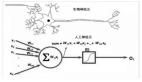
延恩·乐存与卷积神经网络
说完辛顿教授,我们来聊聊深度学习领域的另一位名人,曾经跟随辛顿教授作过博士后研究的乐存。1960年,乐存出生在法国巴黎附近,父亲是航空工程师。1988年开始,乐存在著名的贝尔实验室工作了20年。乐存目前是纽约大学终身教授,同时是Facebook的人工智能实验室负责人。乐存教授对人工智能领域的最核心贡献是发展和推广了卷积神经网络(Convolutional Neural Networks,CNN),卷积神经网络是深度学习中实现图像识别和语言识别的关键技术。和辛顿教授一样,乐存教授也是在人工智能和神经网络的低潮时期,长期坚持科研并最终取得成功的典范。正如辛顿教授所说:“是乐存高举着火炬,冲过了最黑暗的时代。”
卷积神经网络是受生物自然视觉认知机制启发而来,20世纪60年代初,大卫·休伯尔(David Hunter Hubel)和托斯坦·维厄瑟尔(Torsten Nils Wiesel)通过对猫视觉皮层细胞的研究,提出了感受野(Receptive Field)的概念。受此启发,1980年,福岛邦彦(Kunihiko Fukushima)提出了卷积神经网络的前身Neocognitron。20世纪80年代,乐存发展并完善了卷积神经网络的理论。1989年,乐存发表了一篇著名的论文《反向传播算法用于手写邮政编码的识别》(Backpropagation Applied to Handwritten Zip Code Recognition)。1998年,他设计了一个被称为Le Net-5的系统,一个7层的神经网络,这是第一个成功应用于数字识别问题的卷积神经网络。在国际通用的MNIST手写体数字识别数据集上,Le Net-5可以达到接近99.2%的正确率。这一系统后来被美国的银行广泛用于支票上数字的识别。
乐存是一位成果丰硕的计算机科学大师,不过笔者最佩服的还是他的业余爱好——制造飞机!在一次IEEE组织的深度对谈中,他和C++之父比扬尼·斯特朗斯特鲁普(Bjarne Stroustrup)有一个有趣的对话。斯特朗斯特鲁普问:“你曾经做过一些非常酷的玩意儿,其中大多数能够飞起来。你现在是不是还有时间摆弄它们,还是这些乐趣已经被你的工作压榨光了?”乐存回答:“工作里也有非常多乐趣,但有时我需要亲手创造些东西。这种习惯遗传于我的父亲,他是一位航空工程师,我的父亲和哥哥也热衷于飞机制造。因此当我去法国度假的时候,我们就会在长达三周的时间里沉浸于制造飞机。”
卷积神经网络通过局部感受野和权值共享的方式极大减少了神经网络需要训练的参数的个数,因此非常适合用于构建可扩展的深度网络,用于图像、语音、视频等复杂信号的模式识别。给你一个规模上的概念,目前用作图像识别的某个比较典型的卷积神经网络,深度可达30层,有着2400万个节点,1亿4000万个参数和150亿个连接。连接个数远远多于参数个数的原因就是权值共享,也就是很多连接使用相同的参数。训练这么庞大的模型,必然要依靠大量最先进的CPU和GPU,并提供海量的训练数据。
GPU与海量训练数据
谈到GPU和海量的训练数据,可以说说我们华人的贡献。目前多数深度学习系统,都采用NVIDIA公司的GPU通过大规模并行计算实现训练的加速,而NVIDIA公司的联合创始人和首席执行官(Chief Executire Officer,CEO),是来自中国台湾地区的黄仁勋(Jen-Hsun Huang,见图3.4)。据黄仁勋介绍,2011年,是人工智能领域的研究人员发现了NVIDIA公司的GPU的强大并行运算能力。当时谷歌大脑(Google Brain)项目刚刚取得了惊人的成果,谷歌大脑的深层神经网络系统通过观看一周的You Tube视频,自主学会了识别哪些是关于猫的视频。但是它需要使用谷歌一家大型数据中心内的16000个服务器CPU。这些CPU的运行和散热能耗巨大,很少有人能拥有这种规模的计算资源。NVIDIA及其GPU出现在人们的视野中。NVIDIA研究院的布莱恩·卡坦扎罗(Bryan Catanzaro)与斯坦福大学吴恩达教授的团队展开合作,将GPU应用于这个项目的深度学习。事实表明,12个NVIDIA公司的GPU可以提供相当于2000个CPU的深度学习性能。此后,纽约大学、多伦多大学以及瑞士人工智能实验室的研究人员纷纷在GPU上加速其深度神经网络。再接下来,全世界的人工智能研究者都开始使用GPU,NVIDIA公司从此开始了又一轮的高速成长。
图3.4 黄仁勋(左)与伊隆·马斯克(右)
在海量训练数据方面,1976年出生于北京的李飞飞教授(见图3.5)功不可没。李飞飞16岁时随父母移居美国,现在是斯坦福大学终身教授,人工智能实验室与视觉实验室主任。2007年,李飞飞与普林斯顿大学的李凯教授合作,发起了Image Net计划。利用互联网,Image Net项目组下载了接近10亿张图片,并利用像亚马逊网站的土耳其机器人(Amazon Mechanical Turk)这样的众包平台来标记这些图片。在高峰期时,Image Net项目组是亚马逊土耳其机器人这个平台上最大的雇主之一,来自世界上167个国家的接近5万个工作者在一起工作,帮助项目组筛选、排序、标记了接近10亿张备选照片。2009年,Image Net项目诞生了——这是一个含有1500万张照片的数据库,涵盖了22000种物品。这些物品是根据日常英语单词进行分类组织的,对应于大型英语知识图库Word Net的22000个同义词集。无论是在质量上还是数量上,Image Net都是一个规模空前的数据库,同时,它被公布为互联网上的免费资源,全世界的研究人员都可以免费使用。Image Net这个项目,充分体现了人类通过互联网实现全球合作产生的巨大力量。

图3.5 李飞飞
随着机器学习算法的不断优化,并得到了GPU并行计算能力和海量训练数据的支持,原来深层神经网络训练方面的困难逐步得到解决,“深度学习”的发展迎来了新的高潮。在2012年Image Net挑战赛中的图像分类竞赛中,由辛顿教授的学生埃里克斯·克里泽夫斯基教授实现的深度学习系统AlexNet获得了冠军,分类的Top5错误率,由原来的26%大幅降低到16%。从此以后,深度学习在性能上超越了机器学习领域的其他很多算法,应用领域也从最初的图像识别扩展到机器学习的各个领域,掀起了人工智能的新浪潮。
深度学习的应用
接下来我们举几个例子,来看看深度学习在各个领域的应用情况。首先来看计算机视觉领域,这方面较早实用化的是光学字符识别(Optical Character Recognition,OCR)。所谓光学字符识别,就是将计算机无法理解的图片文件中的字符,比如数字、字母、汉字等,转化为计算机可以理解的文本格式。2004年,谷歌公司发起了谷歌图书项目(http://books.google.com),通过与哈佛大学、牛津大学、斯坦福大学等大学图书馆的合作,目前已经扫描识别了几千万本图书,并可以实现全文检索,对没有版权问题的书籍,还提供PDF格式的文件下载。当笔者在谷歌图书中,打开哈佛大学图书馆珍藏的线装古本王阳明的《传习录》,还有惠能的《六祖坛经》时,心里真是非常的感动,谷歌相当于把全世界的图书馆都搬到了每个人的电脑上,真是功德无量。
计算机视觉另外两个热门的应用领域就是无人驾驶车和人脸识别。2010年,7辆车组成的谷歌无人驾驶汽车车队开始在加州道路上试行,这些车辆使用摄像机、雷达感应器和激光测距机来“看”交通状况,并且使用详细地图来为前方的道路导航,真正控制车辆的是基于深度学习的人工智能驾驶系统。2012年5月8日,在美国内华达州允许无人驾驶汽车上路3个月,经过了几十万公里的测试之后,机动车驾驶管理处为谷歌的无人驾驶汽车颁发了一张合法车牌。图3.6是谷歌无人驾驶车的设计原型。2014年,Facebook研发了Deep Face,这个深度学习系统可以识别或者核实照片中的人物,在全球权威的人脸识别评测数据集LFW中,人脸识别准确率达97.25%。

图3.6 谷歌无人驾驶车的设计原型
在不远的将来,十年以内,肯定会有很多无人驾驶车开始上路行驶。到那时,除了马路上那些固定的摄像头,又会多出无人车上成千上万的移动摄像头,配合基于深度学习的人脸识别技术和高速的通信网络,保护社会安全、抓捕罪犯的工作也许会得到很多的方便,同时,所有人的隐私也受到极大的威胁,只能祈祷人工智能的强大力量被善用了。
随着深度学习的快速发展,人工智能科学家近年来在语音识别、自然语言处理、机器翻译、语音合成等与人类语言交流相关的领域都实现了巨大的技术突破。2012年,在微软亚洲研究院的21世纪计算大会上,微软高级副总裁理查德·拉希德(Richard Rashid)现场演示了微软开发的从英语到汉语的同声传译系统,这次演讲得到了全世界的广泛关注,YouTube上就有超过100万次的播放量。同声传译系统,结合了语音识别、机器翻译和语音合成的最新技术,并且要求在很短的时间内高效完成。微软的同声传译系统,已经被应用到Skype网络电话中,支持世界各地持不同语言的人们改善交流。苹果公司的Siri、谷歌公司的Google Now等智能手机上的语音助手已经打入了很多人的日常生活,而亚马逊公司基于Alexa语音交互系统的Echo智能音箱(见图3.7)更加厉害,可以直接实现语音购物和语音支付,并且可以回答你包裹已经运到了什么地方,还能播放你喜欢的音乐、设置闹钟、叫外卖、叫Uber出租车,与智能开关、智能灯具连接后,可以把你的整个家庭变成全声控的智能家居环境。

图3.7 亚马逊公司的Echo智能音箱
对天才少年的一点建议
当然,目前这些人工智能系统还都处于比较初级的阶段,有时Siri或者Echo的回答会让你啼笑皆非,笔者也经常听到朋友逗这些语音助手取乐的故事。期待未来有更多的杰出人士投身这一领域,做出更智能更通人性的系统。如果你有家有个天才少年,笔者特别推荐一本深度学习方面的经典著作,由伊恩·古德费洛(Ian Goodfellow)、本吉奥、亚伦·库尔维尔(Aaron Courville)三位大师合作推出的Deep Learning(《深度学习》),这本书的作者非常无私,将这本书的内容和相关资料都放在互联网上让大家免费学习,网址是
http://www.deeplearningbook.org。
在本章的最后,如果要再给你家的天才少年送上一点建议,请允许笔者引述深度学习领域一位大师本吉奥(见图3.8)与学生的一个对话。2014年,本吉奥教授有一次在著名网络社区Reddit的机器学习板块参加了“Ask Me Anything”活动,回答了机器学习爱好者许多问题。
图3.8 本吉奥教授
有一个学生问:“我正在写本科论文,关于科学和逻辑的哲学方面。未来我想转到计算机系读硕士,然后攻读机器学习博士学位。除了恶补数学和编程以外,您觉得像我这样的人还需要做些什么来吸引教授的目光呢?”
本吉奥教授回答如下:
“1.阅读深度学习论文和教程,从介绍性的文字开始,逐渐提高难度。记录阅读心得,定期总结所学知识。
2.把学到的算法自己实现一下,从零开始,保证你理解了其中的数学。别光照着论文里看到的伪代码复制一遍,实现一些变种。
3.用真实数据来测试这些算法,可以参加Kaggle竞赛。通过接触数据,你能学到很多。
4.把你整个过程中的心得和结果写在博客上,跟领域内的专家联系,问问他们是否愿意接收你在他们的项目上远程合作,或者找一个实习。
5.找个深度学习实验室,申请。
这就是我建议的路线图,不知道是否足够清楚?”
献上笔者的祝福,并期待在未来的某一天,可以和你家的天才少年,或者和他/她开发的超级智能机器人相遇,也许在这个蓝色星球的某一片秀丽山河之间,也许在茫茫宇宙中飞行的太空飞船里……