【51CTO.com快译】数据挖掘(Data mining)是通过智能的方法,从数据中提取实用信息,对数据予以解释,发现数据的模式与关系,以及预测趋势和行为的过程。该过程往往会涉及到诸如:数据清理、机器学习、人工智能、数据分析、数据库系统、以及回归、聚类等信息统计技术。显然,数据集越大、越复杂,我们就能够越轻松地通过自动化分析工具,越快地找到越相关的意义。而通过识别和理解有意义的数据,用户企业也就可以做出各种明智的决策,并实现其目标。
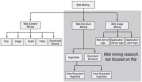
数据挖掘的基本步骤
我们可以将数据挖掘运用到诸如:市场细分、趋势分析、欺诈检测、数据库营销、信用风险管理、教育、以及财务分析等多种场景中。虽然各个组织使用的方法可能有所不同,但是总的说来,数据挖掘过程通常包括以下五个步骤:
- 根据既定的目标,确定业务需求。
- 识别数据源,以确定需要分析哪些数据点。
- 选择并应用建模技术。
- 评估模型,以确保其符合既定的目标。
- 报告数据挖掘的结果,或继续执行可重复的数据挖掘过程。
数据挖掘与数据仓库之间的区别
数据仓库是收集和管理数据的过程。它将各种不同来源的数据存储到一个存储库中,以供运营业务系统(如CRM系统)使用。该过程通常发生在数据挖掘之前,其优势包括:改进源系统中的数据质量,保护数据免受源系统更新的影响,具备集成多个数据源和数据优化的能力。
数据挖掘工具
如前所述,数据挖掘的过程会涉及到各种技术,其中包括流行的:回归分析(预测性)、关联规则发现(描述性)、聚类(描述性)和分类(预测性)。目前,随着市场的成熟、软件的升级、以及技术的迭代,我们可以选用带有不同算法的工具,来进行数据分析与挖掘。下面,我将和您从如下7个分类,综合介绍与比较21种常见的工具。
- 用于统计分析的集成类数据挖掘工具
- 开源的数据挖掘方案
- 大数据类数据挖掘工具
- 小型数据挖掘方案
- 用于云端数据挖掘的方案
- 使用神经网络的数据挖掘工具
- 用于数据可视化的数据挖掘工具
当然,其中的一些工具可能会横跨多个类别。例如,尽管Amazon EMR属于云端解决方案,但它同时也是处理大数据的绝佳工具。因此,我们尽量根据每种工具的最突出特性,进行分类。
在实际介绍各类工具之前,我们首先来简要了解两种最流行的数据科学编程语言:R和Python之间的区别。
R与Python
从源头上说,R是在考虑统计分析的前提下开发的;而Python则提供了一种更为通用的数据科学方法。从使用目的来看,R更专注于数据分析,并提供可灵活地使用的代码库。相反,Python的主要目标是部署到生产环境,它允许用户从头开始创建模型。就具体使用方法而言,R通常被集成到本地运行,而Python则能够与应用程序相集成。因此,尽管它们之间存在着差异,但是两种语言都可以处理大量的数据,并提供大量的代码库。
用于统计分析的集成类数据挖掘工具
1. IBM SPSS
SPSS(Statistical Package for the Social Sciences)是目前最流行的统计软件平台之一。自2015年开始提供统计产品和服务方案以来,该软件的各种高级功被广泛地运用于学习算法、统计分析(包括描述性回归、聚类等)、文本分析、以及与大数据集成等场景中。同时,SPPS允许用户通过各种专业性的扩展,运用Python和R来改进其SPSS语法。
IBM的SPSS
2. R
如前所述,R是一种编程语言,可用于统计计算与图形环境。它能够与UNIX、FreeBSD、Linux、macOS和Windows操作系统相兼容。R可以被运用在诸如:时间序列分析、聚类、以及线性与非线性建模等各种统计分析场景中。同时,作为一种免费的统计计算环境,它还能够提供连贯的系统,各种出色的数据挖掘包,可用于数据分析的图形化工具,以及大量的中间件工具。此外,它也是SAS和IBM SPSS等统计软件的开源解决方案。
3. SAS
SAS(Statistical Analysis System)是数据与文本挖掘(tex mining)及优化的合适选择。它能够根据组织的需求和目标,提供了多种分析技术和方法功能。目前,它能够提供描述性建模(有助于对客户进行分类和描述)、预测性建模(便于预测未知结果)和解析性建模(用于解析,过滤和转换诸如电子邮件、注释字段、书籍等非结构化数据)。此外,其分布式内存处理架构,还具有高度的可扩展性。
4. Oracle Data Mining
Oracle Data Mining(ODB)是Oracle Advanced Analytics的一部分。该数据挖掘工具提供了出色的数据预测算法,可用于分类、回归、聚类、关联、属性重要性判断、以及其他专业分析。此外,ODB也可以使用SQL、PL/SQL、R和Java等接口,来检索有价值的数据见解,并予以准确的预测。
开源的数据挖掘工具
5.KNIME
于2006年首发的开源软件KNIME(Konstanz Information Miner),如今已被广泛地应用在银行、生命科学、出版和咨询等行业的数据科学和机器学习领域。同时,它提供本地和云端连接器,以实现不同环境之间数据的迁移。虽然它是用Java实现的,但是KNIME提供了各种节点,以方便用户在Ruby、Python和R中运行它。
KNIME
6. RapidMiner
作为一种开源的数据挖掘工具,RapidMiner可与R和Python无缝地集成。它通过提供丰富的产品,来创建新的数据挖掘过程,并提供各种高级分析。同时,RapidMiner是由Java编写,可以与WEKA和R-tool相集成,是目前好用的预测分析系统之一。它能够提供诸如:远程分析处理,创建和验证预测模型,多种数据管理方法,内置模板,可重复的工作流程,数据过滤,以及合并与联接等多项实用功能。
7.Orange
Orange是基于Python的开源式数据挖掘软件。当然,除了提供基本的数据挖掘功能,Orange也支持可用于数据建模、回归、聚类、预处理等领域的机器学习算法。同时,Orange还提供了可视化的编程环境,以及方便用户拖放组件与链接的能力。
大数据类数据挖掘工具
从概念上说,大数据既可以是结构化的,也可以是非结构化、或半结构化的。它通常涵盖了五个V的特性,即:体量(volume,可能达到TB或PB级)、多样性(variety)、速度(velocity)、准确性(veracity)和价值(value)。鉴于其复杂性,我们对于海量数据的存储,模式的发现,以及趋势的预测等,都很难在一台计算机上处理与实现,因此需要用到分布式的数据挖掘工具。
8. Apache Spark
Apache Spark凭借着其处理大数据的易用性与高性能,而倍受欢迎。它具有针对Java、Python(PySpark)、R(SparkR)、SQL、Scala等多种接口,能够提供80多个高级运算符,以方便用户更快地编写出代码。另外,Apache Spark也提供了针对SQL and DataFrames、Spark Streaming、GrpahX和MLlib的代码库,以实现快速的数据处理和数据流平台。

在Apache Spark中使用Python的逻辑回归进行预测
9. Hadoop MapReduce
Hadoop是处理大量数据和各种计算问题的开源工具集合。虽然是用Java编写而成,但是任何编程语言都可以与Hadoop Streaming协同使用。其中MapReduce是Hadoop的实现和编程模型。它允许用户“映射(map)”和“简化(reduce)”各种常用的功能,并且可以横跨庞大的数据集,执行大型联接(join)操作。此外,Hadoop也提供了诸如:用户活动分析、非结构化数据处理、日志分析、以及文本挖掘等应用。目前,它已成为一种针对大数据执行复杂数据挖掘的广泛适用方案。
10.Qlik
Qlik是一个能够运用可扩展、且灵活的方法,去处理数据分析和挖掘的平台。它具有易用的拖放界面,并能够即时响应用户的修改和交互。为了支持多个数据源,Qlik通过各种连接器、扩展、内置应用、以及API集,实现与各种外部应用格式的无缝集成。同时,它也是集中式共享分析的绝佳工具。
小型数据挖掘方案
11. Scikit-learn
作为一款可用于Python机器学习的免费软件工具,Scikit-learn能够提供出色的数据分析和挖掘功能。它具有诸如分类、回归、聚类、预处理、模型选择、以及降维等多种功能。
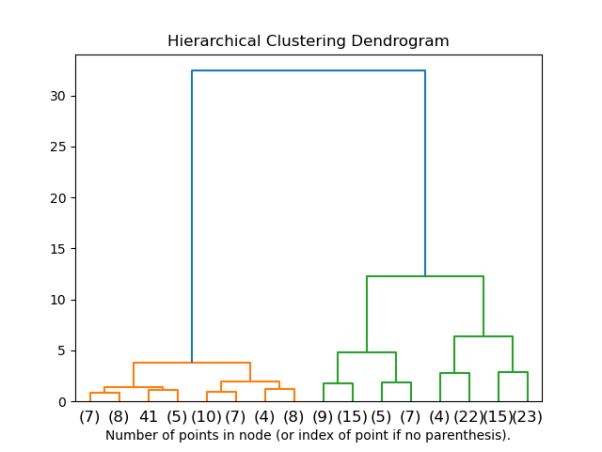
Scikitlern中的分层聚类
12.Rattle(R)
由R语言开发的Rattle,能够与macOS、Windows和Linux等操作系统相兼容。它主要被美国和澳大利亚的用户用于企业商业与学术目的。R的计算能力能够为用户提供诸如:聚类、数据可视化、建模、以及其他统计分析类功能。
13.Pandas(Python)
Pandas也是利用Python进行数据挖掘的“一把好手”。由它提供的代码库既可以被用来进行数据分析,又可以管理目标系统的数据结构。
14.H3O
作为一种开源的数据挖掘软件,H3O可以被用来分析存储在云端架构里的数据。虽然是由R语言编写,但是该工具不但能与Python兼容,而且可以用于构建各种模型。此外,得益于Java的语言支持,H3O能够被快速、轻松地部署到生产环境中。
用于云端数据挖掘的方案
通过实施云端数据挖掘技术,用户可以从虚拟的集成数据仓库中,检索到重要的信息,进而降低存储和基础架构的成本。
15.Amazon EMR
作为处理大数据的云端解决方案,Amazon EMR不仅可以被用于数据挖掘,还可以执行诸如:Web索引、日志文件分析、财务分析、机器学习等数据科学工作。该平台提供了包括Apache Spark和Apache Flink在内的各种开源方案,并且能够通过自动调整集群之类的任务,来提高大数据环境的可扩展性。
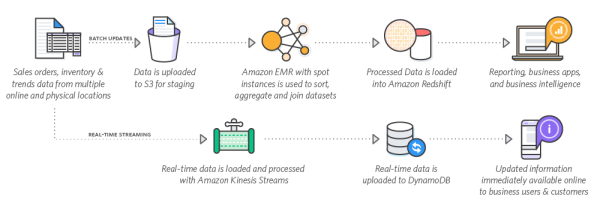
Amazon的大数据平台
16. Azure ML
作为一种基于云服务的环境,Azure ML可用于构建,训练和部署各种机器学习模型。针对各种数据分析、挖掘与预测任务,Azure ML可以让用户在云平台中对不同体量的数据进行计算和操控。
17. Google AI Platform
与Amazon EMR和Azure ML类似,基于云端的Google AI Platform也能够提供各种机器学习栈。Google AI Platform包括了各种数据库、机器学习库、以及其他工具。用户可以在云端使用它们,以执行数据挖掘和其他数据科学类任务。
使用神经网络的数据挖掘工具
神经网络主要是以人脑处理信息的方式,去处理数据。换句话说,由于我们的大脑有着数百万个处理外部信息,并随之产生输出的神经元,因此神经网络可以遵循此类原理,通过将原始数据转换为彼此相关的信息,以实现数据挖掘的目的。
18. PyTorch
Pytorch既是一个Python包,也是一个基于Torch库的深度学习框架。它最初是由Facebook的AI研究实验室(FAIR)开发的,属于深层的神经网络类数据科学工具。用户可以通过:加载数据,预处理数据,定义模型,执行训练和评估,这样的数据挖掘步骤,通过Pytorch对整个神经网络进行编程。此外,借助强大的GPU加速能力,Torch可以实现快速的阵列计算。截至2020年9月,torch的R生态系统(https://torch.mlverse.org/)中已包含有torch、torchvision、torchaudio、以及其他扩展。
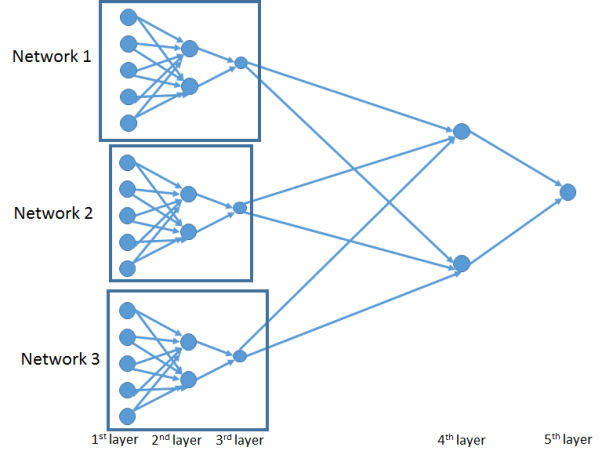
PyTorch的神经网络
19. TensorFlow
与PyTorch相似,由Google Brain Team开发的TensorFlow也是基于Python的开源机器学习框架。它既可以被用于构建深度学习模型,又能够高度关注深度神经网络。TensorFlow生态系统不但能够灵活地提供各种库和工具,而且拥有一个广泛的流行社区,开发人员可以进行各种问答和知识共享。尽管属于Python库,但是TensorFlow于2017年开始对TensorFlow API引入了R接口。
用于数据可视化的数据挖掘工具
数据可视化是对从数据挖掘过程中提取的信息,予以图形化表示。此类工具能够让用户通过图形、图表、映射图、以及其他可视化元素,直观地了解数据的趋势、模型和异常值。
20. Matplotlib
Matplotlib是使用Python进行数据可视化的出色工具库。它允许用户利用交互式的图形,来创建诸如:直方图、散点图、3D图等质量图表。而且这些图表都可以从样式、轴属性、字体等方面被自定义。
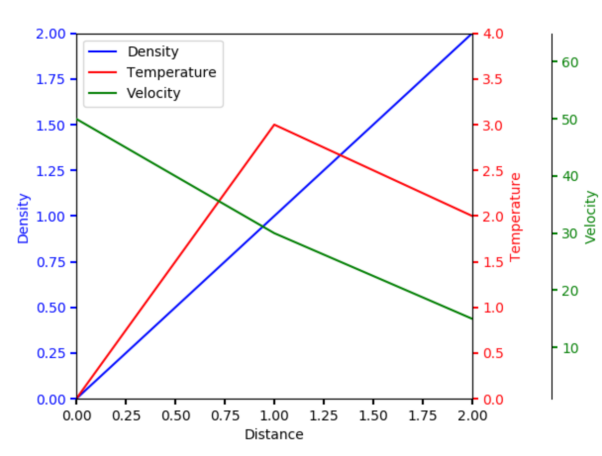
Matplotlib的图表示例
21. ggplot2
ggplot2也是一款广受欢迎的数据可视化R工具包。它允许用户构建出各类高质量且美观的图形。同时,用户也可以通过该工具,高度抽象地修改图中的各种组件。
小结
如前所述,大多数数据挖掘工具或方案,都用到了R和Python两种主要编程语言,也用到了各种相应的包和库。对于从事数据挖掘的开发人员或数据科学家来说,学习和了解各种类型的数据分析与挖掘工具,是非常必要的。当然,具体如何选择合适的工具,则取决于您当前的业务或研究目标。
原文标题:Top 21 Data Mining Tools,作者: Mariana Berga, Alicja Ochman, Pedro Coelho
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】