













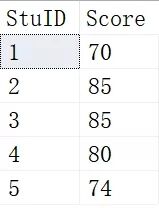
我们先创建一个测试数据表Scores
- WITH t AS
- (SELECT 1 StuID,70 Score
- UNION ALL
- SELECT 2,85
- UNION ALL
- SELECT 3,85
- UNION ALL
- SELECT 4,80
- UNION ALL
- SELECT 5,74
- )
- SELECT * INTO Scores FROM t;
- SELECT * FROM Scores
结果如下:
1、ROW_NUMBER()
定义:ROW_NUMBER()函数作用就是将SELECT查询到的数据进行排序,每一条数据加一个序号,他不能用做于学生成绩的排名,一般多用于分页查询,比如查询前10个 查询10-100个学生。
1.1 对学生成绩排序
示例
- SELECT
- ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS [RANK],*
- FROM Scores;
(提示:可以左右滑动代码)
结果如下:
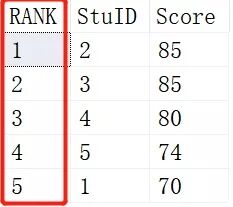
这里RANK就是每个学生的排名后的次序, 根据Score进行DESC倒序
1.2 获取第2名的成绩信息
- SELECT * FROM (
- SELECT ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS [RANK],*
- FROM Scores
- ) t WHERE t.RANK=2;
结果:

这里用到的思想就是 分页查询的思想 在原sql外再套一层SELECT
WHERE t.RANK>=1 AND t.RANK<=3 是不是就是获取前三名学生的成绩信息了。
2、RANK()
定义:RANK()函数,顾名思义排名函数,可以对某一个字段进行排名,这里和ROW_NUMBER()有什么不一样呢?ROW_NUMBER()是排序,当存在相同成绩的学生时,ROW_NUMBER()会依次进行排序,他们序号不相同,而Rank()则不一样。如果出现相同的,他们的排名是一样的。下面看例子:
示例
- SELECT ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS [RANK],*
- FROM Scores;
- SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],*
- FROM Scores;
结果:
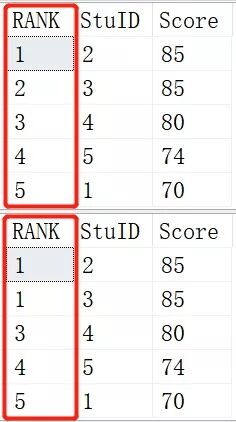
上面是ROW_NUMBER()函数的结果,下面是RANK()函数的结果。
当出现两个学生成绩相同是里面出现变化。RANK()是1-1-3-4-5,而ROW_NUMBER()则还是1-2-3-4-5,这就是RANK()和ROW_NUMBER()的区别了
3、DENSE_RANK()
定义:DENSE_RANK()函数也是排名函数,和RANK()功能相似,也是对字段进行排名,那它和RANK()到底有什么不同那?特别是对于有成绩相同的情况,DENSE_RANK()排名是连续的,RANK()是跳跃的排名,一般情况下用的排名函数就是RANK() 我们看例子:
示例
- SELECT
- RANK() OVER (ORDER BY SCORE DESC) AS [RANK],*
- FROM Scores;
- SELECT
- DENSE_RANK() OVER (ORDER BY SCORE DESC) AS [RANK],*
- FROM Scores;
结果:
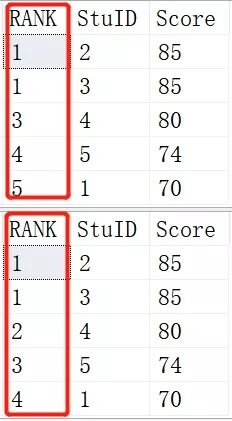
上面是RANK()的结果,下面是DENSE_RANK()的结果
4、NTILE()
定义:NTILE()函数是将有序分区中的行分发到指定数目的组中,各个组有编号,编号从1开始,就像我们说的'分区'一样 ,分为几个区,一个区会有多少个。
- SELECT NTILE(1) OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
- SELECT NTILE(2) OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
- SELECT NTILE(3) OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
结果:
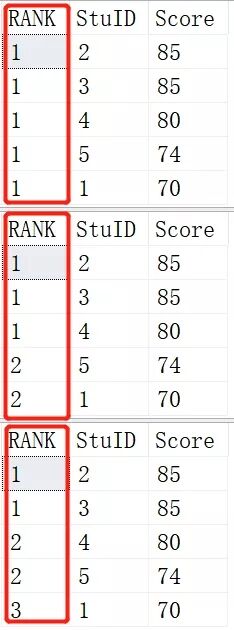
就是将查询出来的记录根据NTILE函数里的参数进行平分分区。
这几兄弟就介绍完了,有空再给大家介绍分组排名的问题。













