












在疫情的持续影响下,过去一年多的时间表明,在线交流对我们的生活十分重要。无论你身处何地,无论网络条件如何,清楚地了解彼此的在线情况从未像现在这样重要。这就是为什么 Google 在 2 月份推出了 Lyra 的原因:一个革命性的新音频编解码器,使用机器学习来产生高质量的语音通话。

为了让这个编解码器变得更加完善,Google 近日通过官方博客宣布将 Lyra 进行开源,允许其他开发者为他们的通信应用提供助力。这个版本提供了开发者使用 Lyra 进行音频编码和解码所需的工具,针对 64 位 ARM Android 平台进行了优化,并在 Linux 上进行了开发。Google 希望能够扩展这个代码库,并与社区一起开发对其他平台的支持和改进。
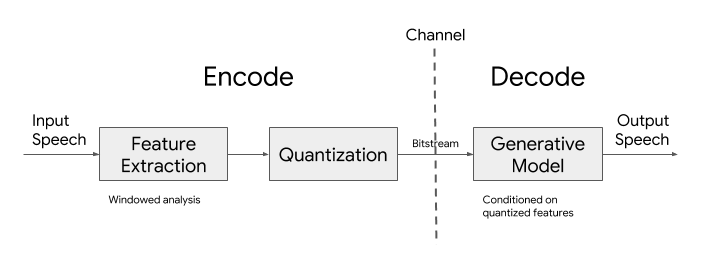
Lyra 架构
Lyra的架构分为两部分,编码器和解码器。当有人对着手机说话时,编码器会从他们的语音中捕捉独特的属性。这些语音属性,也称为特征,以40ms为单位提取,然后压缩并通过网络发送。解码器的工作是将这些特征转换回音频波形,以便通过电话听筒播放出来。
将特征解码回波形的过程是通过生成模型(Generative models)处理的,生成模型是一种特殊类型的机器学习模型,非常适合从有限的特征中重新创建一个完整的音频波形。Lyra架构与传统的音频编解码器非常相似,几十年来,传统的音频编解码器已经构成了互联网通信的主干。这些传统的编解码器是基于数字信号处理(DSP)技术,而 Lyra 的关键优势来自于生成模型重建高质量语音信号的能力。
Lyra 架构图
影响
在过去十年中,设备上计算能力的爆炸性增长超过了可靠的高速无线基础设施的建设。对于存在这种反差的地区——特别是对发展中国家而言,技术将使人们能够更紧密地联系在一起的承诺仍然遥遥无期。即使在拥有高度可靠网络环境的地区,"随时随地"工作和远程办公的出现也进一步限制了移动数据的使用。虽然 Lyra 将原始音频压缩到 3kbps,质量优于其他编解码器(如 Opus),但它并不打算成为一个完全的替代方案,而是可以在这种情况下节省带宽。
此外,Google 还认识到 Lyra 可能会有其他一些独特的应用,由于 Lyra 可以显著减少音频文件大小,因此可以用于存档大量的语音;通过利用 Lyra 编码器来节省移动设备的电量;缓解紧急情况下许多人试图同时拨打电话的网络拥堵。
开源版本
Lyra 的代码是用 C++ 所编写的,以提高速度、效率和互操作性,使用 Bazel 构建框架和 GoogleTest 框架进行彻底的单元测试,并基于 Apache 许可协议进行分发。感兴趣的用户可以访问 GitHub 查看源代码及演示。
本文转自OSCHINA
本文标题:Google 开源 Lyra 编解码器,利用机器学习减少语音通话带宽使用
本文地址:https://www.oschina.net/news/136239/google-open-source-lyra





















