【51CTO.com快译】
了解AI,机器学习和深度学习的发展
首先,有一点背景...
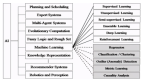
深度学习是机器学习的子集,而机器学习又是人工智能的子集,但是这些名称的起源来自一个有趣的历史。此外,还有一些引人入胜的技术特征,可将深度学习与其他类型的机器学习区分开来……对于技能水平较高的ML、DL或AI的任何人来说,这都是必不可少的工作知识。
如果你希望在2021年提高你的技能或指导商业/研究策略,你可能会遇到谴责深度学习中技能短缺的文章。几年前,你也会读到同样的关于缺乏具备机器学习技能的专业人士的文章,而就在几年前,人们会把重点放在缺乏精通“大数据”的数据科学家上。
同样,多年来,我们已经听到吴安德(Andrew Ng)告诉我们,“人工智能是新的电力”,并且不断建议人工智能在商业和社会中的出现与 工业革命产生相似的影响。尽管可以说对技能短缺的警告被 夸大了,但为什么我们似乎改变了关于最需要什么技能的想法的速度,而这些想法却比最初可以填补的角色更快?
更广泛地说,受益于20/20后见之明,多年来人工智能研究为何会有如此多的不同名称和名称?
截至撰写本文时,在工作网站Indeed.com上搜索“深度学习”时,命中率约为49,000。这有点好笑,因为深度学习是机器学习的一个子集,而机器学习又是人工智能的一个领域,搜索机器学习和人工智能分别创造了约40,000个和约39,000个工作。
如果深度学习是人工智能的一部分,为什么对后者开放的工作岗位要少20%左右?答案是,我们在这些领域使用的术语往往与趋势和市场化程度有关,也与任何实质性差异有关。这并不是说我们不能根据技术特性来区分不同的类别,我们也会这样做!
事实上,深度学习与“经典”机器学习(包括浅层神经网络和统计学习)之间存在一些非常有趣的新兴特征。在我们谈论这些之前,让我们先来回顾一下人工智能的历史,在这里我们会看到,各种人工智能术语的流行在很大程度上与在后来落空之前产生高期望值有关,并最终在新想法导致旧问题的新解决方案时重新树立信誉。
达特茅斯研讨会:人工智能得名
达特茅斯研讨会是1956年由少数著名数学家和科学家举办的夏季会议。
这个研讨会被广泛认为是人工智能领域的奠基之作,它把许多不同的学科以不同的名称(每个学科都有自己的概念基础)聚集在人工智能的保护伞下。在1955年约翰麦卡锡提出这个会议之前,思考机器的想法是在自动机理论和控制论等不同的方法下进行的。出席的有克劳德·香农、约翰·纳什和马文·明斯基等知名人士。达特茅斯研讨会不仅将智能机器相关的几个独立研究领域联系在一起,还对未来十年的研究提出了雄心勃勃的期望。
事实证明,这些雄心壮志最终将以失望和第一个人工智能冬天而告终——这个词用来描述人工智能炒作周期中时起时落的平静。
1973年,英国的詹姆斯·莱特希尔爵士(Sir James Lighthill)教授撰写了《人工智能:总体调查》,也称为《莱特希尔报告》。在他的报告中,Lighthill描述了人工智能研究的三个类别:A、B和C。虽然他描述了A和C类(高级自动化和计算神经科学)中的一些未达到的期望,但Lighthill描述了该领域在非常明显的B类(又名机器人)中最明显的不足。Lighthill的报告,连同一篇论文,展示了早期形式的浅层神经网络的一些缺点,由Marvin Minsky和Seymour Paypert设计的感知器,直到今天都被认为是70年代开始流行的人工智能冬天的主要先兆。
“所有这些工作的学生都普遍认为,期望在20世纪开发出能够以学习或自组织模式有效处理大型知识库的高度通用系统是不现实的。”—詹姆斯·莱特希尔,《人工智能:综述》
联结主义与80年代人工智能的回归
不久,人们对人工智能的兴趣又恢复了,在上世纪80年代,资金也开始悄悄地回到这个领域。尽管神经网络和感知器领域在第一次明显失宠(许多人指责明斯基和佩珀特),但这一次它们将发挥主要作用。也许是为了远离先前的失望,神经网络将以一个新的绰号:连接主义的名义重新进入合法的研究。
事实上,在现代深度学习时代,许多最知名的名字,如Jürgen Schmidhuber、Yann LeCun、Yoshua Bengio和Geoffrey Hinton,在20世纪80年代和90年代初都在做反向传播和消失梯度问题等基础性工作,但80年代人工智能研究的真正头条是人工智能领域专家系统。与莱特希尔在报告中批评的“宏大主张”不同,专家系统实际上提供了可量化的商业利益,如卡内基梅隆大学开发的XCON。
XCON是一个专家系统,据报道每年为数字设备公司节省了4000万美元。随着XCON等系统和一些知名游戏系统的应用,商业研发实验室和政府项目的资金都回到了人工智能上。然而,这不会持续很久。
组合爆炸仍然是一个未解决的挑战,现实世界场景的复杂性变得难以列举。尤其是专家系统太脆弱,无法处理不断变化的信息,而且更新它们的成本很高。同样,令人信服和有能力的机器人也不见踪影。
罗德尼·布鲁克斯(Rodney Brooks)和汉斯·莫拉维克(Hans Moravec)等机器人学家开始强调,,费尽心思将人类专家知识提炼成计算机程序的手工工作不足以解决人类最基本的技能,例如在繁忙的人行道上导航或在嘈杂的人群中寻找朋友。很快,在我们现在所知的莫拉维克悖论下,很明显,对于人工智能来说,简单的事情是困难的,而像计算一大笔钱或玩专家跳棋这样困难的事情则相对容易。
专家系统被证明是脆弱且昂贵的,这为令人失望的舞台打下了基础,但与此同时,基于学习的人工智能却日渐盛行,许多研究人员开始涌向这一领域。他们对机器学习的关注包括神经网络,以及各种各样的其他算法和模型,如支持向量机、聚类算法和回归模型。
从1980年代到1990年代的转变被某些人视为第二个AI冬季,实际上在此期间关闭了数百家AI公司和部门。这些公司中有许多都参与了当时高性能计算(HPC)的建设,而它们的关闭表明 摩尔定律将 在AI进步中发挥重要作用。
由IBM在1990年代后期开发的国际象棋冠军系统Deep Blue并非由更好的专家系统提供支持,而是由支持计算的 alpha-beta搜索提供支持。当您可以从家用台式机获得相同的性能时,为什么还要为专用的 Lisp机器支付高价呢?
尽管随着晶体管达到物理极限,摩尔定律已基本放缓,但工程改进仍继续在NVIDIA和AMD引领下实现现代AI的新突破。现在,专为最能支持现代深度学习模型的组件而设计的一站式AI工作站,与几年前最先进的硬件相比,其迭代速度有很大的不同。
神经网络在现实世界中的应用
然而,在研究和实际应用方面,上世纪90年代初确实更像是一个缓慢酝酿的时期。那时,未来的图灵奖得主正在进行开创性的工作,而神经网络很快将被应用于光学字符识别的实际应用中,用于邮件分拣等任务。LSTMs在1997年针对消失梯度问题取得了进展,并且在神经网络和其他机器学习方法方面继续进行有意义的研究。
机器学习这个术语继续流行,也许是严肃的研究人员为了远离与人工智能相关的过于雄心勃勃的主张(以及科幻小说的污名)而做出的努力。稳步的进步和硬件的改进继续推动人工智能在新千年的发展,但直到采用高度并行的图形处理单元(GPU)作为神经网络的自然并行数学原语,我们才进入了现代深度学习时代。
现代人工智能:深度学习即将到来
当思考人工智能深度学习时代的开始时,我们中的许多人都会提到Alex Krizhevsky等人在2012年ImageNet大规模视觉识别挑战赛上的成功以及他们的GPU训练模型。虽然按照今天的标准,所谓的AlexNet在规模上是适度的,但它在各种方法的竞争领域中果断地胜出。
从那时起,这项挑战的成功者都是建立在卷积神经网络相似原理的基础上的,因此在动物视觉系统中,卷积网络的许多特性和训练过程中学习到的核权值具有相似性也就不足为奇了。
AlexNet并不是一个特别深的卷积神经网络,它从尖端到尾部横跨8层,仅比LeNet-5(pdf)的深度深3层,LeNet-5是20多年前描述的一种卷积网络。相反,AlexNet的主要贡献是证明了在GPU上进行培训既可行又非常值得。
在AlexNet开发的直接沿袭中,我们现在专门设计了GPU,以支持更快、更有效的深度神经网络训练。
AlexNet已成为人工智能突破的原型
2012年ILSVRC和AlexNet在竞赛中的表现是非常具有标志性的,以至于它已成为过去十年人工智能突破的原型。
不论好坏,人们都在谈论自然语言处理时, 机器人技术和步态分析的“ ImageNet时刻” ,仅举几例。从那时起,我们已经取得了长足的进步,深度学习模型在玩游戏、生成令人信服的文本以及其他属于前面提到的Moravec悖论中提到的“简单就是困难”任务类型的类别中,展示了接近人类的表现或更好的表现。
深度学习也为基础科学研究做出了贡献,并在2020年为蛋白质结构预测生物学的根本挑战做出了明确贡献。
硬件加速使得训练深度和广度的神经网络成为可能,但这并不能解释为什么或者甚至解释为什么较大的模型比较小的模型产生更好的结果。杰弗里·欣顿(Geoffrey Hinton)被广泛认为是现代深度学习时代的先驱之一,他在他的《机器学习神经网络MOOC》中提出,使用神经网络进行机器学习在7个层次上变成了深度学习。
我们不认为这是一个错误的经验法则,接近深度学习范式的开始,但我们认为,我们可以通过考虑深度学习模型的训练方式与其他形式的机器学习方式的不同,更有意义地划清界限。
另外值得注意的是,虽然深度学习通常指由多层完全连接或卷积的神经层组成的模型,但该术语也包括神经常微分方程或神经细胞自动机等模型。
正是计算的复杂性和操作的深度使得深度学习成为可能,而层不一定需要由人工神经元组成。
脱离偏差-方差权衡与深度学习
统计学习是机器学习的一个子集,本文中尚未提及,但它仍然是数百万数据和基础研究科学家的一个重要专业领域。
在统计学习和机器学习中,对于较小的模型和数据集最重要的概念之一是偏差-方差权衡。偏差对应于对训练数据的拟合不足,通常是模型没有拟合能力来表示数据集中的模式的症状。
另一方面,方差对应的模型与训练数据拟合得太好,以至于对验证数据的泛化能力很差。更容易记住的同义词是“欠适合/过适合”。
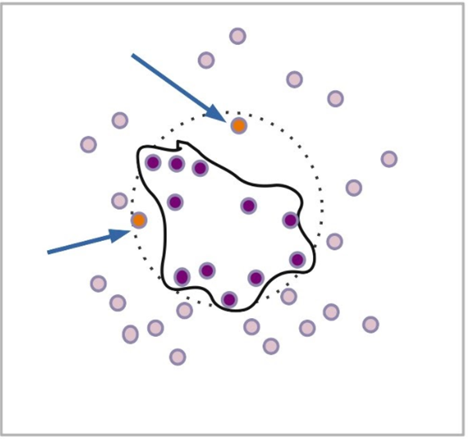
在简单的分类问题中过度拟合的卡通示例。深紫色斑点表示训练数据,黑色决策边界已被过度拟合。较浅的紫色圆点已被正确排除在决策边界之外,但是训练集中未出现的两个橙色斑点(见箭头)被错误地归类为外部群组。背景中的虚线表示真实的分类边界。
对于统计模型和浅层神经网络,我们通常可以将拟合不足解释为模型过小的症状,而过度拟合则认为模型过大。当然,有很多不同的策略可以对模型进行正则化,以使其表现出更好的概括性,但是我们将把讨论主要放在另一时间。
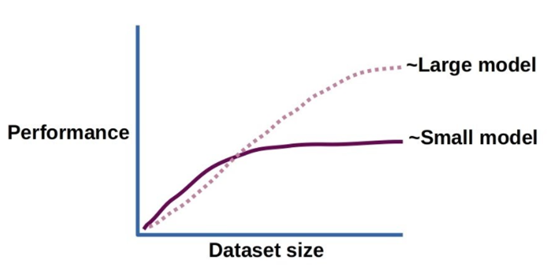
较大模型利用较大数据集的能力的卡通表示。图片由作者提供。
训练数据和验证数据集模型性能的差异往往表现出过度拟合现象,并且随着训练次数的增加/模型的增加,这种偏差会变得更糟。然而,当模型和数据集都变得更大时,会出现一个有趣的现象。这种令人着迷的双下降紧急特性指的是性能改善的最初阶段,随后由于过度拟合而降低性能,但最终被性能更好的替代。这是随着模型深度、宽度或训练数据的增加而发生的,这可能是最合理的地方,来区分深度学习和较浅的神经网络。
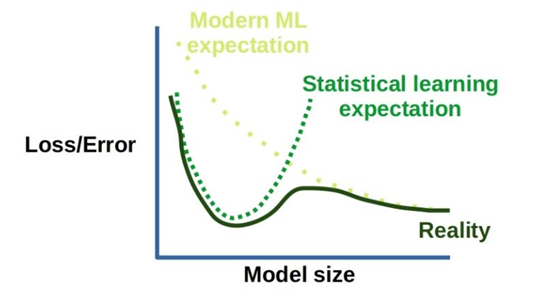
深双下降的卡通表现,图片由作者提供。
推广,而像辍学这样的正则化技术往往会产生更好的结果。诸如 彩票假设之类的深度学习的其他特征可能是相关的。
人工智能子领域的总结历史和理论基础
到此,我们结束了对AI几个子领域的历史和原理的讨论,以及它们在历史的不同阶段所被称为的内容。
我们还讨论了深度学习模型的一个有趣的识别特征,当我们直觉地期望它们大规模过拟合时,它可以随着规模或数据的增加而不断改进。当然,如果您要向投资者/经理/资金提供者介绍项目,或者向潜在的雇主介绍自己,那么您可能需要从营销角度考虑术语。
在这种情况下,您可能希望将自己的工作描述为AI,向公众描述,作为深度学习,向投资者描述,以及在会议上将您的同事和同事描述为机器学习。
来源:DZone 原文链接:https://dzone.com/articles/disentangling-ai-machine-learning-and-deep-learnin
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】