本文转载自微信公众号「程序员jinjunzhu」,作者jinjunzhu。转载本文请联系程序员jinjunzhu公众号。
凌晨四点被公司的监控告警叫醒了,告警的原因是生产环境跑批任务发生故障。即刻起床处理故障,但还是花了不少时间才解决。
这次故障是一次数据校验的跑批任务,校验前面跑批任务的数据是否正确。幸运的是,之前的核心任务已经完成,并没有影响到生产上的交易系统工作。
为什么我这里提到了交易工作呢?因为交易系统是整个系统业务流量的入口,如果交易系统发生故障,那会给公司带来直接的收入损失。
今天我们聊的话题是服务治理,服务治理最终达到的结果就是系统 「7 * 24」 小时不间断服务。
1 监控告警
公司的这次生产告警很准确,找到系统的直接维护人,并且通知到是哪个跑批任务出了故障。这次告警是通过监控跑批任务中间件的任务执行结果来触发的。
一般情况下,告警有哪些类型呢?我们看下图:
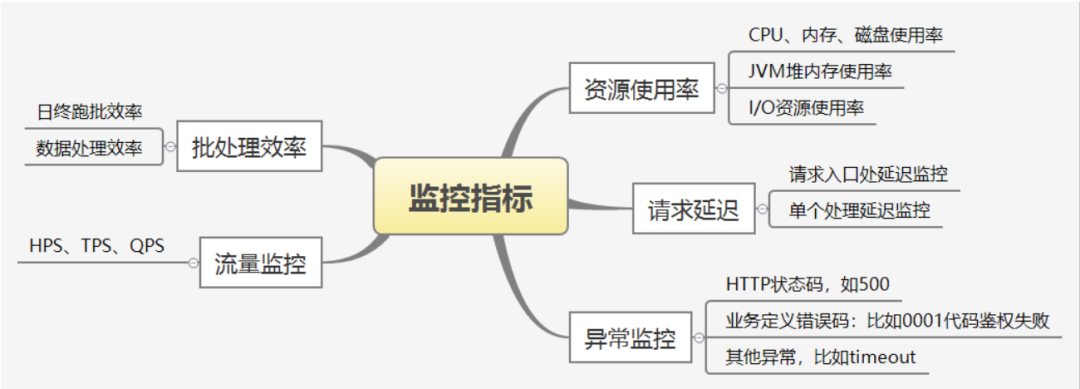
1.1 批处理效率
多数情况下批处理任务是不阻碍业务入口的,所以不需要监控。
在阻碍业务入口的情况下,批处理任务必须要监控。我举两个业务场景:
- 域名系统要通过dns信息和数据库记录来找出脏数据进行交易补偿,这期间客户查询域名信息可能是脏数据
- 银行日终跑批期间是不允许实时交易的,这个「7 * 24」小时不间断服务相违背
这些场景下批处理效率是非常重要的一个监控指标,必须配置超时阈值并进行监控。
1.2 流量监控
常用的限流的指标如下图:

流量监控我们需要注意几点:
- 不同的系统,使用的监控指标是不同的,比如redis,可以用QPS指标,对于交易系统,可以用TPS
- 通过测试和业务量的预估来配置合适的监控阈值
- 监控阈值需要考虑突发情况,比如秒杀、抢券等场景
1.3 异常监控
异常监控对于系统来说非常重要。在生产环境中很难保证程序不发生异常,配置合理的异常报警对快速定位和解决问题至关重要。比如开篇提到的跑批告警,告警信息中带着异常,让我很快就定位到了问题。
异常监控需要注意下面几个方面:
- 客户端read timeout,这时要尽快从服务端找出原因
- 对客户端收到响应的时间设置一个阈值,比如1秒,超出后触发告警
- 对业务异常一定要监控,比如失败响应码
1.4 资源使用率
生产环境配置系统资源时,一般要对系统资源的使用率有一个预测。比如redis在当前的内存增长速率下,多久会耗尽内存,数据库在当前的增长速率下多久会用光磁盘。
系统资源需要设置一个阈值,比如70%,超过这个限制就要触发告警。因为资源使用快要饱和时,处理效率也会严重下降。
配置资源使用率的阈值时,一定要考虑突增流量和突发业务的情况,提前预留额外的资源来应对。
对核心服务要做好限流措施,防止突增流量把系统压垮。
1.5 请求延迟
请求延迟并不是一个很容易统计的指标,下图是一个电商购物系统:
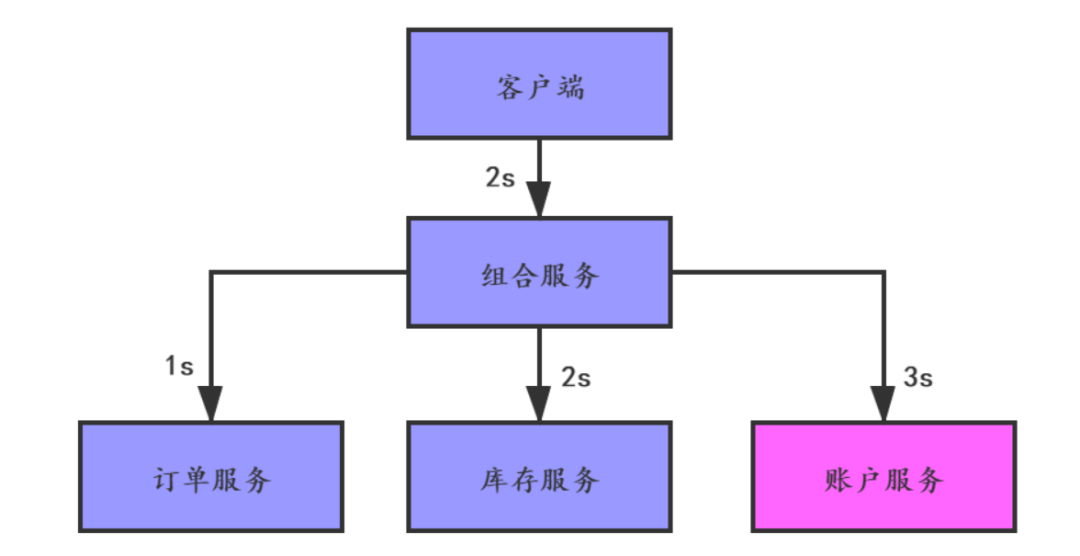
这个图中,我们假设组合服务会并发地调用下面的订单、库存和账户服务。客户端发出请求后,组合服务处理请求需要花费2秒的处理时间,账户服务需要花费3秒的处理时间,那客户端配置的read timeout最小是5秒。
监控系统需要设置一个阈值来监控,比如1秒内如果有100个请求延迟都大于了5秒就触发报警,让系统维护人员去查找问题。
客户端设置的read timeout不能太大,如果因为服务端故障导致延迟,要保证fail-fast,防止因为资源不能释放造成系统性能大服务降低。
1.6 监控注意事项
监控是为了能让系统维护人员快速发现生产问题并定位到原因,不过监控系统也有几个指标需要考虑:
- 根据监控目标来指定监控指标采样频率,频率太高会增加监控成本。
- 监控覆盖率,最好能够覆盖到所有核心的系统指标。
- 监控有效性,监控指标不是越多越好,太多会给分辨报警有效性带来额外工作量,也会让开发人员习以为常。
- 告警时效,对于跑批任务这种非实时交易类系统,可以不用实时告警,记录事件后定一个时间,比如早晨8点触发告警,责任人到公司后处理。
为避免长尾效应,最好不要使用平均值。如下图:
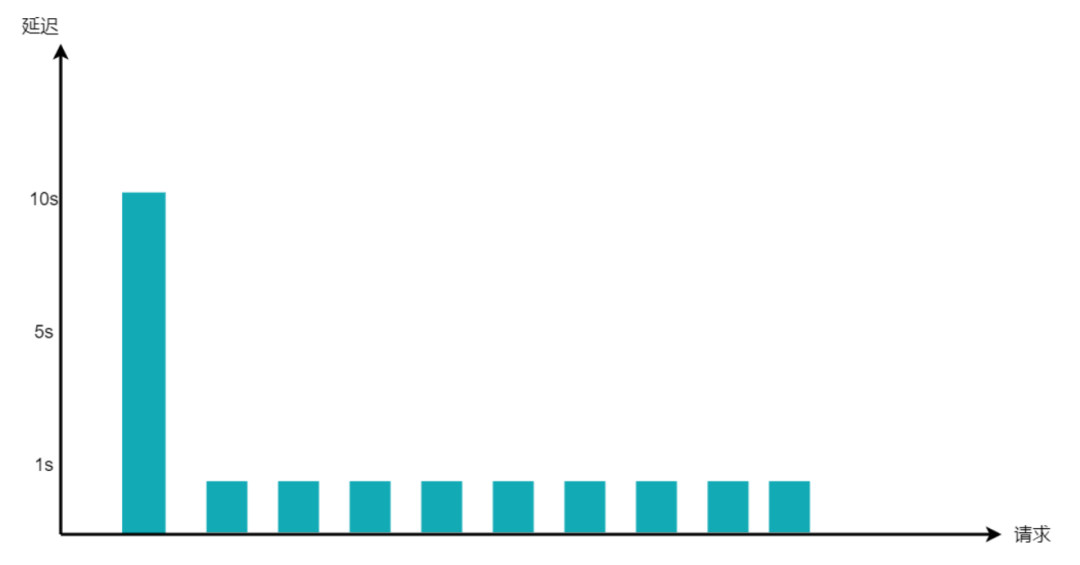
图片10个请求,有9个延迟都是1秒,但有1个延迟是10秒,所以平均值参考意义并不大。
可以采用按照区间分组的方式,比如延迟1秒以内的请求数量,1-2秒的请求数量,2-3秒的请求数量分组进行统计,按照指数级增长的方式来配置监控阈值。
2 故障管理
2.1 常见故障原因
故障发生的原因五花八门,但常见的无非下面几种:
- 发布升级带来的故障
- 硬件资源故障
- 系统过载
- 恶意攻击
- 基础服务故障
2.2 应对策略
应对故障,我们分两步走:
- 立即解决故障,比如因为数据问题引起的故障,修改问题数据即可。
- 找出故障原因,可以通过查找日志或者调用链追踪系统来定位问题并解决
2.2.1 软件升级故障
升级带来的故障,有的是上线后能很快暴露的。有的是上线很长时间才会暴露,比如有的业务代码可能之前一直执行不到。
对于第一种情况,可以采用灰度发布的方式进行验证解决。
对于第二种情况,完全避免是很难的,我们只能最大限度的提高测试用例覆盖率。
2.2.2 硬件资源故障
这类故障主要分为两类:
- 硬件资源超载,比如内存不够
- 硬件资源老化
对于第一种故障一般用监控告警的方式来通知责任人处理,处理的方式主要是增加资源,找出消耗资源严重的程序进行优化。
对于第二种故障需要运维人员对硬件资源进行记录和监控,对于老化的资源及时进行更换。
2.3 系统过载
系统过载可能是遇到秒杀之类的突增流量,也可能是随着业务发展慢慢地超过系统承受能力,可以使用增加资源或者限流的方式来应对。
2.4 恶意攻击
恶意攻击的类型非常多,比如DDOS攻击、恶意软件、浏览器攻击等。
针对恶意攻击,防止手段也很多,比如对请求报文进行加密、引入专业的网络安全防火墙、定期安全扫描、核心服务部署在非默认端口等。
2.5 基础软件故障
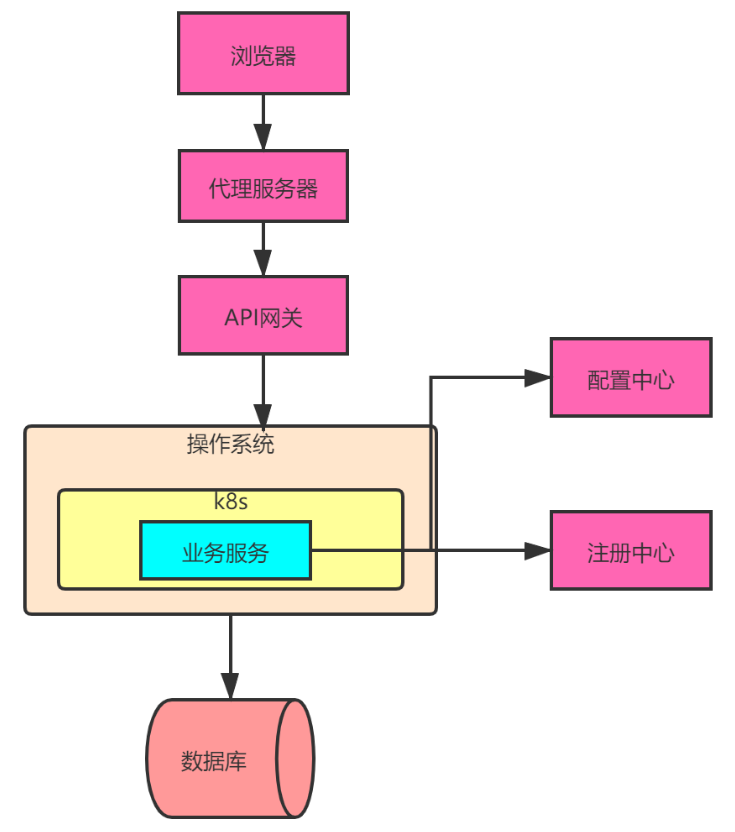
如下图所示,除了业务服务外每个组件都是基础软件,都需要考虑高可用。
3 发布管理
发布通常指软硬件的升级,包括业务系统版本升级、基础软件升级、硬件环境升级等。作为程序员,本文讲的升级是针对业务系统的升级。
3.1 发布流程
一般情况下,业务系统升级流程如下:
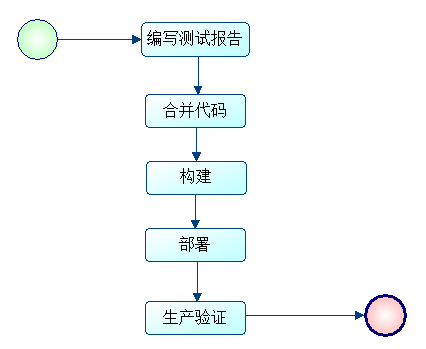
发布到生产环境,验证没有问题表示发布成功。
3.2 发布质量
在升级软件的时候,发布质量非常重要,为保证发布质量需要注意下面这些问题。
3.2.1 CheckList
为了保证发布质量,发布前维护一份CheckList,并且开发团队对所有的问题进行确认。等这份清单都确认完成后进行构建发布。下面是一些比较典型的问题:
- 上线sql是否正确
- 生产配置文件配置项是否完备
- 外部依赖的服务是否已经发布并验证完成
- 新机器路由权限是否已经开通
- 多个服务的发布顺序是否已经明确
- 如果上线后发生故障怎么应对
3.2.2 灰度发布
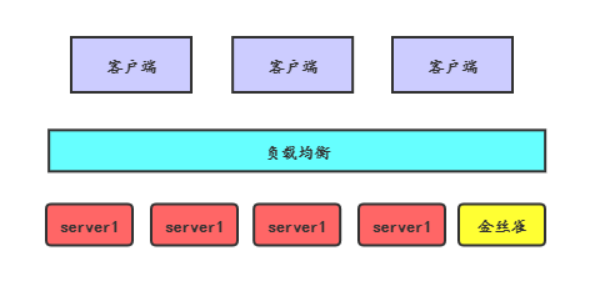
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式。如下图:图片升级时采用金丝雀部署的方式,先把其中一个server作为金丝雀进行发布升级,这个server在生产环境运行后没有问题,再升级其他的server。有问题则进行回滚。
3.2.2 蓝绿部署
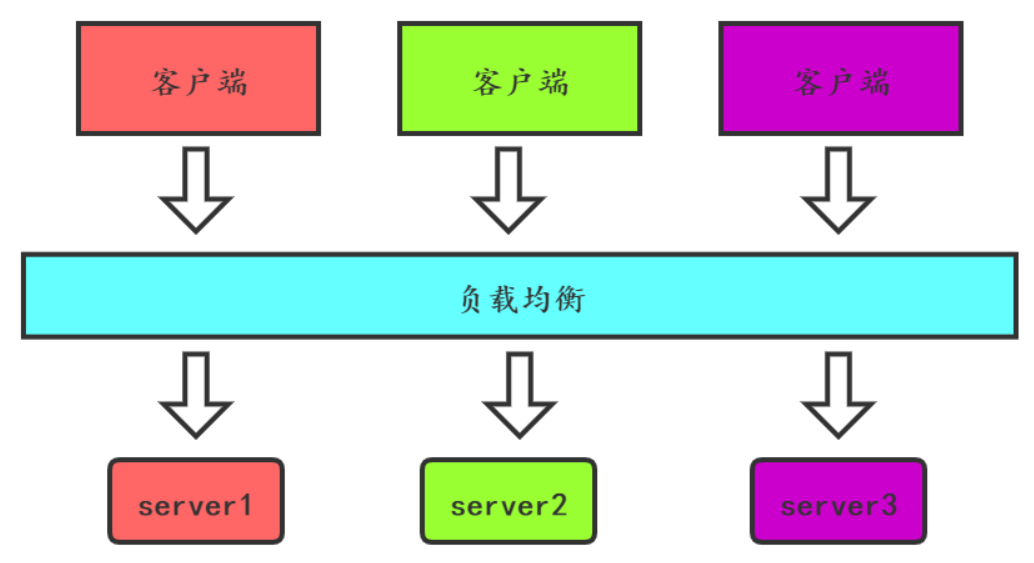
蓝绿部署的方式如下图:
升级之前客户端的请求发送到绿色服务上,升级发布之后,通过负载均衡把请求转到蓝色系统,绿色系统暂时不下线,如果生产测试没有问题,则下线绿色系统,否则切回绿色系统。
蓝绿部署跟金丝雀部署的区别是,金丝雀部署不用增加新的机器,而蓝绿部署相当于是增加了一套新机器,需要额外的资源成本。
3.2.4 ab测试
ab测试是指在生产环境发布多个版本,主要目的是测试不同版本的不同效果。比如页面样式不一样,操作流程不一样,这样可以让用户选择一个最喜欢的版本作为最终版本。如下图:
三个颜色的服务部署了,客户端的请求分部发送到跟自己颜色一样的服务上。
ab测试的版本都是已经是验证没有问题的,这点不同于灰度发布。
3.2.4 配置变更
好多时候我们把配置写在代码里,比如yaml文件。这样我们修改配置后就需要重新发布新版本。如果配置修改频繁,可以考虑下面两种方法:
引入配置中心
使用外部系统保存配置
4 容量管理
在2.3节中讲到系统过载导致的系统故障。容量管理是保证系统上线后稳定运行的一个重要环节,主要是保证系统流量不超过系统能承受的阈值,防止系统奔溃。一般情况下,系统容量超载的原因如下:
业务持续增加给系统带来的流量不断增加
系统资源收缩,比如一台机器上新部署了一个应用,占用了一些资源
系统处理请求变慢,比如因为数据量变大,数据库响应变慢,导致单个请求处理时间变长,资源不能释放
重试导致的请求增加
突增流量,比如微博系统遇到明星离婚案之类的新闻。
4.1 重试
对于一些失败的请求进行重试,能够很好地增加系统的用户体验。重试一般分为两类,一类是对连接超时的请求,一类是对响应超时的请求。
对于连接超时的请求,可能是网络瞬时故障造成的,这种情况下重试并不会对服务端造成压力,因为失败的请求压根就没有到达服务端。
但是对于响应超时的请求,如果进行重试,可能会给服务端带来额外的压力。如下图:图片正常情况下,客户端先调用服务A,服务A再调用服务B,服务B只被调用了一次。
如果服务B响应慢导致超时,客户端配置了失败重试2次,服务A也配置了失败重试2次,在服务B最终不能响应的情况下,服务B最终被调了9次。
在大型分布式系统中,如果调用链很长,每个服务都配置了重试,那重试会给调用链下游服务造成巨大的压力甚至让系统奔溃。可见重试不是越多越好,合理的设置重试对系统有保护作用。
对于重试,有如下3个建议:
非核心业务不重试,如果重试,必须限定次数
重试时间间隔要指数增加
根据返回失败的状态进行重试,比如服务端定义一个拒绝码,客户端就不重试了
4.2 突增流量
对于突增流量,是很难提前规划到的。
遇到突增的流量时,我们可以先考虑增加资源。以K8S为例,如果原来有2个pod,使用deploy编排扩容到4个pod。命令如下:
- kubectl scale deployment springboot-deployment --replicas=4
如果资源已经用完了,那就得考虑限流了。推荐几个限流框架:
- google guava
- netflix/concurrency-limits
- sentinel
4.3 容量规划
系统建设初期做好容量规划是非常重要的。
可以根据业务量来估算系统的QPS,基于QPS进行压力测试。针对压力测试的结果估算的容量,并不一定能应对生产环境的真实场景和突发情况,可以根据预估容量给出预留资源,比如2倍容量。
4.4 服务降级
服务降级对于服务端来说,可以有三种方式:
- 服务端容量超载后,直接拒绝新的请求
- 非核心服务暂停,预留资源给核心服务用
- 客户端可以根据服务端拒绝的请求比例来进行降级处理,比如观察1分钟,如果服务端对1000个请求,拒绝了100个,客户端可以作为参考,以后每分钟超过90个,就直接拒绝。
5 总结
微服务化的架构给系统带来了很多好处,但同时也带来了一些技术上的挑战。这些挑战包括服务注册与发现、负载均衡、监控管理、发布升级、访问控制等。而服务治理就是对这些问题进行管理和预防,保证系统持续平稳地运行。
本文所讲的服务治理方案,也算是传统意义上的方案,有时会有一些代码的侵入,而框架的选择也会对编程语言有限制。
在云原生时代,Service Mesh的出现又把服务治理的话题带入一个新的阶段。后续再做分享。