人工智能的必要条件:深度学习模型,大数据,算力
作者:Michael Zhang 麦教授
2016年,AlphaGo下围棋战胜李世乭,大家都认为人工智能的时代到来了。人工智能也是同样的在一定的历史契机下,几个独立发展的领域碰巧合并在一起就产生了巨大的推动力。这一波人工智能发展的三个必要条件是:深度学习模型,大数据,算力(并行计算)。
深度学习模型
AlphaGo用的机器学习模型是深度学习教父杰佛瑞·辛顿(Geoffrey Hinton)在1986年开始倡导,并在2010年取得重大突破的。
「辛顿的推特头像」
2012年的夏天,64岁的辛顿离开了他在多伦多附近的家,成为了谷歌的一名实习生。他领到了一顶缝有“Noogler”(意思是:谷歌新员工,New Googler的缩写)字样的螺旋桨小帽,并参加了主要由80后、90后组成的迎新会。年轻的Nooglers不会认出他来,因为辛顿几十年来一直在默默研究神经网络的算法。用他的话说,这些年轻人似乎把他当成了“老年低能儿”(有没有想起罗伯特·德尼罗的电影《实习生》?)。
谷歌之所以要请他,是因为他的深度学习算法模型打破了机器学习几乎所有领域的天花板。人工智能最近几年的突破得益于辛顿过去几十年的研究,他最初在1986年发表的论文提出让机器像人类的大脑一样通过神经网络来做学习的模型。但是这个模型在取得初步的成功后,就停滞不前了(缺乏另外两个要素:数据和算力)。大多数的学者都背弃了它,而辛顿没有。
历史快进20年,到了2006年,辛顿的团队取得了突破性进展。被重新命名为“深度学习(deep learning)”的神经网络开始在每一项关键任务中击败传统的人工智能,如语音识别、描述图像和生成自然可读的句子等等。这些算法支撑着从自动驾驶汽车、虚拟助手到搜索引擎推荐的后端技术。
近几年,谷歌、Facebook、微软、BAT、抖音等所有科技巨头都开始了深度学习的淘金热,争夺世界上极少数的专家,由数亿风险投资支持的深度学习创业公司也如雨后春笋般涌现。这些都是因为辛顿的模型改变了人们做人工智能研究和应用的范式。
值得一提的是:辛顿这个家族出了太多的神一样的人物。
辛顿的曾祖父是乔治·布尔(George Boole),就是就是布尔代数那个布尔。布尔32岁出版了《逻辑的数学分析》(The Mathematical Analysis of Logic),把逻辑和代数之间的关系建立起来。他39岁时出版了《思维的规则》 ( The Laws of Thought ),创立了布尔逻辑和布尔代数。数理逻辑这个数学分支奠定了现代计算机的数学基础。
布尔的妻子叫玛丽·艾佛斯特(Mary Everest),珠穆朗玛峰(Mount Everest)英文名字就是以玛丽的叔叔,曾任印度大地测量局总测量师的乔治·艾佛斯特(George Everest)而命名的。布尔最小的女儿艾捷尔·丽莲·伏尼契 (EthelLilian Voynich)写出了伟大的作品《牛虻》(The Gadfly)。
布尔长女玛丽·爱伦(Mary Ellen) 这一支更是名人辈出,爱伦和数学家Charles Howard Hinton结婚。爱伦的孙女(辛顿的姑姑)Joan Hinton中文名寒春(名字就是Hinton的音译),是芝加哥大学核物理研究所研究生,是费米(Enrico Fermi)的学生,杨振宁、李政道的同学,也是参与了曼哈顿计划的极少数的女科学家之一。

「“一个逃掉的原子间谍”」
1953年,美国的《真相》杂志报道称曾参与过美国曼哈顿计划的女物理学家寒春(Joan Hinton)突然失踪而后在北京露面。作者(是个后海军上将)怀疑寒春向中国透露了美国的原子弹秘密,甚至可能协助中国政府发展了原子弹计划。寒春其实是厌恶了原子弹对人类的伤害而选择逃离到中国,她认为中国最缺的是牛奶,于是选择帮中国推进科学养牛和农业机械化。她是第一位获得中国绿卡的外国人,2010年在北京去世。
和寒春一样,辛顿也厌倦了美国军方开发大规模杀伤武器,1980年代就离开了卡耐基梅隆大学(CMU)到加拿大的多伦多大学专心做人工智能研究。2010年,63岁的他发表的深度神经网络AlexNet对机器学习各个领域都起到巨大的推动作用。2018年,他和自己的学生和合作者一起获得了计算机科学的最高奖“图灵奖”。
人工智能的大数据
辛顿的深度学习算法摧枯拉朽般地推进了机器学习的各个子领域。大众意识到这个算法的威力是在2012年。
2012年,语音识别还远未达到完美。这些系统通常使用隐藏马尔可夫模型(HMM)或高斯混合模型(GMM)来识别语音中的模式。辛顿等人在2012年发表的一篇开创性论文表明,深度神经网络的表现明显优于之前的这些模型。
2012年ImageNet大规模视觉识别挑战赛(ILSVRC),是将深度神经网络用于图像识别的一个决定性时刻。辛顿和他的学生亚历克斯·克里泽夫斯基(Alex Krizhevsky),还有伊尔亚‧苏茨克维(Ilya Sutskever)共同发表了一个被称为“AlexNet”的卷积神经网络(CNN),将ImageNet视觉识别上现有的错误率降低了一半,达到15.3%,比第二名低了10.8个百分点。
为什么之前看不出来这个算法的威力呢?原因很简单,之前研究者们没有大规模的训练人工智能的数据。在小规模数据上,深度学习的算法并没有很强的优势。
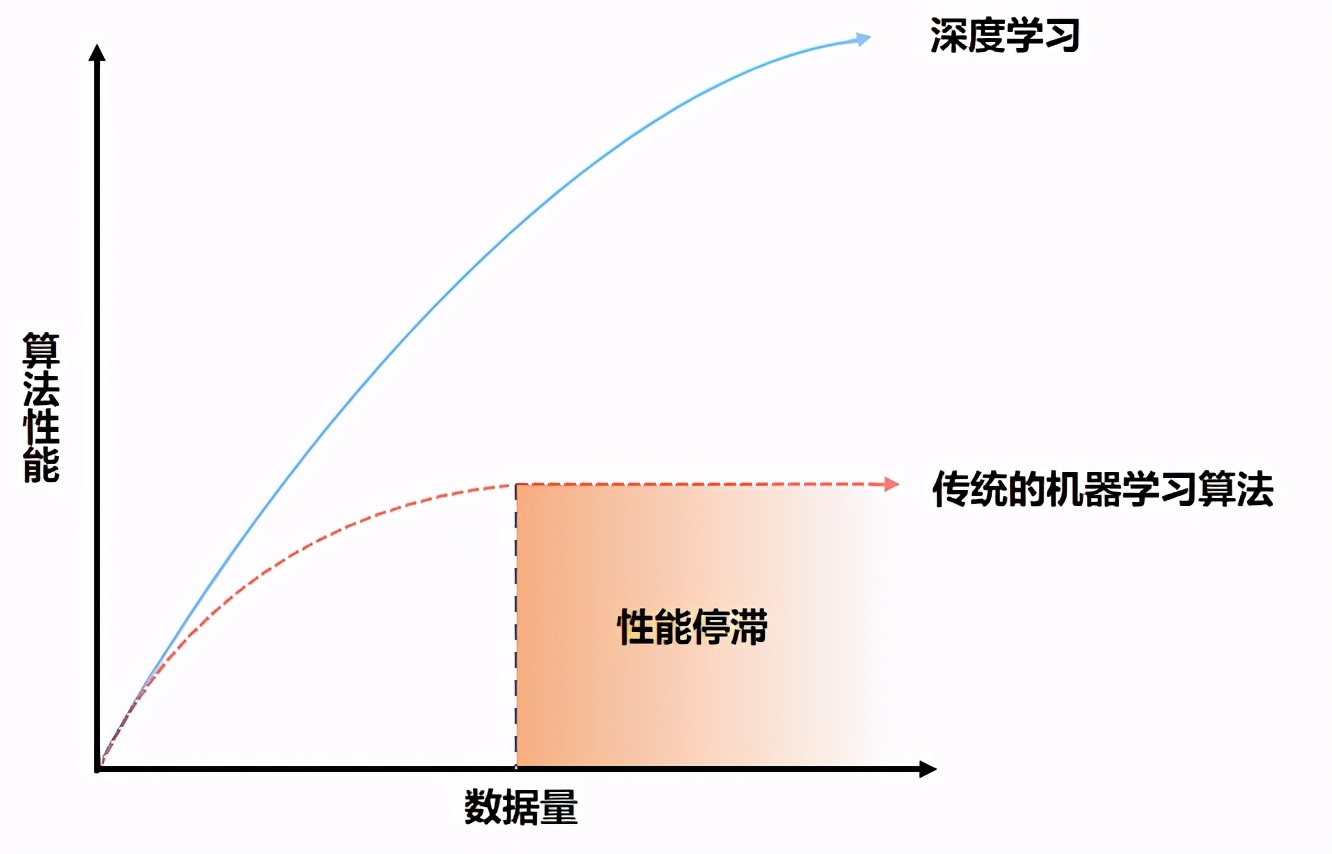
「数据规模和算法性能」
图中可以看到,传统的算法会遇到一个瓶颈,数据规模再大也没有办法提高了。但是深度学习可以随着数据规模提升而持续提高算法的表现。
这个计算机视觉比赛用的大规模数据ImageNet来自于斯坦福大学教授李飞飞的研究。她有很强的连接不同领域之间关系的洞察力。她的计算机视觉同行们那时在研究计算机感知和解码图像的模型,但这些模型的范围都很有限,他们可能会写一个算法来识别狗,另一个算法来识别猫。
李飞飞怀疑问题不是出在模型上而是出在数据上。如果一个孩子可以通过观察无数的物体和场景来学会识别物体,那么计算机也许也可以用类似的方式,通过分析大规模的各种各样的图像和它们之间的关系来学习。但是这样就要求训练模型时,有大量的打好标签的图片,告诉计算机图片里的物体都是什么。在一个有百万甚至千万张图片的数据库中标记每张图片上所有的物体是一个巨大的体力活。
2007年在普林斯顿大学担任助理教授的李飞飞提出了她对ImageNet的想法时,很难得到同事们的帮助,因为那时大家只是习惯于用几百到几千张图片的数据库。有人评论说:“如果连一个物体都识别不好,为什么还要识别几千个、几万个物体?”
李飞飞尝试给普林斯顿的学生支付每小时10美元的工资来打标签,但进展缓慢。后来有学生跟她提到了亚马逊人力外包Amazon Mechanical Turk,突然间,她可以用极低的成本雇佣许多人来打标。2009年,李飞飞的团队集齐了320万张(后来增加到1500万张)打过标的图片,他们发表了一篇论文,同时还建立了开放的数据库。
起初,这个项目几乎没有受到关注。后来团队联系了次年在欧洲举行的计算机视觉竞赛的组织者,并要求他们允许参赛者使用ImageNet数据库来训练他们的算法。这就成了ImageNet大规模视觉识别挑战赛。
历年来ImageNet挑战赛的参赛者在科技界的每个角落都能找到。2010年大赛的第一批获奖者后来在谷歌、百度和华为担任了高级职务。基于2013年ImageNet获奖算法创建的Clarifai公司后来获得了4000万美元的风险投资支持。2014年,牛津大学的两位研究人员获得冠军,他们很快被谷歌抢走,并加入了其收购的DeepMind实验室。
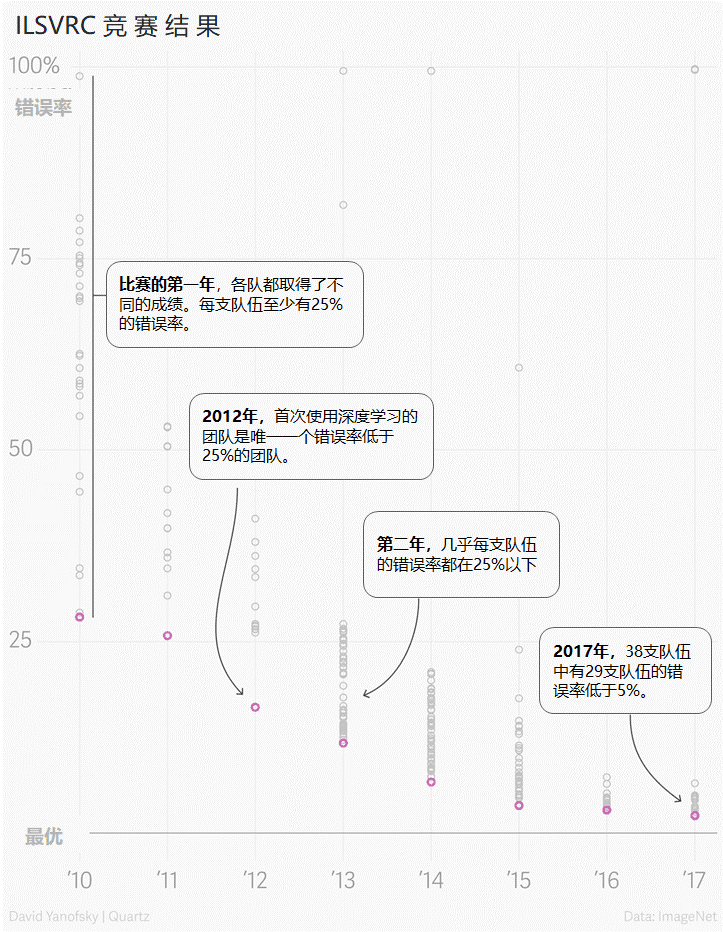
「ImageNet错误率逐年下降」
这个数据库突然激发了深度学习的潜能,让人们意识到数据的规模有时比模型的效率更重要,之前人们总是纠结在小规模数据上一点一点的推进算法准确性,而ImageNet和AlexNet让大家看到了数据规模能给人工智能带来的变革。到了2017年,也就是比赛的最后一年,计算机识别物体的错误率已经从2012年的15%降到了3%以下。2020年,很多算法都可以把错误率降低到2%以下了。
算力(并行计算)
所谓深度神经网络,说的是神经网络有好多层,每一层又有好多节点,为了计算最优的模型,要做非常大量的计算。这个方法以前不流行的原因就是它计算量太大了。在处理小规模数据时,深度学习的正确率并不比别的简单模型高,但是计算量大很多,于是并不讨喜。在2010年前后,随着并行计算越来越容易做了,这个计算量的瓶颈突然就变得不那么重要了,于是人工智能的三个必要条件就凑齐了。
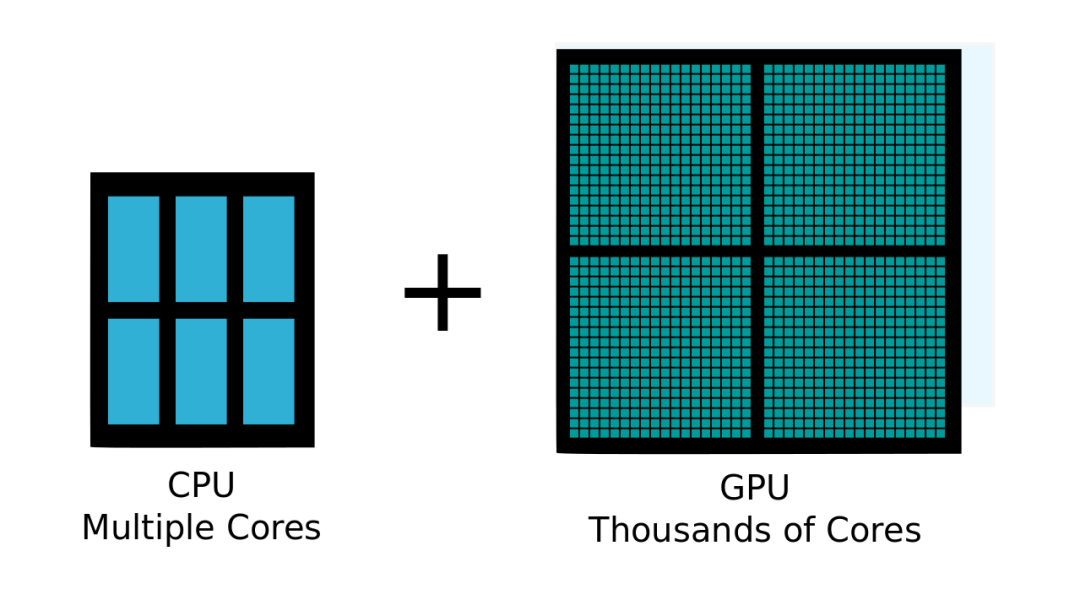
「CPU对比GPU」
并行计算可以大幅加快计算的速度。传统的有十几个内核的CPU(中央处理单元)可以同时处理十几个互相独立的运算工作。而GPU(图形处理单元)本来是用来给图形显示加速的,当需要计算复杂的图形的光影时,可以通过GPU上千的内核来做并行处理,从而大幅加快计算速度。
GPU并不适合所有的加速场景,我们遇到的很多问题是串行的,就是一个计算结束之后得到了结果才可以进入下一个计算,这样的场景还是CPU比较高效率。但是有些场景,各个计算之间相互独立,并不需要等待,而深度学习的算法恰恰就符合了这个特性。有人做过一个简单的对比,CPU就和古代军队里的将军一样,适合遇到串行问题时单打独斗;但是GPU就像士兵一样,适合在遇到并行问题时一拥而上。深度学习算法是个并行计算可以解决的问题,于是一拍即合,GPU并行计算的算力被大量应用于人工智能需要加速的场景。
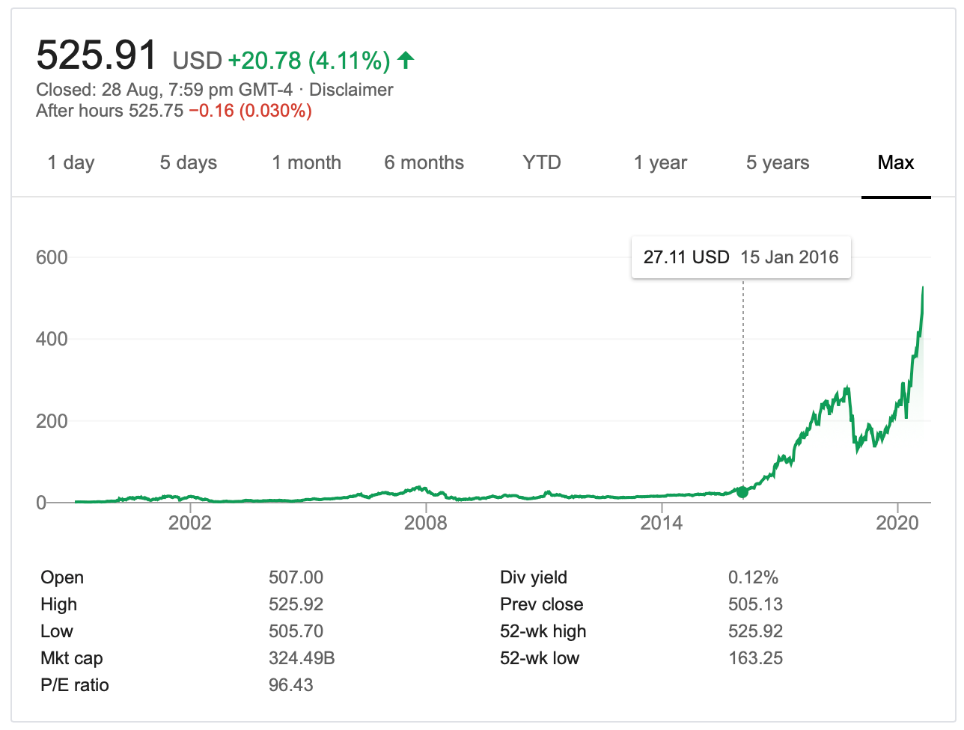
「英伟达(Nvidia)股价」
制作GPU芯片的英伟达公司的股价也一飞冲天,从2016年到现在股价已经翻了20倍。之后人们为人工智能计算又专门研制了更好的协处理器,如TPU 或 NPU,处理AI算法的效率更高。
GPU的重要性当然也和区块链、比特币的发展有关。区块链里面的Proof of Work就需要很多相互独立的计算,也是GPU可以大展身手的领域。