












概述:读完这篇文章你将能够:
- 辨别不同类型的机器学习问题;
- 理解什么是机器学习模型;
- 知道建立和应用机器学习模型的一般工作流;
- 了解常见机器学习算法的优点和缺点。
机器学习模型
机器学习(Machine Learning)这个术语常常掩盖了它的计算机科学性质,因为它的名字可能暗示机器正在像人类一样学习,甚至做得更好。
尽管我们希望有一天机器能够像人类一样思考和学习,但如今机器学习并不能超越执行预定义过程的计算机程序。机器学习算法与非机器学习算法(如控制交通灯的程序)的不同之处在于,它能够使自身的行为适应新的输入。而这种似乎没有人为干预的适应,偶尔会给人一种机器真的是在学习的错觉。然而,在机器学习模型的背后,这种行为上的适应和人类编写的每一条机器指令一样严格。
那么什么是机器学习模型?
机器学习算法是揭示数据中潜在关系的过程。
机器学习模型(machine learning model)是机器学习算法产出的结果,可以将其看作是在给定输入情况下、输出一定结果的函数(function)F。
机器学习模型不是预先定义好的固定函数,而是从历史数据中推导出来的。因此,当输入不同的数据时,机器学习算法的输出会发生变化,即机器学习模型发生改变。
例如,在图像识别的场景中,可以训练机器学习模型来识别照片中的对象。在某种情况下,人们可能会将数千张有猫和没有猫的图像输入到机器学习算法中,以获得一个能够判断照片中是否有猫的模型。因此,生成的模型对应的输入将是一张数字照片,而输出是一个表示照片上是否存在猫的布尔值。
在上述情况下,机器学习模型是一个将多维像素值映射到二进制值的函数。假设我们有一张 3 维像素的照片,每个像素的值范围从 0 到 255。那么输入和输出之间的映射空间将是 (256×256×256)×2,大约是 3300 万。我们可以说服自己,在现实世界的案例中学习这种映射(机器学习模型)一定是一项艰巨的任务,因为在这种情况下,一张普通照片占到数百万像素,并且每个像素由三种颜色(RGB)组成,而不是单一的灰色。
机器学习的任务,就是从广阔的映射空间中学习函数。
在这种情况下,找出数百万像素和 “是/否” 答案之间的潜在映射关系的过程,就是我们所说的机器学习。大多数时候,我们学习的最后结果是对这种潜在关系的一种近似。由于机器学习模型的近似性质,人们不应该因发现机器学习模型的结果往往无法达到 100%精确而感到失望。在 2012 年深度学习被广泛应用之前,最好的机器学习模型只能在 ImageNet 视觉识别挑战 中达到 75% 精度。到目前为止,还没有一种机器学习模型能够保证 100%精确,尽管在这项任务中,有一些模型的误差要比人类少 <5%。
有监督 VS. 无监督
给出一个机器学习问题,首先可以确定它是有监督(supervised) 问题还是无监督(unsupervised) 问题。
对于任何机器学习问题,我们都从一组样本(samples)组成的数据集开始。每个样本可以表示为一个属性(attributes)元组。
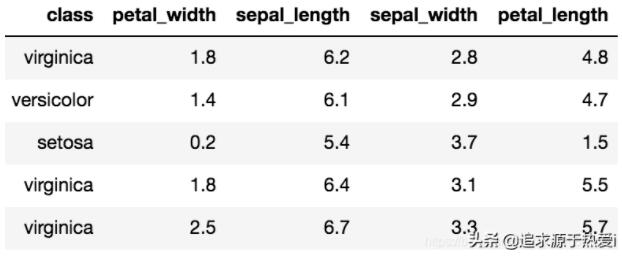
例如,有一个名为 Iris 的著名经典数据集,首次发表于 Ronald. A. Fisher 在 1936 年的论文 “The use of multiple measurements in taxonomic problems(可译作:多重测量在分类学问题中的使用)”。Iris 数据集包括对 150 个鸢尾花样本的测量。每个样本都包含其花瓣和萼片的长度和宽度的测量值,以及指示鸢尾花类别的属性,即山鸢尾、变色鸢尾和维吉尼亚鸢尾。以下是 Iris 数据集的一些示例
有监督学习
在一个有监督的学习任务中,数据样本将包含一个目标属性 yyy,也就是所谓的真值(ground truth)。我们的任务是通过学习得到一个函数 F,它接受非目标属性 X,并输出一个接近目标属性的值,即 F(X)≈yF(X) \approx yF(X)≈y。目标属性 yyy 就像指导学习任务的教师,因为它提供了一个关于学习结果的基准。所以,这项任务被称为有监督学习。
在 Iris 数据集中,类别属性(鸢尾花的类别)可以作为目标属性。具有目标属性的数据通常称为 “标记” 数据(labeled data)。基于上述定义,可以看出用标记数据预测鸢尾花的种类的任务是一个有监督的学习任务。
无监督学习
与有监督的学习任务相反,我们在无监督的学习任务中没有设置真值。人们期望从数据中学习潜在的模式或规则,而不以预先定义的真值作为基准。
人们可能会问,如果没有来自真值的监督,我们还能学到什么吗?答案是肯定的。以下是一些无监督学习任务的示例:
- 聚类(Clustering):给定一个数据集,可以根据数据集中样本之间的相似性,将样本聚集成组。例如,样本可以是一个客户档案,具有诸如客户购买的商品数量、客户在购物网站上花费的时间等属性。根据这些属性的相似性,可以将客户档案分组。对于聚集的群体,可以针对每个群体设计特定的商业活动,这可能有助于吸引和留住客户。
- 关联(Association):给定一个数据集,关联任务是发现样本属性之间隐藏的关联模式。例如,样本可以是客户的购物车,其中样本的每个属性都是商品。通过查看购物车,人们可能会发现,买啤酒的顾客通常也会买尿布,也就是说,购物车里的啤酒和尿布之间有很强的联系。有了这种学习而来的洞察力,超市可以将那些紧密相关的商品重新排列到相邻近的角落,以促进这一种或那一种商品的销售。
半监督学习
在数据集很大,但标记样本很少的情况下,可以找到同时具备有监督和无监督学习的应用。我们可以将这样的任务称为半监督学习(semi-supervised learning)。
在许多情况下,收集大量标记的数据是非常耗时和昂贵的,这通常需要人工进行操作。斯坦福大学的一个研究团队花了两年半的时间来策划著名的 “ImageNet”,它包含了数以百万计的图像带有成千上万个手动标记的类别。因此,更普遍的情况是,我们有大量的数据,但只有很少一部分被准确地 “标记”,例如视频可能没有类别甚至标题。
通过将有监督和无监督的学习结合在一个只有少量标记的数据集中,人们可以更好地利用数据集,并获得比单独应用它们更好的结果。
例如,人们想要预测图像的分类,但只对图像的 10% 进行了标记。通过有监督的学习,我们用有标记的数据训练一个模型,然后用该模型来预测未标记的数据,但是我们很难相信这个模型是足够普遍的,毕竟我们只用少量的数据就完成了学习。一种更好的策略是首先将图像聚类成组(无监督学习),然后对每个组分别应用有监督的学习算法。第一阶段的无监督学习可以帮助我们缩小学习的范围,第二阶段的有监督学习可以获得更好的精度。
引用
[1]. Fisher,R.A. “The use of multiple measurements in taxonomic problems” Annual Eugenics, 7, Part II, 179-188 (1936)
分类 VS. 回归
在前一节中,我们将机器学习模型定义为一个函数 FFF,它接受一定的输入并生成一个输出。通常我们会根据输出值的类型将机器学习模型进一步划分为分类(classification)和回归(regression)。
如果机器学习模型的输出是离散值(discrete values),例如布尔值,那么我们将其称为分类模型。如果输出是连续值(continuous values),那么我们将其称为回归模型。
分类模型
例如,说明照片中是否包含猫的模型可以被视为分类模型,因为我们可以用布尔值表示输出。
更具体地说,输入可以表示为矩阵M,尺寸为 H×W,其中 H 是照片的高度(像素),W 是照片的宽度。矩阵中的每个元素都是照片中每个像素的灰度值,即一个介于 [0,255]之间的整数,表示颜色的强度。模型的预期输出为二进制值 [1∣0],用于指示照片是否显示猫。综上所述,我们的猫照片识别模型 F 可表述如下:
F(M[H][W])=1∣0,where M[i][j]∈[0,255],0<i<H,0<j<WF(M[H][W])
机器学习的目标是找出一个尽可能通用的函数,这个函数要尽可能对不可见数据给出正确的答案。
回归模型
对于回归模型,我们给出这样一个例子,考虑一个用于估算房产价格的模型,其特征包括诸如面积、房产类型(例如住宅、公寓),当然还有地理位置。在这种情况下,我们可以将预期输出看作是一个实数 p∈R,因此它是一个回归模型。注意,在本例中,我们所拥有的原始数据并非全部是数字,其中某些数据是用于分类的,例如房地产类型。在现实世界中,情况往往就是这样的。
对于每个正在考虑的房产,我们可以将其特征用元组 T 来表示,其中元组中的每个元素要么是数值,要么是表示其属性之一的分类值。在许多情况下,这些元素也被称为 “特征(features)”。综上所述,我们可以建立如下的房产价格估算模型:
F(T)=p,where p∈R
再具体一些,让我们考虑一个具有以下特征的房产:
surface = 120 m^2 , type = ’ apartment’, location = ’ NY downtown’, year_of_construction = 2000
现在考虑到上述特征,如果我们的模型 F 给出了一个像 10,000$ 这样的值,那么很可能我们的模型并不适合这个问题。
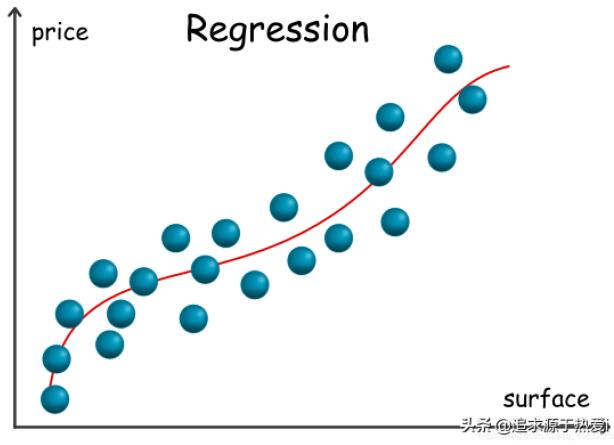
在下面的图表中,我们展示了一个以地产面积为唯一变量,以地产价格为输出的回归模型样例。
说起特征,还要提到的一点是,一些机器学习模型(例如决策树)可以直接处理非数字特征,而更多时候人们必须以某种方式将这些非数字特征转换(transform)为数字特征。
问题转化
对于一个现实世界的问题,有时人们可以很容易地将其表述出来,并快速地将其归结为一个分类问题或回归问题。然而,有时这两个模型之间的边界并不清晰,人们可以将分类问题转化为回归问题,反之亦然。
在上述房产价格估算的例子中,似乎很难预测房产的确切价格。然而,如果我们将问题重新表述为预测房产的价格范围,而不是单一的价格标签,那么我们可以期望获得一个更健壮的模型。因此,我们应该将问题转化为分类问题,而不是回归问题。
对于我们的猫照片识别模型,我们也可以将其从分类问题转换为回归问题。我们可以定义一个模型来给出一个介于 [0,100%] 之间概率值来判断照片中是否有猫,而不是给出一个二进制值作为输出。这样,就可以比较两个模型之间的细微差别,并进一步调整模型。例如,对于有猫的照片,模型 A 给出概率为 1%,而模型 B 对相同照片给出了 49%的概率。虽然这两种模型都没有给出正确的答案,但我们可以看出,模型 B 更接近于事实。在这种情况下,人们经常应用一种称为逻辑回归(Logistic Regression)的机器学习模型,这种模型将连续概率值作为输出,但用于解决分类问题。
机器学习工作流
在前一节中,我们阐明了机器学习模型的概念,在这一部分中,我们将会讨论一个用于构建机器学习模型的典型工作流(workflow)。
首先,我们不能一昧只谈论机器学习,而将数据搁置在一旁。数据之于机器学习模型就如燃料之于火箭发动机一样重要。
以数据为中心的工作流
构建机器学习模型的工作流是以数据为中心的。
毫不夸张地说,数据决定了机器学习模型的构建方式。在下图中,我们展示了机器学习项目中涉及的典型工作流。
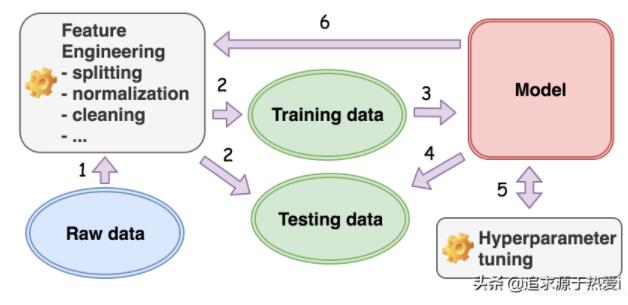
从数据出发,我们首先需要确定我们要解决的机器学习问题的类型,即有监督的学习问题还是无监督的机器学习问题。我们规定,如果数据中的一个属性是所需的属性,即目标属性,那么该数据被标记。例如,在判断照片上是否有猫的任务中,数据的目标属性可以是布尔值 [Yes|No]。如果这个目标属性存在,那么我们就说数据被标记了,这是一个简单的学习问题。
对于有监督的机器学习算法,我们根据模型的预期输出进一步确定生成模型的类型:分类或回归,即分类模型的离散值和回归模型的连续值。
一旦我们确定了想要从数据中构建的模型类型,我们就开始执行特征工程(feature engineering),这是一组将数据转换为所需格式的活动。下面给出了几个例子:
对于几乎所有的情况,我们将数据分成两组:训练和测试。在训练模型的过程中使用训练数据集,然后使用测试数据集来测试或验证我们构建的模型是否足够通用,是否可以应用于不可见的数据。
原始数据集通常是不完整的,带有缺失值。因此,可能需要用各种策略来填充这些缺失值,例如用平均值进行填充。
数据集通常包含分类属性,如国家、性别等,通常情况下,由于算法的限制,需要将这些分类字符串值编码为数值。例如,线性回归算法只能处理输入的实值向量。
特征工程的过程无法一蹴而就。通常,在工作流的稍后阶段,您需要反复地回到特征工程上来。
一旦数据准备好,我们就选择一个机器学习算法,并开始向算法输入准备好的训练数据(training data)。这就是我们所说的训练过程(training process)。
一旦我们在训练过程结束后获得了机器学习模型,就需要用保留的测试数据(testing data)对模型进行测试。这就是我们所说的测试过程(testing process)。
初次训练的模型往往无法令人感到满意。此后,我们将再一次回到训练过程,并调整由我们选择的模型公开的一些参数。这就是我们所说的超参数调优(hyper-parameter tuning)。之所以突出 “超(hyper)”,是因为我们调优的参数是我们与模型交互的最外层接口,而这最终会对模型的底层参数造成影响。例如,对于决策树模型,其超参数之一是树的最大高度。一旦在训练之前进行手动设置,它将限制决策树在结束时可以生长的分支和叶的数量,而这些正是决策树模型所包含的基本参数。
可以看到,机器学习工作流所涉及的几个阶段形成了一个以数据为中心的循环过程。
数据,数据,数据!
机器学习工作流的最终目标是建立机器学习模型。我们从数据中得到模型。因此,模型所能达到的性能上限是由数据决定的。有许多模型可以拟合特定的数据。我们所能做到最好的,就是找到一个可以最接近于数据所设置的上限的模型。我们不能期望一个模型能够从数据的范围之内学到其他东西。
经验法则: 若输入错误数据,则输出亦为错误数据。
用盲人摸象的寓言来说明这一观点也许是较为恰当的。故事是这样的,一群从来没有遇到过大象的盲人,他们试图通过触摸大象来了解和概念化大象是什么样子。每个人都可以触摸大象身体的一部分,如腿、象牙或尾巴等。虽然他们每个人都有接触到一部分真实情形,但没有一个人能获知大象的全貌。因此,他们中没有一个人可以真正了解大象的真实形象。

现在,回到我们的机器学习任务,我们得到的训练数据可能是来自象腿或象牙的图像,而在测试过程中,我们得到的测试数据是大象的完整肖像。不出所料,我们的训练模型在这种情况下表现不佳,因为我们没有更切合实际的高质量训练数据。
有人可能会想,如果这些数据真的很重要,那么为什么不将大象的完整肖像等 “高质量” 数据输入到算法中,而偏偏要输入大象身体某些部分的概况呢?这是因为,在面对一个问题时,无论是我们还是机器,就像 “盲人” 一样,或者是由于技术问题(例如数据隐私),或者仅仅是因为我们没有以正确的方式认识到问题,常常很难收集到能够描绘问题本质特征的数据,
现实世界中,在有利的情况下,我们得到的数据可能反映了现实的一部分,而在不利的情况下就可能是一些干扰判断的噪音,在最糟糕的情况下,甚至会与现实相矛盾。不管机器学习算法如何,人们都无法从包含太多噪音或与现实不符的数据中学到任何东西。
欠拟合 VS. 过拟合
对于有监督学习算法,例如分类和回归,通常有两种情况下生成的模型不能很好地拟合数据:欠拟合(underfitting)和过拟合(overfitting)。
有监督学习算法的一个重要度量是泛化,它衡量从训练数据导出的模型对不可见数据的期望属性的预测能力。当我们说一个模型是欠拟合或过拟合时,它意味着该模型没有很好地推广到不可见数据。
一个与训练数据相拟合的模型并不一定意味着它能很好地概括不可见数据。有以下几点原因:1). 训练数据只是我们从现实世界中收集的样本,只代表了现实的一部分。这可能是因为训练数据根本不具有代表性,因此即使模型完全符合训练数据,也不能很好的拟合不可见数据。2). 我们收集的数据不可避免地含有噪音和误差。即便该模型与数据完全吻合,也会错误地捕捉到不期望的噪音和误差,最终导致对不可见数据的预测存在偏差和误差。
在深入欠拟合和过拟合的定义之前,我们将会展示一些能够反映欠拟合和过拟合模型在分类任务中真实情形的示例。
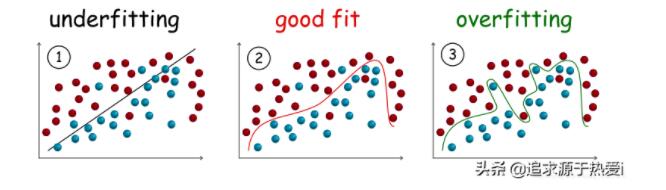
欠拟合
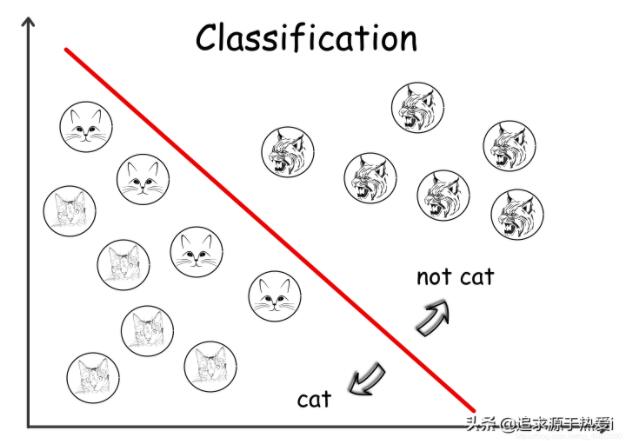
欠拟合模型是指不能很好地拟合训练数据的模型,即显著偏离真实值的模型。
欠拟合的原因之一可能是模型对数据而言过于简化,因此无法捕获数据中隐藏的关系。从上图**(1)**可以看出,在分离样本(即分类)的过程中,一个简单的线性模型(一条直线)不能清晰地画出不同类别样本之间的边界,从而导致严重的分类错误。
为了避免上述欠拟合的原因,我们需要选择一种能够从训练数据集生成更复杂模型的替代算法。
过拟合
过拟合模型是与训练数据拟合较好的模型,即误差很小或没有误差,但不能很好地推广到不可见数据。
与欠拟合相反,过拟合往往是一个能够适应每一位数据的超复杂模型,但却可能会陷入噪音和误差的陷阱。从上面的图**(3)**可以看出,虽然模型在训练数据中的分类错误少了,但在不可见数据上更可能出错。
类似地于欠拟合的情况,为了避免过拟合,可以尝试另一种从训练数据集生成更简单的模型的算法。或者更常见的情况是,使用生成过拟合模型的原始算法,但在算法中增加添加了正则化(regularization)项,即对过于复杂的模型进行附加处理,从而引导算法在拟合数据的同时生成一个不太复杂的模型。
为什么要机器学习
在阅读前面的章节之后,我们应该能够大致地说出机器学习(ML)算法是什么,并且应该对如何在项目中应用 ML 有一个简要的想法。
现在,在这一章中,我们正应该思考这个问题:为什么我们需要 ML 算法?
首先,我们需要承认,目前(2018 年),在我们生活中的许多方面,确实需要 ML 算法。值得注意的是,它在互联网服务中(如社交网络、搜索引擎等)无处不在,而我们每天都在使用这些工具。事实上,正如 Facebook 最近发表的一篇论文所揭示的那样,ML 算法变得如此重要,以至于 Facebook 开始从硬件到软件重新设计数据中心,以更好地满足应用 ML 算法的要求。
“在 Facebook 上,机器学习提供了驱动用户体验几乎所有方面的关键功能……机器学习广泛应用于几乎所有的服务。”
以下是关于 ML 如何在 Facebook 中应用的几个示例:
- 新闻提要中的事件排序是通过 ML 进行的。
- 显示广告的时间、地点和对象由 ML 确定。
- 各种搜索引擎(如照片、视频、人物)都是由ML支持的。
在我们现在使用的服务(例如谷歌搜索引擎、亚马逊电子商务平台)中,可以很容易地识别出许多其他应用 ML 的场景。ML 算法的普遍存在已经成为现代生活中的一种规范,这就证明了至少在现在和不久的将来都有其存在的合理性。
为什么要机器学习?
ML 算法之所以存在,是因为它们能够解决非 ML 算法无法解决的问题,而且还提供了非 ML 算法所不具备的优势。
区分 ML 算法与非 ML 算法的最重要特征之一是,它将模型与数据分离,以便 ML 算法能够适应不同的业务场景或相同的业务案例,但具有不同的上下文。例如,可以应用分类算法来判断照片上是否显示了人脸。它还可以用来预测用户是否会点击广告。在人脸检测的情况下,同样的分类算法可以训练一个模型来判断照片上是否出现了人脸,也可以训练另一个模型来确认照片上出现的是谁。
通过分离模型与数据,ML 算法可以一种更灵活、更通用、更自治的方式来解决许多问题,也就是说,它更像是一个人。ML 算法似乎能够从环境(即数据)中学习知识,并相应地调整其行为(即模型),以解决特定的问题。在不对 ML 算法中的规则(即模型)进行显式编码的情况下,我们构造了一种元算法,它能够以有监督或无监督的方式从数据中学习规则/模式。
机器学习真的无所不能吗?
一旦人们开始学习各种机器学习(ML)算法,并了解到这些算法在处理诸如图像识别和语言翻译等具有挑战性的任务时的多才多艺,人们可能会沉溺于将 ML 应用于他们所面临的每一个问题,无论它是否真的合适。因为通常情况下,如果你的工具有一把锤子,你会认为任何问题都是钉子。
因此,在这一节中,我们想要强调一些看上去消极的事项。和所有其他的解决方案一样,ML 并不是什么万应良方。
和人类一样,ML 模型也会犯错。
例如,有人可能会注意到,Facebook 有时无法从照片中标记出一张脸。不幸的是,人们似乎接受了这种情形,即目前最先进的 ML 算法通常无法达到 100% 精确。人们甚至会为 ML 算法辩护,因为 ML 所处理的问题即便对人类来说也确实很难解决,例如图像识别。然而,它与过去普遍的认知形成了对比,即机器不会犯任何错,或者至少比人类更少犯错。有一段时间(2012年之前),人们可以很容易地宣称以 75% 精度的模型获得 ImageNet 挑战的冠军。应该注意的一点是,该挑战往往被认为是图像识别领域的奥林匹克赛事。因此,人们可以将 ImageNet 挑战的结果视为领域中最先进的研究成果,但到目前为止(2018年),仍然没有模型能够达到 100% 的精度。一般来说,可以达到 ~80% 精度的ML模型被认为具有良好的性能。因此,在算法精度至关重要的情况下,人们应该慎重考量他们采用 ML 算法的决定。
很难(在不是不可能的情形下)以逐例的方式纠正 ML 所犯的错误。
有人可能会想,如果我们把 ML 模型所犯的每一个错误都看作是软件中的一个缺陷,难道我们就不能一个接一个地纠正它们,从而一步一步地提高准确性吗?答案是否定的。究其原因有两个方面:1). 一般来说,我们通常无法显式地操作一个 ML 模型,而是用给定的数据结合 ML 算法来共同生成模型。为了改进一个模型,我们要么改进算法,要么提高数据质量,而不是直接修改模型。2). 即使我们可以在随后操作生成的 ML 模型,由于无法直观看到改进造成的影响,在某些 “错误” 情况下,如何在不影响其他正确情况的情况下更改 ML 模型的输出又成为了一个新的难题。例如,对于决策树模型,模型的输出是每个节点的分支条件的结合,遵循从根到叶的路径。我们可以更改节点中的某些分支条件,以更改在错误情况下的决定。但是,这种更改也会影响通过修改的节点传递的每种情况的输出。总之,人们不能简单地将 ML 模型所犯的错误等同于软件中的缺陷。需要一种整体的方法来改进模型,而不是逐例修补模型。
对于某些 ML 模型,很难(如果不是不可能的话)进行推理。
到目前为止,人们已经了解到 ML 模型存在错误,而且很难逐例纠正错误。也许事情并没有那么糟糕,因为至少我们可以解释它为什么会出错,比如决策树模型。然而,在某些情况下,特别是对于带有神经网络的 ML 模型,我们不能真正对这些模型进行推理,也就是说,很难对模型作出解释,从而识别模型中的关键参数。例如,有一个叫做 ResNet 的最先进的神经网络模型,它在 ImageNetChallenge 中实现了高达 96.43% 的精度。ResNet-50 模型由 50 层神经元组成,包括 2560 万个参数。每个参数都有助于模型的最终输出。无论输出是否正确,都是模型背后的数百万个参数共同作用的结果。很难将任何逻辑单独归于每个参数。因此,在偏重模型可解释性的场景中,应该仔细考量应用基于神经网络的 ML 模型的决定。
因此,概括地说,ML不是灵丹妙药,因为它常常无法达到 100%100 %100% 精确,而且我们不能逐例更正 ML 模型,在某些情况下,我们甚至无法对 ML 模型进行推理。
拓展阅读
[1]. ResNet: Deep Residual Learning for Image Recognition. He et al.CVPR 2016 Las Vegas, NV, USA.
[2]. LIME: Explaining the Predictions of Any Classifier. Ribeiro et al. KDD 2016 San Francisco, CA, USA.















