












从刷脸打卡到各种应用的 “猜你喜欢”,当前机器学习(特别是深度学习技术)已经广泛应用于我们日常生活的方方面面。深度学习框架(如:TensorFlow,PyTorch等)和 AI专用芯片(如:TPU、NPU等)等软硬件系统的设计极大地提升了机器学习的性能并扩展了其应用场景。与此同时,机器学习方法本身可否用于优化计算机系统设计甚至是取代传统设计模式呢?谷歌技术大神Jeff Dean领导的研究小组在2018年的SIGMOD学术会议上发表了一个有趣的工作:The Case for Learned Index Structures [1] 。本文简要介绍了Learned Index Structures的实现和优缺点,希望可以给大家带来一些系统设计的启发和思路。
一、什么是 Learned Index Structures?
Index(索引)是数据库、文件系统等领域常见的数据结构,最经典的莫过于B-Tree。B-Tree是一种范围索引(Range Index)数据结构,查询时给定一个key(或一些确定范围的keys),B-Tree会索引到包含该key的对应范围的叶子节点,在叶子节点内对key进行搜索。如果该key在索引中存在,就会得到其对应的位置。一般在一个逻辑页内的记录会用一个key来索引。如图1(a)所示,输入是一个key,输出是对应要查询记录的位置区间。除了范围索引,还有点索引(Point Index)如:哈希表(Hash Map),和存在索引(Existence Index)如:Bloom Filters,也都是常用的索引数据结构。Learned Index Structures的主要思想是将这里B-Tree或是Bloom Filters等数据结构替换为机器学习的模型——查找操作变成了根据key做索引数据位置的预测,如图1(b)所示。我们以范围索引为例,来详细介绍下Learned Index Structures的设计和实现思路。
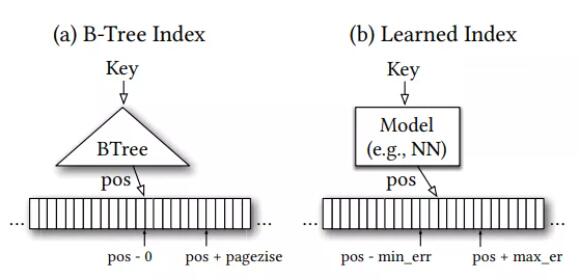
图 1 B-Tree和Learned Index示意图
图 1就是一个传统B-tree和Learned Index的对比。可以看到,Learned Index的输入是Key,输出是这个key对应的检索结果的位置(可能有误差),误差的上限是叶子节点一个数据页中的结果条目(即所需检索结果在数据页的末尾)。
那么针对范围索引,如何设计机器学习的模型呢?这里只考虑一维聚簇索引的情况(即数据是按照用于查找的 key来排序的,非聚簇索引可以通过聚簇索引加一层到真实数据排列的指针实现),Learned Index Structures很巧妙的给出了如图2所示的洞察,索引位置实际上是随着Key增长而增长的单调递增函数。虽然具体的索引可能是离散的,整体上还是可以用一个函数来描述:
p = F(Key) * N
其中, p是估计得到的位置,N是索引Key的数量,F(key)是索引数据的累计分布函数(CDF)。F(key)的含义是小于等于key的索引数据条目总和(即key的位置估计)。本质上体现了数据集的分布特征。相比B-Tree的通用设计,Learned Index Structures考虑了数据集的内在分布特点并将其用于优化索引的结构。Learned Index误差上限可控,只需要在误差范围内根据预测的位置向左或向右二分查找即可准确找到查找目标。
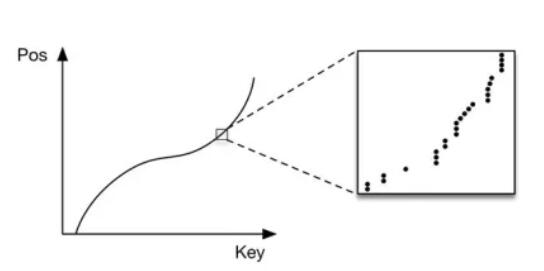
图 2 索引位置的累计概率分布(CDF)
那么如何学习得到 F(Key) 呢? Learn Index Structures作者首先尝试了用TensorFlow搭建一个每层32个神经元,两层全连接的神经网络,使用一个web server日志的数据集训练后发现效果远差于B-Tree。问题在于:
1)TensorFlow是用于大规模神经网络的训练的,小规模场景的调用开销变得不可忽视。
2)欠拟合问题,如图2所示机器学习模型可以很好的估计CDF的整体趋势,但在单一数据项上很难得到精确的表示。而B-Tree可以简单高效的使用if语句精确划分范围,为了优化“最后一公里” 机器学习模型要付出较大的存储空间和计算资源消耗。
3)B-Tree的CPU和cache行为是经过高度优化设计的,每次查找只需使用少量索引。机器学习模型则需要使用全部参数权重完成一次预测。
最终 Learn Index Structures的模型使用了如图3所示的Staged Model实现。每一个Model都可以是任意一个机器学习模型,从最简单的线性回归(LR)到深度神经网络(DNN)都可以。实践中,越简单的模型越好(避免查找时在模型上花太多时间)。当进行查找时,最上层的模型(只有一个模型),将选择一个第二层的模型来处理这个key。然后第二层的模型,会接着选择一个下一层的模型来处理这个key,直到最底层的模型,才会给出这个key对应的预测位置。但实际上上层每个模型输出的都是预测位置,这个预测被用于选择下层模型(模型id = (预测位置 / 记录总数) * 该层模型数)。
整个 Staged Model分层训练,先训练最顶层,然后进行数据分发。数据分发指的是,上层模型将key预测到哪个下层Model,该Model就拥有这条训练数据作为他的训练集。所以随着层数的加深,以及每一层模型数量的提升,每个越底层模型拥有的训练数据是越少的。这样的优点是,底层模型可以非常容易的拟合这一部分数据的分布(缺点是较少的数据量带来了模型的选择限制,复杂模型没法收敛)。[1]中采用的结构是:只在顶层使用神经网络模型,在其余层使用线性回归模型。
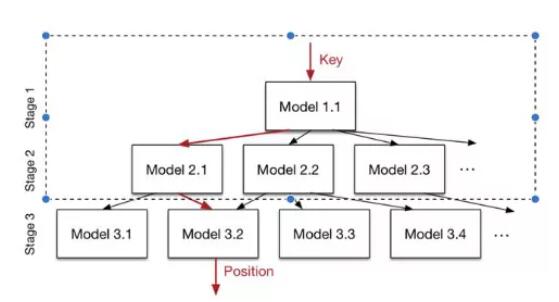
图 3 用于Learned Index Structures的Staged Model
点索引和存在索引的 Learned Index Structure 这里不再一一赘述,感兴趣的话可以阅读论文[1],以及基于论文实现的RMI(Recursive Model Indexes)代码[2]。
二、如何评价Learned Index Structures?
总的来说,Learned Index Structures向我们展示了机器学习在系统领域的巨大潜力,但还存在诸多待解决的问题(如:过拟合、索引的增删改等问题)。对于过拟合,若新索引的key依然满足CDF则并不需要重新训练,直接insert到预测出来的位置即可。若数据分布会发生变化,则需要尝试在线学习(Online learning)的方法。对于数据更新频繁的系统,可采用delta-index技术增量更新learned index。
实际上,以Learned Index Structures为代表的机器学习优化方法并不是系统设计优化的终结者。比如spline B-tree [6] 使用B-tree的每个叶子节点只存一个spline(即key和其位置),两个spline之间的数据用两点之间的直线来预测。这样一个简单的数据结构,很多时候效果相当于复杂的Learn Index,甚至更好。在Point Index 领域,Learned Index通过减少冲突实现的优化可以被bucketized cuckoo hashing [7] 轻松打败,该方法只是简单的将每个key同时hash到两个bucket而已。
但这并不能否定机器学习在系统设计上的 价值,通过机器学习可以启发系统设计的优化和思考,探索出之前未曾发现的系统设计思路。在优化原理清晰、场景固定的情况下,显然由人加以解释和重新实现在效率和稳定性上更胜机器学习方法一筹。在数据分布等特征动态变化的场景,机器学习方法 可以针对性优化和适应数据特征,理论上可以优于通用的算法和数据结构。
三、机器学习+系统设计 = ?
也许Learned Index Structures还存在很多不足,但无法忽略的是将机器学习应用于计算机系统设计的趋势已经到来。如果说Learn Index Structures是机器学习打入计算机系统设计领域的一声炮响,2019年发布的机器学习系统白皮书 [5] 就是正式确立了机器学习和计算机系统设计交叉研究方向的诞生。如Jeff Dean在SysML18会议上主旨演讲所言:“使用启发式技术的任何系统领域,都是可能应用机器学习的好地方——编译器、网络、操作系统、芯片设计等”。要取得成功,关键点有两个:
1) 找到一个能用数字精确表示的优化指标;
2) 有一个集成机器学习的清晰接口(模型的输入输出定义,训练、测试数据集的获取等)。
对于计算机系统领域的优化,这两个要求似乎是比较容易实现的。


















