穿
3.3.1 缓存击穿的概念
某个 key 设置了过期时间,但在正好失效的时候,有大量请求进来了,导致请求都到数据库查询了。
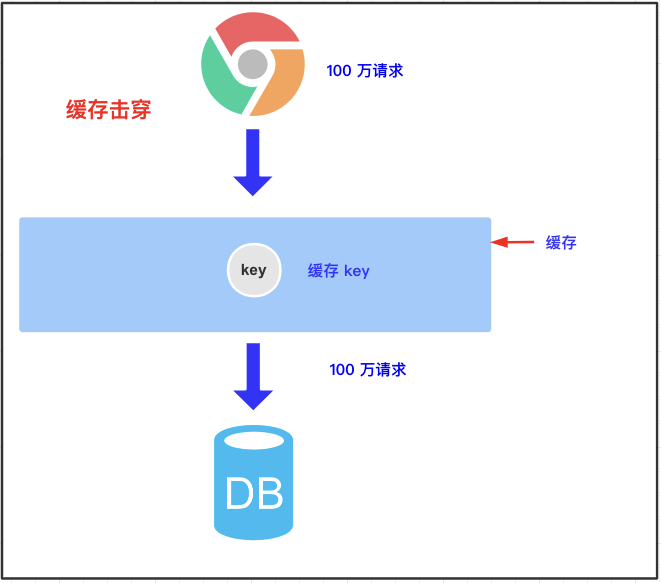
3.3.2 解决方案
大量并发时,只让一个请求可以获取到查询数据库的锁,其他请求需要等待,查到以后释放锁,其他请求获取到锁后,先查缓存,缓存中有数据,就不用查数据库。
四、加锁解决缓存击穿
怎么处理缓存穿透、雪崩、击穿的问题呢?
- 对空结果进行缓存,用来解决缓存穿透问题。
- 设置过期时间,且加上随机值进行过期偏移,用来解决缓存雪崩问题。
- 加锁,解决缓存击穿问题。另外需要注意,加锁对性能会带来影响。
这里我们来看下用代码演示如何解决缓存击穿问题。
我们需要用 synchronized 来进行加锁。当然这是本地锁的方式,分布式锁我们会在下篇讲到。
- public List<TypeEntity> getTypeEntityListByLock() {
- synchronized (this) {
- // 1.从缓存中查询数据
- String typeEntityListCache = stringRedisTemplate.opsForValue().get("typeEntityList");
- if (!StringUtils.isEmpty(typeEntityListCache)) {
- // 2.如果缓存中有数据,则从缓存中拿出来,并反序列化为实例对象,并返回结果
- List<TypeEntity> typeEntityList = JSON.parseObject(typeEntityListCache, new TypeReference<List<TypeEntity>>(){});
- return typeEntityList;
- }
- // 3.如果缓存中没有数据,从数据库中查询数据
- System.out.println("The cache is empty");
- List<TypeEntity> typeEntityListFromDb = this.list();
- // 4.将从数据库中查询出的数据序列化 JSON 字符串
- typeEntityListCache = JSON.toJSONString(typeEntityListFromDb);
- // 5.将序列化后的数据存入缓存中,并返回数据库查询结果
- stringRedisTemplate.opsForValue().set("typeEntityList", typeEntityListCache, 1, TimeUnit.DAYS);
- return typeEntityListFromDb;
- }
- }
1.从缓存中查询数据。
2.如果缓存中有数据,则从缓存中拿出来,并反序列化为实例对象,并返回结果。
3.如果缓存中没有数据,从数据库中查询数据。
4.将从数据库中查询出的数据序列化 JSON 字符串。
5.将序列化后的数据存入缓存中,并返回数据库查询结果。
五、本地锁的问题
本地锁只能锁定当前服务的线程,如下图所示,部署了多个题目微服务,每个微服务用本地锁进行加锁。
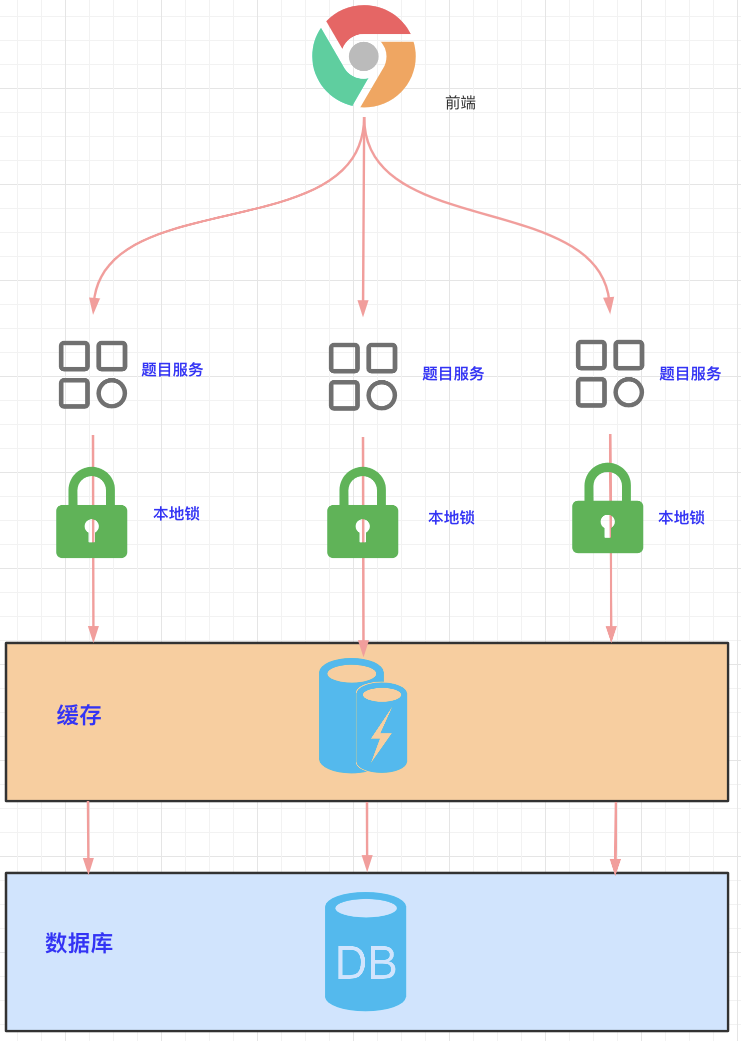
本地锁在一般情况下没什么问题,但是在某些情况下就会出问题:
比如在高并发情况下用来锁库存就有问题了:
1.比如当前总库存为 100,被缓存在 Redis 中。
2.库存微服务 A 用本地锁扣减库存 1 之后,总库存为 99。
3.库存微服务 B 用本地锁扣减库存 1 之后,总库存为 99。
4.那库存扣减了 2 次后,还是 99,就超卖了 1 个。
那如何解决本地加锁的问题呢?












