图片来自 Pexels
系统介绍
系统架构见下图:
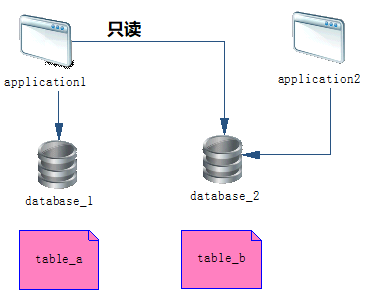
application1 和 application2 是一个分布式系统中的 2 个应用。
application1 连接的数据库是 database1,application2 连接的数据库是 database2,application2 生产的数据要给 application1 做跑批使用。
application1 要获取 database2 的数据,并不是通过接口来获取的,而是直连 database2 来获取,因此 application1 也具有 database2 库的读权限。
database2 中有 1 张表 table_b,里面保存的数据是 application1 跑批需要的数据。
application1 查找到 table_b 的数据后,先保存到 database1 的数据库表 table_a 中,等跑批时取出来用。
table_a 和 table_b 的表结构如下:
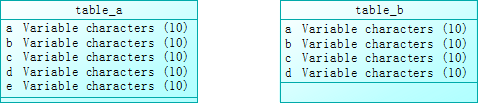
2 个表的主键都是字段 a,application1 查询出 table_b 的数据后,会根据主键a来判断这条数据是否存在,如果数据存在,就更新,否则,就插入。
application1 使用的 orm 框架是 MyBatis,为了减少应用和数据库的交互,使用了 Oracle 的 merge 语句。
注意,mybatis 相关的文件有 5 个:
- TableAMapper.java
- TableBMapper.java
- TableAMapper.xml
- TableBMapper.xml
- TableAEntity.java
熟悉 MyBatis 的同学应该都知道,前两个 Java 类是 SQL 操作接口类,第 3、4 两个文件是存放 SQL 的 XML 文件,跟前两个文件对应,最后一个 Java 文件是 do 类。
事故现场
TableBMapper 中有一个方法 selectForPage,用来按页查询 table_b 中数据,每页 1 万条数据,之后把这个 list 结果 merge 到 table_a。
看一下代码:
- //从table_b按每页1万条来查询数据
- List<TableAEntity> list = tableBMapper.selectForPage(startPage, 10000);
- //把查到的数据一次性merge到table_a中
- tableAMapper.mergeFromTableB(list);
我们再看一下 TableAMapper.xml 中的 mergeFromTableB 方法。
代码如下:
- <update id="mergeFromTableB" parameterType="list">
- <foreach collection="list" item="item" index="index" separator=";" close=";end;" open="begin">
- MERGE INTO table_a ta USING(select #{item.a} as a,#{item.b} as b,#{item.c} as c, #{item.d} as d from dual) tb
- on (ta.a = tb.a)
- WHEN MATCHED THEN UPDATE set
- ta.b=tb.b,
- ta.c=tb.c,
- ta.d=tb.d
- WHEN NOT MATCHED THEN insert(
- a,
- b,
- c,
- d
- )
- values (
- tb.a,
- tb.b,
- tb.c,
- tb.d
- )
- </foreach>
- </update>
注意:为了文章排版,我对表结构做了简化,真实案例中 table_a 这张表有 60 多个字段。
这条 SQL 执行后,我截取部分 Oracle 的日志,如下:
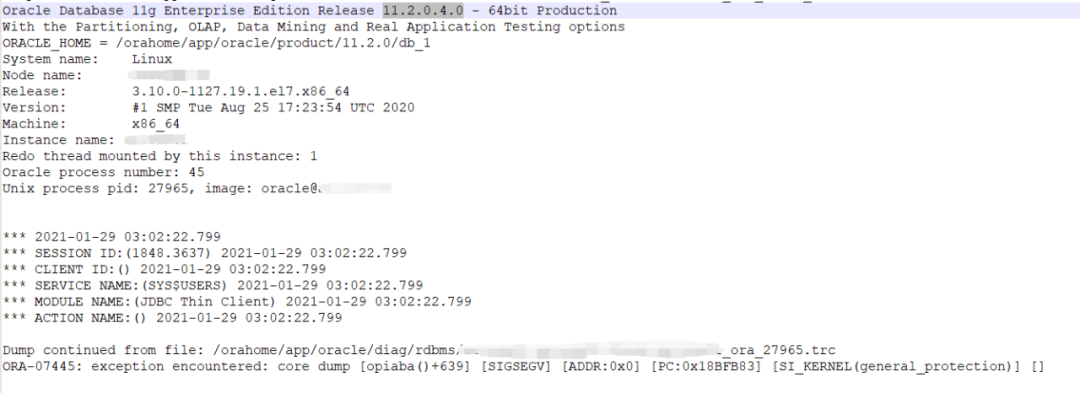
图中可以看到 Oracle 报了 ORA-07445 错误。
分析日志后发现,SQL 绑定变量达到了了 79010 个,而 Oracle 是不允许超过 65535 个的。
解决方案
前面的分析确定了导致 Oracle 挂掉的原因是绑定变量超过了 65535 个,那对症下药,解决的方案有 3 个:
业务系统方案
①循环单条执行 merge 语句,优点是修改简单,缺点是业务系统跟数据库交互太多,会影响跑批任务执行效率。
②对 mergeFromTableB 进行分批调用,比如每 1000 条调用一次 merge 方法,改造稍微多一点,但是交互会少很多。
DBA 方案
给 Oracle 打一个补丁,这个方案需要停服务。
业务方案 2 明细有优势,我用这个方案进行了改造,每次 1000 条,批量 merge。
代码如下:
- for (int i = 0; i < list.size(); i += 1000) {
- if (i + 1000 < list.size()) {
- tableAMapper.mergeFromTableB(list.subList(i, i + 1000));
- } else {
- tableAMapper.mergeFromTableB(list.subList(i, list.size()));
- }
- }
新的问题
按照上面的方案改造完成后,数据库不会奔溃了,但是新的问题出现了。测试的同学发现,每次处理超过 1000 条数据,非常耗时,有时竟然达到了 4 分钟,惊呆。
看打印的批量 SQL,类似于下面的语句:
- begin
- merge into table_a ta USING(...;
- merge into table_a ta USING(...;
- end;
分析了一下,虽然放在了一个 SQL 块中,但还是单条执行,最后一起提交。再做一次优化,把上面多条 merge 语句合成 1 条。
我的优化思路是创建一张临时表,先把 list 中的数据插入到临时表中,然后用一次 merge 把临时表的数据 merge 进 table_a 这张表。
Oracle 的临时表有 2 种,一种是会话级别,一种是事务级别:
- 会话级别的临时表,数据会在整个会话的生命周期中,会话结束,临时表数据清空。
- 事务级别的临时表,数据会在整个事务执行过程中,事务结束,临时表数据清空。
下面看具体实施过程:
①我们创建一张会话临时表,SQL 如下:
- create global temporary table_a_temp on commit delete rows as select * from table_a;
- comment on table_a_temp is 'table_a表临时表';
②把 table_b 查询到的数据 list 插入临时表,需要在 TableAMapper.xml 增加一个方法:
- <insert id="batchInsertTemp" parameterType="list">
- insert all
- <foreach collection="list" index="index" item="item">
- into table_a_temp
- <trim prefix="(" suffix=")" suffixOverrides="," >
- a,
- <if test="item.b != null" >
- b,
- </if>
- <if test="item.c != null" >
- c,
- </if>
- <if test="item.d != null" >
- d,
- </if>
- </trim>
- <trim prefix="values (" suffix=")" suffixOverrides="," >
- #{item.a},
- <if test="item.b != null" >
- #{item.b,jdbcType=VARCHAR},
- </if>
- <if test="item.c != null" >
- #{item.c,jdbcType=VARCHAR},
- </if>
- <if test="item.d != null" >
- #{item.d,jdbcType=VARCHAR},
- </if>
- </trim>
- </foreach>
- select 1 from dual
- </insert>
注意:Oracle 的 insert all 语句单次插入不能超过 1000 条。
③把临时表的数据 merge 到 table_a 中,需要在 TableAMapper.xml 增加一个方法:
- <update id="mergeFromTempData">
- MERGE INTO table_a ta
- USING (select * from table_a_temp) tb
- on (ta.a = tb.a)
- WHEN MATCHED THEN UPDATE set
- ta.b = tb.b,
- ta.c = tb.c,
- ta.d = tb.d
- WHEN NOT MATCHED THEN
- insert
- (a, b, c, d)
- values
- (tb.a, tb.b, tb.c, tb.d)
- </update>
④最终业务代码修改如下:
- //从table_b查询
- List<TableAEntity> list = tableBMapper.selectForPage(startPage, 10000);
- //批量插入table_a_temp临时表
- for (int i = 0; i < list.size(); i += 1000) {
- if (i + 1000 < list.size()) {
- tableAMapper.batchInsertTemp(list.subList(i, i + 1000));
- } else {
- tableAMapper.batchInsertTemp(list.subList(i, list.size()));
- }
- }
- //从table_a_temp把数据merge到table_a
- tableAMapper.mergeFromTempData();
总结
在 Oracle 上执行 SQL 时,如果绑定变量的数量超过了 65535,会引发 ORA-07445。当然,引发 ORA-07445 的原因还有其他。
解决这个问题最好的方式是从业务代码层面进行修改。也可以让 DBA 可以给 Oracle 打一个补丁,但是 Oracle 必须要停服务。
延伸阅读:
https://community.oracle.com/tech/apps-infra/discussion/2424571/ora-07445-exception-encountered-core-dump-ptmak-106-sigsegv-addres
作者:jinjunzhu
编辑:陶家龙
出处:转载自公众号程序员 jinjunzhu