












我们知道多线程能并发的处理多个任务,有效地提高复杂应用程序的性能,在实际开发中扮演着十分重要的角色
但是使用多线程也带来了很多风险,并且由线程引起的问题往往在测试中难以发现,到了线上就会造成重大的故障和损失
下面我会结合几个实际案例,帮助大家在工作做规避这些问题
多线程问题
首先介绍下使用的多线程会有哪些问题
使用多线程的问题很大程度上源于多个线程对同一变量的操作权,以及不同线程之间执行顺序的不确定性
《Java并发编程实战》这本书中提到了三种多线程的问题:安全性问题、活跃性问题和性能问题
安全性问题
例如有一段很简单的扣库存功能操作,如下:
- public int decrement(){
- return --count;//count初始库存为10
- }
在单线程环境下,这个方法能正确工作,但在多线程环境下,就会导致错误的结果
--count看上去是一个操作,但实际上它包含三步(读取-修改-写入):
- 读取count的值
- 将值减一
- 最后把计算结果赋值给count
如下图展示了一种错误的执行过程,当有两个线程1、2同时执行该方法时,它们读取到count的值都是10,最后返回结果都是9;意味着可能有两个人购买了商品,但库存却只减了1,这对于真实的生产环境是不可接受的
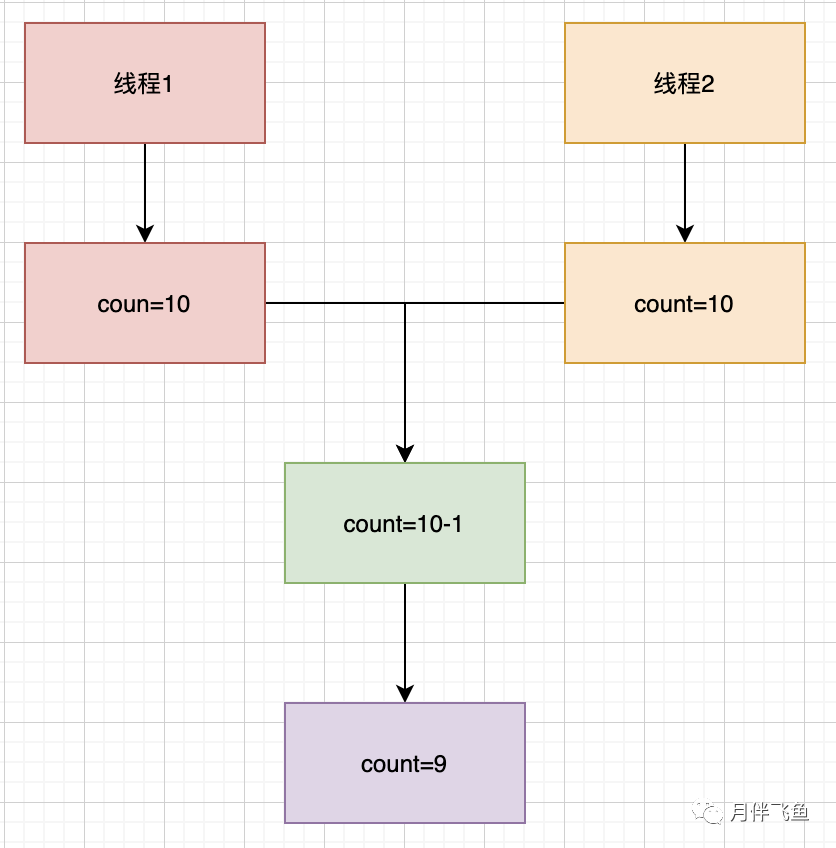
像上面例子这样由于不恰当的执行时序导致不正确结果的情况,是一种很常见的并发安全问题,被称为竞态条件
decrement()方法这个导致发生竞态条件的代码区被称为临界区
避免这种问题,需要保证读取-修改-写入这样复合操作的原子性
在Java中,有很多方式可以实现,比如使用synchronize内置锁或ReentrantLock显式锁的加锁机制、使用线程安全的原子类、以及采用CAS的方式等
活跃性问题
活跃性问题指的是,某个操作因为阻塞或循环,无法继续执行下去
最典型的有三种,分别为死锁、活锁和饥饿
死锁
最常见的活跃性问题是死锁
死锁是指多个线程之间相互等待获取对方的锁,又不会释放自己占有的锁,而导致阻塞使得这些线程无法运行下去就是死锁,它往往是不正确的使用加锁机制以及线程间执行顺序的不可预料性引起的

如何预防死锁
1.尽量保证加锁顺序是一样的
例如有A,B,C三把锁。
- Thread 1的加锁顺序为A、B、C这样的。
- Thread 2的加锁顺序为A、C,这样就不会死锁。
如果Thread2的加锁顺序为B、A或者C、A这样顺序就不一致了,就会出现死锁问题。
2.尽量用超时放弃机制
Lock接口提供了tryLock(long time, TimeUnit unit)方法,该方法可以按照固定时长等待锁,因此线程可以在获取锁超时以后,主动释放之前已经获得的所有的锁。可以避免死锁问题
活锁
活锁与死锁非常相似,也是程序一直等不到结果,但对比于死锁,活锁是活的,什么意思呢?因为正在运行的线程并没有阻塞,它始终在运行中,却一直得不到结果
饥饿
饥饿是指线程需要某些资源时始终得不到,尤其是CPU 资源,就会导致线程一直不能运行而产生的问题。
在 Java 中有线程优先级的概念,Java 中优先级分为 1 到 10,1 最低,10 最高。
如果我们把某个线程的优先级设置为 1,这是最低的优先级,在这种情况下,这个线程就有可能始终分配不到 CPU 资源,而导致长时间无法运行。
性能问题
线程本身的创建、以及线程之间的切换都要消耗资源,如果频繁的创建线程或者CPU在线程调度花费的时间远大于线程运行的时间,使用线程反而得不偿失,甚至造成CPU负载过高或者OOM的后果
举例说明
线程不安全类
案例1
使用线程不安全集合(ArrayList、HashMap等)要进行同步,最好使用线程安全的并发集合
在多线程环境下,对线程不安全的集合遍历进行操作时,可能会抛出ConcurrentModificationException的异常,也就是常说的fail-fast机制
下面例子模拟了多个线程同时对ArrayList操作,线程t1遍历list并打印,线程t2向list添加元素
- List<Integer> list = new ArrayList<>();
- list.add(0);
- list.add(1);
- list.add(2); //list: [0,1,2]
- System.out.println(list);
- //线程t1遍历打印list
- Thread t1 = new Thread(() -> {
- for(int i : list){
- System.out.println(i);
- }
- });
- //线程t2向list添加元素
- Thread t2 = new Thread(() -> {
- for(int i = 3; i < 6; i++){
- list.add(i);
- }
- });
- t1.start();
- t2.start();

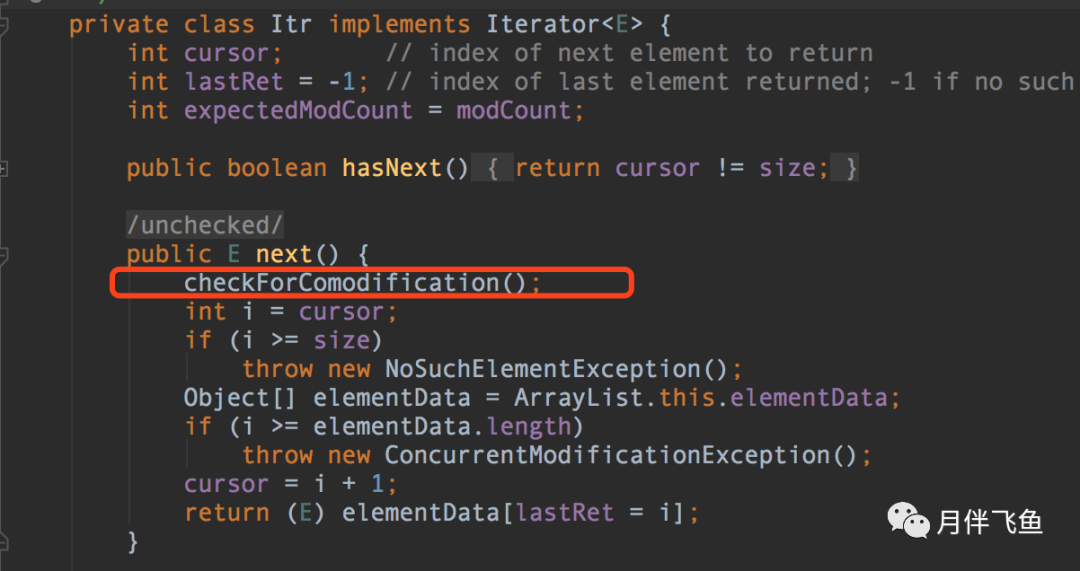
进到抛异常的ArrayList源码中,可以看到遍历ArrayList是通过内部实现的迭代器完成的
调用迭代器的next()方法获取下一个元素时,会先通过checkForComodification()方法检查modCount和expectedModCount是否相等,若不相等则抛出ConcurrentModificationException

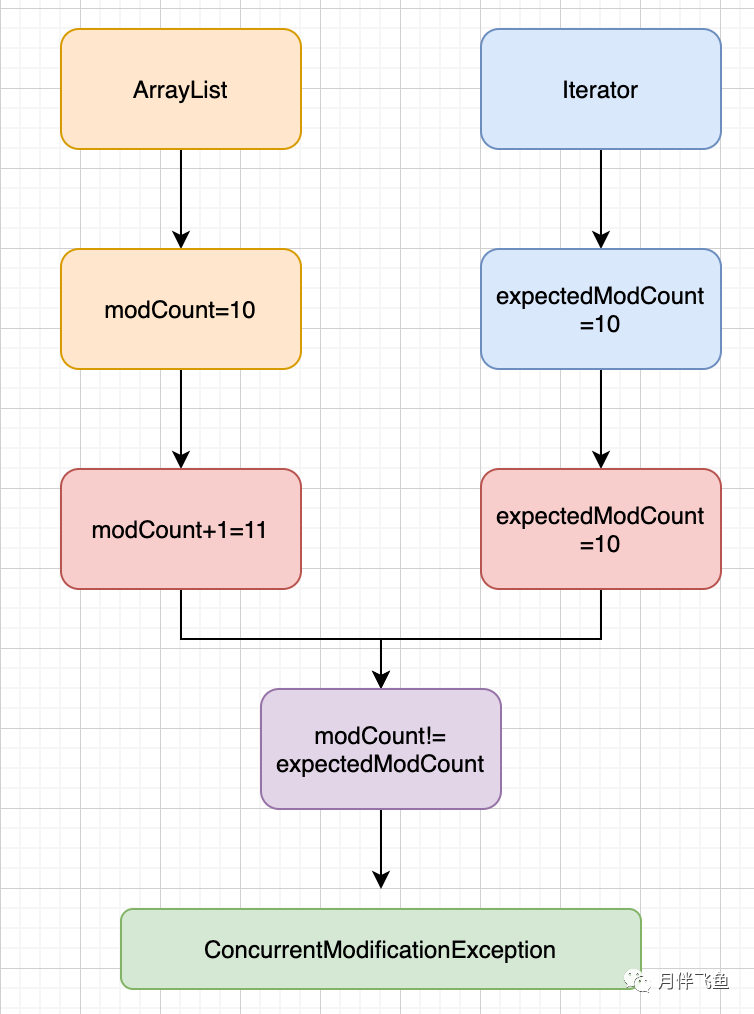
modCount是ArrayList的属性,表示集合结构被修改的次数(列表长度发生变化的次数),每次调用add或remove等方法都会使modCount加1
expectedModCount是迭代器的属性,在迭代器实例创建时被赋与和遍历前modCount相等的值(expectedModCount=modCount)
所以当有其他线程添加或删除集合元素时,modCount会增加,然后集合遍历时expectedModCount不等于modCount,就会抛出异常
使用加锁机制操作线程不安全的集合类
- List<Integer> list = new ArrayList<>();
- list.add(0);
- list.add(1);
- list.add(2);
- System.out.println(list);
- //线程t1遍历打印list
- Thread t1 = new Thread(() -> {
- synchronized (list){ //使用synchronized关键字
- for(int i : list){
- System.out.println(i);
- }
- }
- });
- //线程t2向list添加元素
- Thread t2 = new Thread(() -> {
- synchronized (list){
- for(int i = 3; i < 6; i++){
- list.add(i);
- System.out.println(list);
- }
- }
- });
- t1.start();
- t2.start();
如上面代码,用synchronized关键字锁住对list的操作,就不会抛出异常。不过用synchronized相当于把锁住的代码块串行化,性能上是不占优势的
推荐使用线程安全的并发工具类
JDK1.5加入了很多线程安全的工具类供使用,如CopyOnWriteArrayList、ConcurrentHashMap等并发容器
日常开发中推荐使用这些工具类来实现多线程编程
案例2
不要将SimpleDateFormat作为全局变量使用
SimpleDateFormat实际上是一个线程不安全的类,其根本原因是SimpleDateFormat的内部实现对一些共享变量的操作没有进行同步
- public static final SimpleDateFormat SDF_FORMAT = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- public static void main(String[] args) {
- //两个线程同时调用SimpleDateFormat.parse方法
- Thread t1 = new Thread(() -> {
- try {
- Date date1 = SDF_FORMAT.parse("2019-12-09 17:04:32");
- } catch (ParseException e) {
- e.printStackTrace();
- }
- });
- Thread t2 = new Thread(() -> {
- try {
- Date date2 = SDF_FORMAT.parse("2019-12-09 17:43:32");
- } catch (ParseException e) {
- e.printStackTrace();
- }
- });
- t1.start();
- t2.start();
- }

建议将SimpleDateFormat作为局部变量使用,或者配合ThreadLocal使用
最简单的做法是将SimpleDateFormat作为局部变量使用即可
但如果是在for循环中使用,会创建很多实例,可以优化下配合ThreadLocal使用
- //初始化
- public static final ThreadLocal<SimpleDateFormat> SDF_FORMAT = new ThreadLocal<SimpleDateFormat>(){
- @Override
- protected SimpleDateFormat initialValue() {
- return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- }
- };
- //调用
- Date date = SDF_FORMAT.get().parse(wedDate);
推荐使用Java8的LocalDateTime和DateTimeFormatter
LocalDateTime和DateTimeFormatter是Java 8引入的新特性,它们不仅是线程安全的,而且使用更方便
推荐在实际开发中用LocalDateTime和DateTimeFormatter替代Calendar和SimpleDateFormat
- DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
- LocalDateTime time = LocalDateTime.now();
- System.out.println(formatter.format(time));
锁的正确释放
假设有这样一段伪代码:
- Lock lock = new ReentrantLock();
- ...
- try{
- lock.tryLock(timeout, TimeUnit.MILLISECONDS)
- //业务逻辑
- }
- catch (Exception e){
- //错误日志
- //抛出异常或直接返回
- }
- finally {
- //业务逻辑
- lock.unlock();
- }
- ...
这段代码中在finally代码块释放锁之前,执行了一段业务逻辑
假如不巧这段逻辑中依赖服务不可用导致占用锁的线程不能成功释放锁,会造成其他线程因无法获取锁而阻塞,最终线程池被打满的问题
所以在释放锁之前;finally子句中应该只有对当前线程占有的资源(如锁、IO流等)进行释放的一些处理
还有就是获取锁时设置合理的超时时间
为了避免线程因获取不到锁而一直阻塞,可以设置一个超时时间,当获取锁超时后,线程可以抛出异常或返回一个错误的状态码。其中超时时间的设置也要合理,不应过长,并且应该大于锁住的业务逻辑的执行时间。
正确使用线程池
案例1
不要将线程池作为局部变量使用
- public void request(List<Id> ids) {
- for (int i = 0; i < ids.size(); i++) {
- ExecutorService threadPool = Executors.newSingleThreadExecutor();
- }
- }
在for循环中创建线程池,那么每次执行该方法时,入参的list长度有多大就会创建多少个线程池,并且方法执行完后也没有及时调用shutdown()方法将线程池销毁
这样的话,随着不断有请求进来,线程池占用的内存会越来越多,就会导致频繁fullGC甚至OOM。每次方法调用都创建线程池是很不合理的,因为这和自己频繁创建、销毁线程没有区别,不仅没有利用线程池的优势,反而还会耗费线程池所需的更多资源
所以尽量将线程池作为全局变量使用
案例2
谨慎使用默认的线程池静态方法
- Executors.newFixedThreadPool(int); //创建固定容量大小的线程池
- Executors.newSingleThreadExecutor(); //创建容量为1的线程池
- Executors.newCachedThreadPool(); //创建一个线程池,线程池容量大小为Integer.MAX_VALUE
上述三个默认线程池的风险点:
newFixedThreadPool创建的线程池corePoolSize和maximumPoolSize值是相等的,使用的阻塞队列是LinkedBlockingQueue。
newSingleThreadExecutor将corePoolSize和maximumPoolSize都设置为1,也使用的LinkedBlockingQueue
LinkedBlockingQueue默认容量为Integer.MAX_VALUE=2147483647,对于真正的机器来说,可以被认为是无界队列
- newFixedThreadPool和newSingleThreadExecutor在运行的线程数超过corePoolSize时,后来的请求会都被放到阻塞队列中等待,因为阻塞队列设置的过大,后来请求不能快速失败而长时间阻塞,就可能造成请求端的线程池被打满,拖垮整个服务。
newCachedThreadPool将corePoolSize设置为0,将maximumPoolSize设置为Integer.MAX_VALUE,阻塞队列使用的SynchronousQueue,SynchronousQueue不会保存等待执行的任务
- 所以newCachedThreadPool是来了任务就创建线程运行,而maximumPoolSize相当于无限的设置,使得创建的线程数可能会将机器内存占满。
所以需要根据自身业务和硬件配置创建自定义线程池
线程数建议
线程池corePoolSize数量设置建议:
1.CPU密集型应用
CPU密集的意思是任务需要进行大量复杂的运算,几乎没有阻塞,需要CPU长时间高速运行。
一般公式:corePoolSize=CPU核数+1个线程。JVM可运行的CPU核数可以通过Runtime.getRuntime().availableProcessors()查看。
2.IO密集型应用
IO密集型任务会涉及到很多的磁盘读写或网络传输,线程花费更多的时间在IO阻塞上,而不是CPU运算。一般的业务应用都属于IO密集型。
参考公式:最佳线程数=CPU数/(1-阻塞系数); 阻塞系数=线程等待时间/(线程等待时间+CPU处理时间) 。
IO密集型任务的CPU处理时间往往远小于线程等待时间,所以阻塞系数一般认为在0.8-0.9之间,以4核单槽CPU为例,corePoolSize可设置为 4/(1-0.9)=40。当然具体的设置还是要根据机器实际运行中的各项指标而定。
本文转载自微信公众号「月伴飞鱼」,作者日常加油站。转载本文请联系月伴飞鱼公众号。





















