相信大家最近一定关注到一款重量级消息中间件Kafka发布了2.8版本,并且正式移除了对Zookeeper的依赖,背后的设计哲学是什么呢?仅仅只是减少了一个外部依赖吗?
答案显然不会这么简单,容我慢慢道来。
在解答为什么之前,我觉得非常有必要先来阐述一下Zookeeper的经典使用场景。
1、Zookeeper的经典使用场景
zookeeper是伴随着大数据、分布式领域的兴起。大数据中的一个非常重要的议题是如何使用众多廉价的机器来实现可靠存储。
所谓廉价的机器就是发生故障的概率非常大,但单台的成本也非常低,分布式领域希望使用多台机器组成一个集群,将数据存储在多台机器上(副本),为了方便实现数据一致性,通常需要从一个复制组中挑选一台主节点用户处理数据的读写,其他节点从主节点拷贝数据,当主节点宕机,需要自动进行重新选举,实现高可用。
上述场景中有一个非常重要的功能Leader选举,如何选举出一个主节点、并支持主节点宕机后自动触发重新选举,实现主从自动切换,实现高可用。
使用Zookeeper提供的临时顺序节点与事件监听机制,能非常轻松的实现Leader选举。
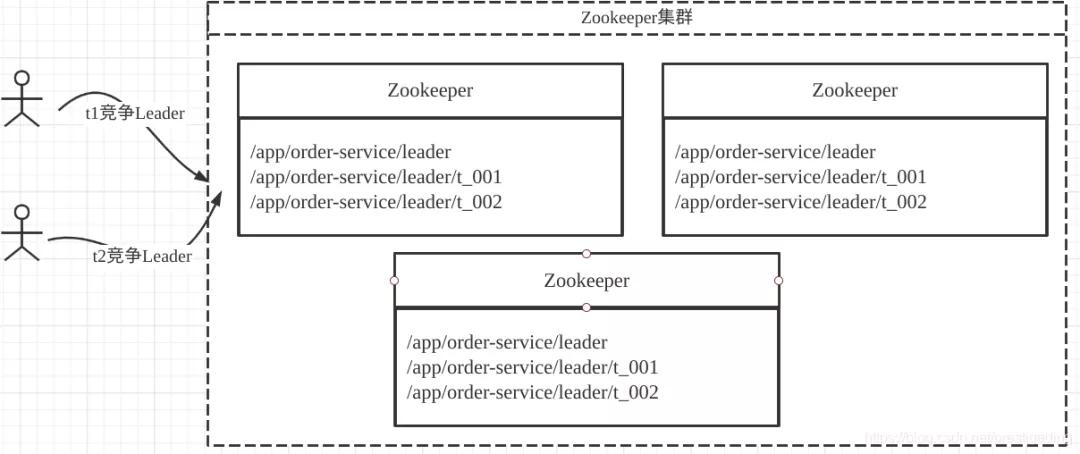
上面的t1,t2可以理解为一个组织中的多个成员,能提供相同的服务,但为了实现冷备效果(即同一时间只有一个成员对外提供服务,我们称之为Leader,当Leader宕机或停止服务后,该组织中的其他成名重新竞争Leader,然后继续对外提供服务)。
正如上图所示,Zookeeper是以集群部署的,能有效避免单点故障,并且集群内部提供了对数据的强一致性。
当成员需要竞争Leader时,借助Zookeeper的实现套路是向zookeeper中的一个数据节点(示例中为/app/order-service/leader)节点创建两个子节点,并且是顺序的临时节点。
客户端判断创建的节点的序号是否为/app/order-service/leader中序号最小的节点,如果是则成为Leader,对外提供服务;
如果序号不是最小的,则向自己前置的注册节点删除事件,一旦Leader代表的进程宕机,它与Zookeeper的会话失效后,与之关联的临时节点会被删除,一旦Leader创建的节点被删除,其后继节点会得到通知,从而再次触发选主,选举出新的Leader,继续对外提供服务,保质服务的高可用性。
回顾上述场景,借助Zookeeper能非常轻松的实现选主,为应用提高可用带来简便性,主要是利用了Zookeeper的几个特性:
- 临时节点
临时节点是与会话关联的,一点创建该临时节点的会话结束,与之会被自动删除,无需应用方人工删除。
- 顺序节点
- 事件机制
借助与事件机制,Zookeeper能及时通知存活的其他应用节点,重新触发选举,使得实现自动主从切换变的非常简单。
2、Kafka对Zookeeper的迫切需求
Kafka中存在众多的Leader选举,熟悉Kafka的朋友应该知道,一个主题可以拥有多个分区(数据分片),每一个数据分片可以配置多个副本,如何保证一个分区的数据在多个副本之间的一致性成为一个迫切的需求。
Kafka的实现套路就是一个分区的多个副本,从中选举出一个Leader用来承担客户端的读写请求,从节点从主节点处拷贝内容,Leader节点根据数据在副本中成功写入情况,进行抉择来确定是否写入成功。
Kafka中topic的分区分布示意图:
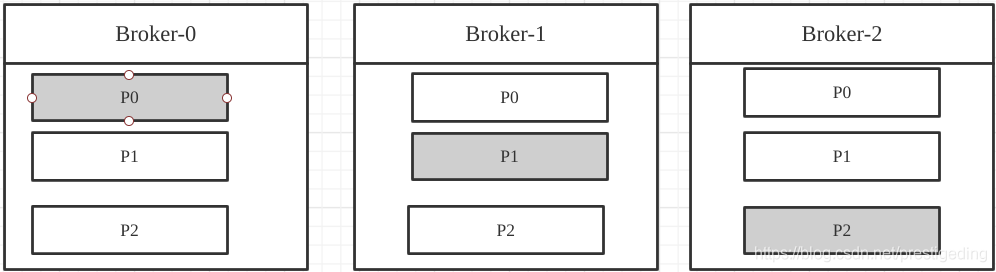
故此处需要进行Leader选举,而基于Zookeeper能轻松实现,从此一拍即合,开启了一段“蜜月之旅”。
3、Zookeeper的致命弱点
Zookeeper是集群部署,只要集群中超过半数节点存活,即可提供服务,例如一个由3个节点的Zookeeper,允许1个Zookeeper节点宕机,集群仍然能提供服务;一个由5个节点的Zookeeper,允许2个节点宕机。
但Zookeeper的设计是CP模型,即要保证数据的强一致性,必然在可用性方面做出牺牲。
Zookeeper集群中也存在所谓的Leader节点和从节点,Leader节点负责写,Leader与从节点可用接受读请求,但在Zookeeper内部节点在选举时整个Zookeeper无法对外提供服务。当然正常情况下选举会非常快,但在异常情况下就不好说了,例如Zookeeper节点发生full Gc,此时造成的影响将是毁灭性的。
Zookeeper节点如果频繁发生Full Gc,此时与客户端的会话将超时,由于此时无法响应客户端的心跳请求(Stop World),从而与会话相关联的临时节点将被删除,注意,此时是所有的临时节点会被删除,Zookeeper依赖的事件通知机制将失效,整个集群的选举服务将失效。
站在高可用性的角度,Kafka集群的可用性不仅取决于自身,还受到了外部组件的制约,从长久来看,显然都不是一个优雅的方案。
随着分布式领域相关技术的不断完善,去中心化的思想逐步兴起,去Zookeeper的呼声也越来越高,在这个进程中涌现了一个非常优秀的算法:Raft协议。
Raft协议的两个重要组成部分:Leader选举、日志复制,而日志复制为多个副本提供数据强一致性提供了强一致性,并且一个显著的特点是Raft节点是去中心化的架构,不依赖外部的组件,而是作为一个协议簇嵌入到应用中的,即与应用本身是融合为一体的。
再以Kafka Topic的分布图举例,引用Raft协议的示例图如下:
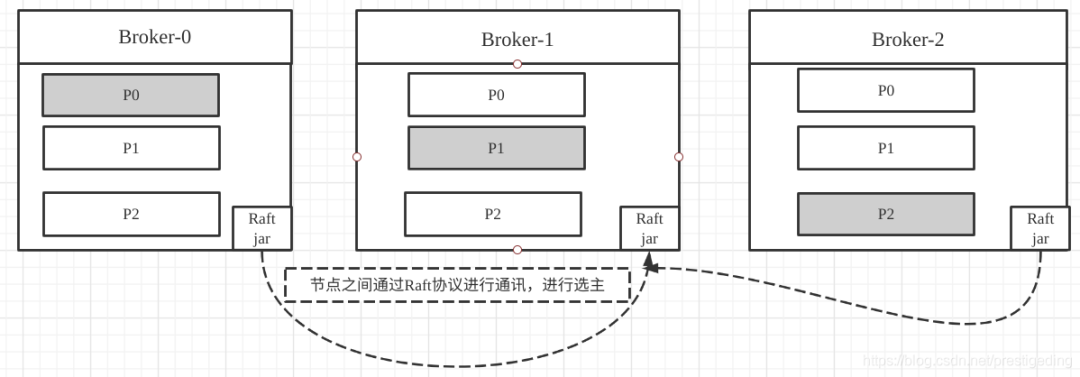
关于Raft协议,本文并不打算深入进行探讨,但为选主提供了另外一种可行方案,而且还无需依赖第三方组件,何乐而不为呢?故最终Kafka在2.8版本中正式废弃了Zookeeper,拥抱Raft。