今天带来的是全新的章节,大数据开发-HDFS,作为Hadoop生态系统的一个重要组成部分,其存在不可或缺,基础的才是最重要的,而HDFS就是这样一个存在。下面就开始HDFS的学习。
一、 HDFS介绍
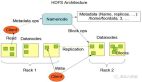
HDFS(Hadoop Distributed File System)是hadoop生态系统的一个重要组成部分,是Hadoop中的的存储组件,在整个Hadoop中的地位非同一般,也是最基础的一部分,因为它涉及到数据存储,MapReduce等计算模型都要依赖于存储在HDFS中的数据。HDFS是一个分布式文件系统,以流式数据访问模式存储超大文件,将数据分块存储到一个商业硬件集群内的不同机器上。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
分布式文件系统解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。分布式文件系统在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。
二、HDFS设计理念
硬件出现故障是常态,而HDFS由成百上千的服务器组成,每一个组成部分都有可能出现故障。因此故障的检测和自动快速恢复是HDFS的核心架构目标。与一般的应用不同,HDFS上的应用主要是以流式读取数据HDFS被设计成适合批量处理,而不是用户交互式的。相较于数据访问的反应时间,实际上更注重数据访问的高吞吐量。典型的 HDFS文件大小是GB到TB的级别。所以,HDFS被调整成支持大文件。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件。
大部分 HDFS 应用对文件要求的是 write-one-read-many访问模型。一个文件一旦创建、写入、关闭之后就不需要修改了。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。
移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效,这在数据达到海量级别的时候更是如此。将计算移动到数据附近,比之将数据移动到应用所在显然更好。
在异构的硬件和软件平台上的可移植性,这将推动需要大数据集的应用更广泛地采用 HDFS 作为平台。
三、概念介绍
以下有几个较为重要的概念需要介绍下
(1)超大文件。目前的hadoop集群能够存储几百TB甚至PB级的数据。
(2)流式数据访问。HDFS的访问模式是:一次写入,多次读取,更加关注的是读取整个数据集的整体时间。
(3)商用硬件。HDFS集群的设备不需要多么昂贵和特殊,只要是一些日常使用的普通硬件即可,正因为如此,hdfs节点故障的可能性还是很高的,所以必须要有机制来处理这种单点故障,保证数据的可靠。
(4)不支持低时间延迟的数据访问。hdfs关心的是高数据吞吐量,不适合那些要求低时间延迟数据访问的应用。
(5)单用户写入,不支持任意修改。hdfs的数据以读为主,只支持单个写入者,并且写操作总是以添加的形式在文末追加,不支持在任意位置进行修改。
四、为什么我们需要HDFS?
1.数据量巨大,磁盘开始很纠结的处理我们需要的海量信息。所以需要文件系统有大规模数据分布存储能力。
2.读取一块磁盘的所有数据需要很长时间,写入更是需要更长时间(写入时间一般是读取时间的3倍)即使有文件为1ZB,或者小点10EB时,这样的磁盘也无法做到随读随取。所以需要文件系统有高并发访问能力。
3.当数据集的大小超过一台独立物理计算机的存储能力时,就有必要对它进行分区并存储到若干台单独的计算机上。
4.从概念图上看,分布化的文件系统会因为分布后的结构不完整,导致系统复杂度加大,并且引入的网络编程,同样导致分布式文件系统更加复杂。所以需要强大的容错能力。
5.HDFS解决以上方案是分片冗余,本地校验,需要数据块存储模式数据冗余式存储,直接将多份的分片文件交给分片后的存储服务器去校验。冗余后的分片文件还有个额外功能,只要冗余的分片文件中有一份是完整的,经过多次协同调整后,其他分片文件也将完整。
经过协调校验,无论是传输错误,I/O错误,还是个别服务器宕机,整个系统里的文件是完整的。
6.分布后的文件系统有个无法回避的问题,因为文件不在一个磁盘导致读取访问操作的延时,这个是HDFS现在遇到的主要问题。
现阶段,HDFS的配置是按照高数据吞吐量优化的,可能会以高时间延时为代价。但万幸的是,HDFS是具有很高弹性,可以针对具体应用再优化。
总结就是:可以实现负载均衡、提高响应效率,因为多个服务器可以同时服务,提高了效率。
以上就是本期的所有内容了,Hadoop在大数据开发的学习当中,占据着相当重要的地位,相关知识点也会比较多,所以关于HDFS一定要好好理解,以免在后面学习Hadoop造成更多的困难。