在构建数据科学产品时,一个重要的方面是让您的数据可用并准备使用。您需要一个平台将数据带到一起,并在整个公司中服务。但是你如何发展这样一个数据平台?阅读数据仓库,数据湖泊,湖泊和数据网格时,很容易丢失。它们是如何不同的,什么应该是第一步?
不同的数据平台解决方案
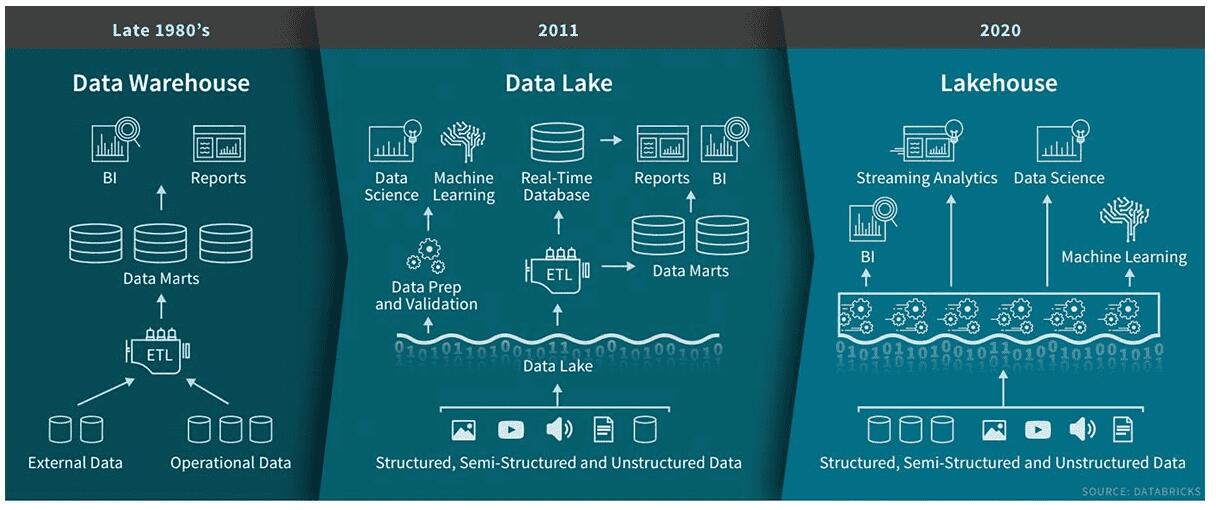 > Databricks’ perspective on DWH vs Data Lake vs Lakehouse
> Databricks’ perspective on DWH vs Data Lake vs Lakehouse
数据平台是将数据带到整个公司中的数据的环境。数据仓库是第一个企业中央数据平台。但是,随着各种数据格式和源,它们并不足够灵活。引入数据湖可以容易地从任何源以任何格式存储原始数据。这是通过推迟模式创建和数据解释来实现的,直到实际使用数据。这些湖泊经常转向所谓的数据沼泽,在那里没有人能够有效地真正使用数据。添加了所有数据,但没有准备对数据进行使用。继任者是LakeHouse,数据湖与数据库工具相结合,以轻松创建数据的可用视图。替代方案是数据网,它不会集中数据,但是利用多个分散的数据环境,以更好地跨团队进行规模。我稍后会更彻底地覆盖数据网格。
但首先,让我们看看我们实际解决的问题。这些不同数据平台的驱动程序是什么?我将从乌托邦理想开始,我们正在追逐,继续在实践中出现的平台,并用你可以采取的两步包装。在数据平台方向上的两个步骤,使机器学习解决方案,授权数据科学家,并分享内部工作方式。
乌托邦理想
如果来自所有部门的所有数据,则不会很容易访问。从一个中心位置访问,使您的所有数据科学家们可以在需要时获得所需的数据。他们可以专注于先进的机器学习,而数据工程师可以确保数据已准备好使用。
让我们见面Jane,我们的专家数据科学家。她正在开发一个新的数据科学产品:收入预测。中央数据平台提供了客户,产品和销售的所有数据。Jane在平台中构建完整数据集并将其加载到她的Jupyter Lab环境中。在与模型的目标与业务的一系列对齐之后,她很快开发了模型的第一版。
因此,该平台提供了科学家需要开发她的模型的一切,包括数据,计算和工作环境。平台开发人员(云和数据工程师)确保它是可扩展,实时和性能的。它们还提供数据谱系,数据治理和元数据等附加服务。科学家们完全赋予了工程困难。这在视觉上表示如下:
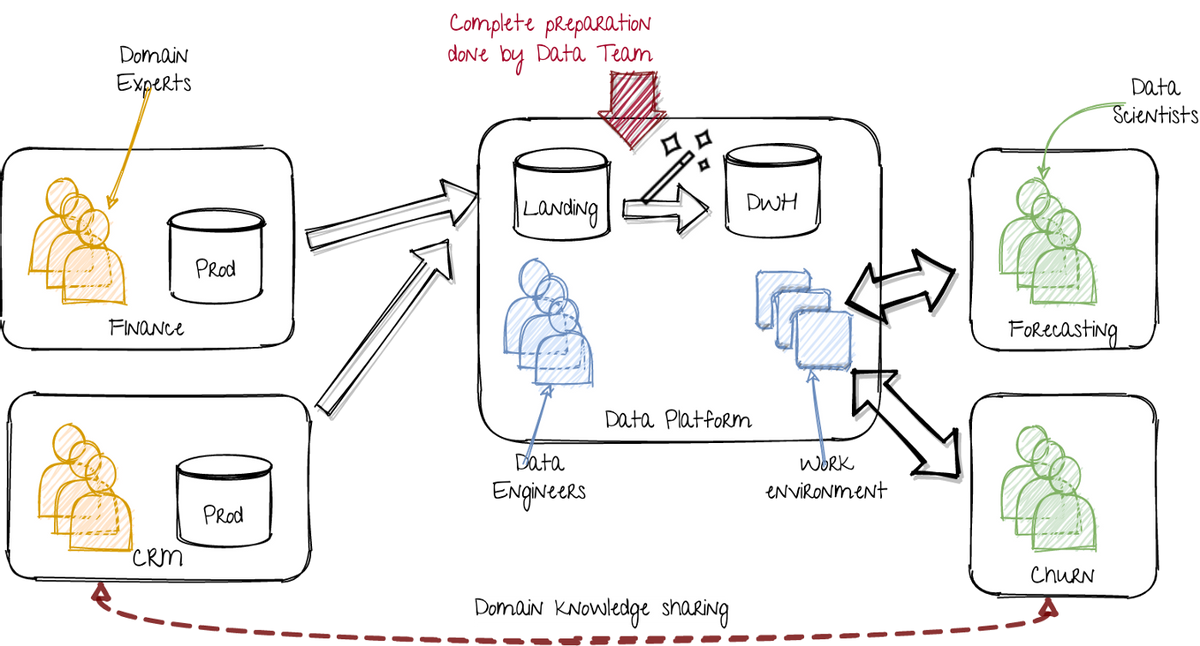
> Utopian world: Single data platform taking care of all the data issues. Image by author.
在左侧,各个部门使用相应的数据运行其应用程序。在技术产品公司中,这包括在特定领域努力的团队。数据可以居住在任何存储中:MS Excel文件,数据库,CSV文件,Kafka主题,云桶,您将其命名为。
在中间,数据平台团队提取该数据,并将其加载到数据湖的着陆区。第一步是标准化日期和数字格式和列名称的方面。这可以包括为历史观点拍摄数据的快照。生成的数据集收集存储在所谓的“暂存”图层中。然后将数据组合并放置在静电层中。策级层是包含相干数据集,唯一标识符和清晰关系的数据存储。因此,我将此称为DWH(数据仓库)。但是,它可以是任何可用存储,包括大规模云数据库(BigQuery),Hive表,Blob存储(S3)或Delta Lake Parquet文件。该策级层的目标是提供易于使用所有数据的总视图。
在右侧,数据科学团队使用平台的工作环境和数据集来解决它们的用例。
当这不起作用
理想的声音很棒。不幸的是,简的真实体验略有不同:
Jane需要一些额外的数据集可以在数据平台上提供。为了获得头部开始,金融部门为初步分析提供了一些CSV出口。简探测了预测需要在产品组上报告,而这些数据是在各个产品上。在几个会议之后,她了解哪些内部产品名称属于哪些组。产品的收入在组件中分开,部分是基础产品,部分是附加组件。折扣是另一个故事;因为它们从总账单中减去了,因此归属变得有点棘手。另一个惊喜。三个月前公共产品焕然一新,重命名,结合一些旧的利基产品。随着一些困难而且只丢弃最小的数据,她管理将旧数据与大多数类似的新产品匹配。
管理数据平台的数据工程师呢?好吧,他们只是入门:
最后,拾取了数据工程机票,数据工程师开始提取,加载和转换各种数据集。第一个步骤很容易,但现在他们需要在数据上创建可用视图。他们需要与各种(可能)未来的用户交谈以了解哪些转变很重要。他们与简言组织了一些细化会议。然后他们需要返回数据产生部门以弄清楚数据实际意味着什么,以及它如何映射到区域。该部门忙于一些新的内部产品。因此,他们将数据工程师转发给数据科学团队,这显然已经完成了一些准备工作。
简而言之,这不是非常顺利的。
有一些关键问题:
- 数据科学家需要能够创建使用情况特定的转换。
- 平台团队需要准备他们不拥有的域的数据,以便于使用案例他们无法正常工作。
- 数据平台团队成为数据科学家团队的瓶颈。
由此产生的解决方法
为了能够解释和转换与特定用例相关的高度详细数据,您需要很多域知识。每个用例还需要特定的数据准备。因此,数据工程师可以只做数据科学家所需的一部分。虽然数据科学家潜入商业案例,但他们获得了很多域名知识。这使它们能够准备数据。
这导致以下解决方法:
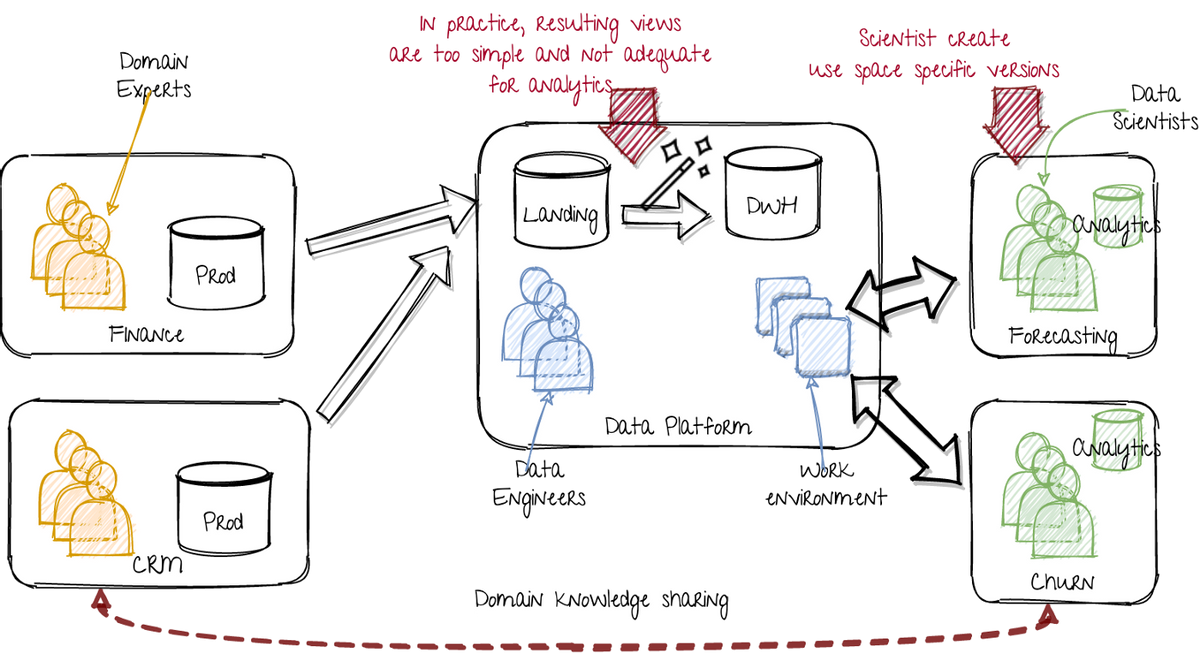
> Extra data storage within the data science teams. Image by author.
数据科学团队现在将数据从中央数据平台转换为其模型培训的准备。尽管数据平台理想地提供完全可用的数据集,但实际上它太简单,对所有客户来说都不足够了。
这种新的情况有一些好处:
- 数据科学家变得更加自我。
- 数据工程师不必为组织中的每个人创建视图。它们可以专注于数据的标准化接口。
- 数据工程师可以专注于保持数据最近并提供良好的访问方法。
但是,有些事情仍然出了问题:
- 数据科学家的数据集及其生产流水线与数据平台具有相同的标准。它们不会监视,并不适用于失败,并且任务调度并不标准化。
- 通过更分散的转换,多个数据科学团队正在重新发明众所周知的轮子。
新的理想:数据网格
稍后,已经出现了数据网格的概念(请参阅此有趣的博客文章和此操作。数据来自组织中的多个位置。数据网格而不是创建所有组合数据的单个表示,而不是创建所有组合数据的单个表示。为了使数据公司广泛可用,每个团队的数据也被视为该团队的产品。该公司的团队还要注意创建其数据的可用意见。在这种情况下,机器学习(ML)产品团队(数据科学家)还将将其转换的数据作为产品提供给其他数据科学家。他们从各种其他产品团队中获取自己的数据。因此,每个产品团队(或团队团队)不仅开发了他们的产品,而且还向其他团队提供了可用的景色。在我解释的是优势之前,让我画出新的情况:
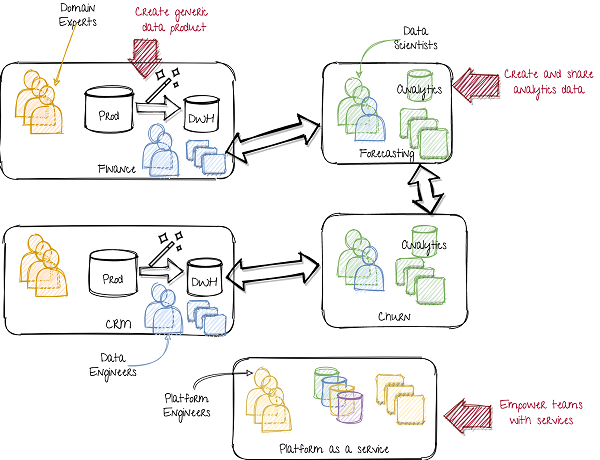
> A data mesh approach. Image by author.
在左侧,部门或产品团队将通用数据作为服务提供。虽然一组规范化表(DWH)是一种可能性,但它也可以包括事件流(Kafka)或Blob存储。这需要产品团队中的更多数据工程功能。而不是带有数据工程师的中央团队,数据工程师现在正在分布在所有产品团队中,包括分析和ML团队。
在中间,中央数据平台已从数据产品团队(要求域知识)更改为数据平台作为服务团队(需要技术知识)。他们开发内部平台,授权所有团队创建自己的数据存储实例,功能存储,数据处理,数据谱系,调度,过程监控,模型工件,模型服务实例等。因此,先前数据平台团队的所有技术技能都用于创建工具。这样,每个团队都可以成为自己(小规模)数据平台团队。这确保了整个公司的工作和高标准的统一方式。
在右侧,数据科学团队不仅是数据的消费者,还不仅是数据的制作者。他们的特征工程和数据宣传的结果与其他数据科学团队共享。
这有很多好处:
- 在域知识是创建的转换。
- 数据平台团队瓶颈被删除。
- 自给自足的产品团队。
挑战是:
- 将中心平台设置为服务团队。
- 防止新的中央数据平台成为成为新瓶颈的服务团队。
- 以共同的工作方式将所有团队纳入这种新方法。
在此设置中,中央平台作为服务团队(或团队)具有关键作用。它们以简单的自行服务方式设置并提供基础架构和软件服务。当他们创建平台作为服务时,该团队不需要大量的域特定知识。它只专注于技术方面,使其成为可重复的,并与所有团队分享解决方案。这促进设置尺度非常好!我的同事Ruurtjan阵列在这个博客中展示了如何从团队成分角度来实现缩放。然而,有一个大风险:采取瀑布方法。
数据网格方法解决了与数据重用相关的域知识的难度。这是通过将数据的责任移动到生产和使用该数据的团队的责任来完成。而不是拥有所有数据的中央团队,我们现在需要一个中央团队,以方便所有团队管理他们的数据。
陷阱是在让这个中央团队开始和运行时采取瀑布方法。在船上之前,不要创建所有必需的基础架构和服务。只要没有使用服务的单一团队,就没有增加值。因此,您需要迭代地增长和改善服务,而团队则可以使用它。
第二个风险是使平台成为服务团队决定了工作方式。这将使团队成为整个公司的瓶颈。在敏捷和迭代的方法中,一些团队需要新的工具或服务,该服务尚未为公司采用准备好生产。作为服务团队的平台,而不是限制那些早期的采用者,而是应该允许和赋予新工具和服务的发现和试验。让他们授权产品团队并加入军队。这将为两支球队提供分享工具和服务的经验进一步跨本公司。
是否可以转换到数据网?是否有可能在中央数据平台和数据网之间具有内容?我们如何务实地采取第一步?我们尽快收获尽快收益。在一个针对您组织的基础架构功能上量身定制的解决方案中。此帖子的其余部分将解释如何转换到可实现机器学习解决方案,授权数据科学家的数据平台的转换,并分享内部工作方式。
第一步:轻量级的中央数据平台
您可以创建该数据平台的第一步是什么?不幸的是,没有饼干刀模板。该方法应依赖于具体情况,包括现有的技术堆栈,可用技能和能力,流程和一般Devops以及MLOPS成熟。我可以给你通用的建议,希望有一个有用的渗透率。
一种方法是将以前版本的优势与未来的垫脚石结合起来,更高级版本(如数据网格):
- 数据工程师专注于提取和负载,变换最小。
- 域特定(数据科学)团队专注于高级转换。
- 工具应提供授权团队。
该方法是创建一个轻量级的中央数据平台,包括以下步骤:
- 使用特定用例拍摄一个数据科学团队。
- 设置一支团队,包括平台工程师和数据工程师。
- 该平台工程师提供数据科学团队,其中包含分析环境,包含至少存储和处理。
- 数据工程师从源表中加载原始数据,添加基本标准化转换,并将其提供给使用案例团队。与平台工程师一起,他们创造了所需的服务。
- 数据科学家与数据平台工程师合作,在调度,运行和运行数据转换,模型训练循环和模型服务时,可以成为自我。他们与数据工程师合作,专业化其数据转换。
在这种情况下,数据科学家仍然必须做很多数据播种。但是,我们接受它而不是假设不会发生,而是为他们提供最佳工作的工具。
这种方法的一个关键方面是从一个用例开始焦点。数据工程师,平台工程师和数据科学家首先解决这一案例。与此同时,他们在稍后开发必要的工具方面获得经验。
结果如下:
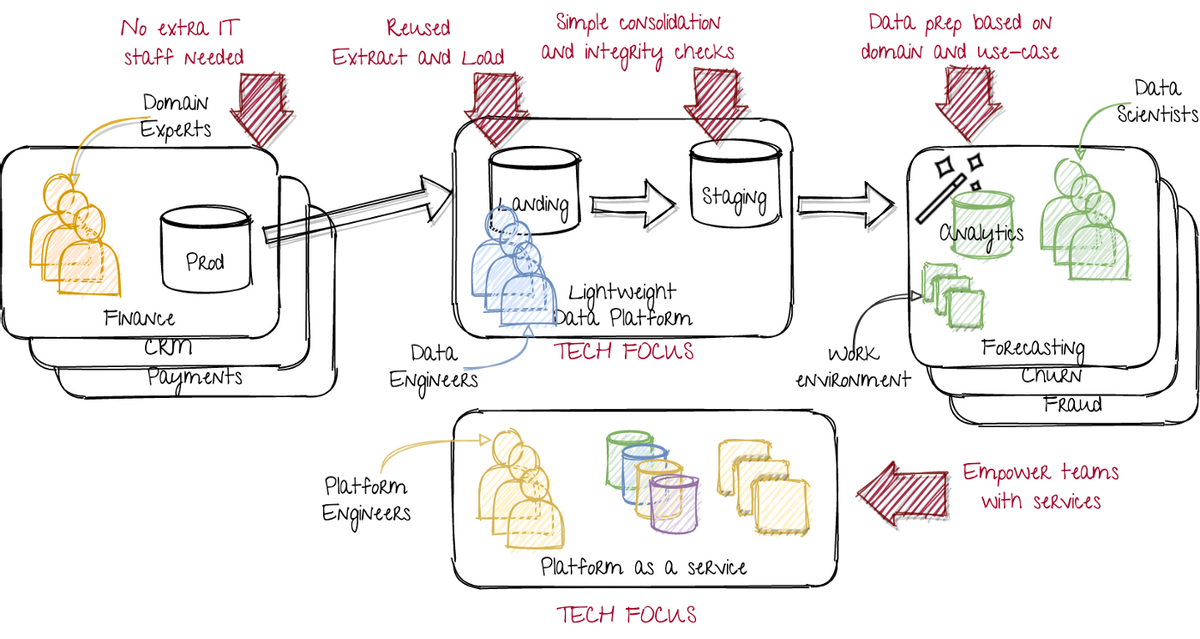
> A lightweight data platform, as a step toward the data mesh. Image by author.
在左侧,我们保留了原始情况,部门或产品团队只是开发或运营生产实例。这限制了公司广泛的变化。
在中间,数据工程师专注于具有高质量管道的轻量级数据建模。他们主要有助于加载数据,并提供标准化的访问方法。他们具有强大的技术焦点,包括基础设施和服务。
在右侧,数据科学团队专注于根据所有必需的域知识创建数据产品。他们通过从客户(使用他们的数据产品)和上游数据来源的团队来获得所述域知识。他们运行所有必需的分析和转换,同时由平台作为服务团队支持。他们有一个强大的领域和用例焦点。
在底部,平台作为服务团队的工作组件创建可重用组件。因此,他们具有技术焦点。他们为具有域名焦点的数据科学团队提供服务。作为服务团队的平台应由其要求推动。
下一步:跨团队扩展和分享
下一步是扩展。可以在各种维度上完成缩放,包括获取更多源数据集,接入更多的数据科学团队,或者将更多的授权平台添加为服务(思考要素存储,型号,依此类推)。同样,这些选择取决于情况。
目前,让我们参加一个典型的步骤:接入更多数据科学团队。第一支球队的登上队确保了发达的服务很有用。第一个团队是推出的客户。作为服务团队的平台确保了良好的市场适合内部客户。下一个团队应该更快,更顺利地运行。
使用多个团队使用该服务,下一个障碍将是允许在数据科学团队之间共享数据。这可能需要服务的一些变化和工作方式。但如果达到该里程碑,平台倡议将真正改善所有后续团队的生活。这导致以下情况:
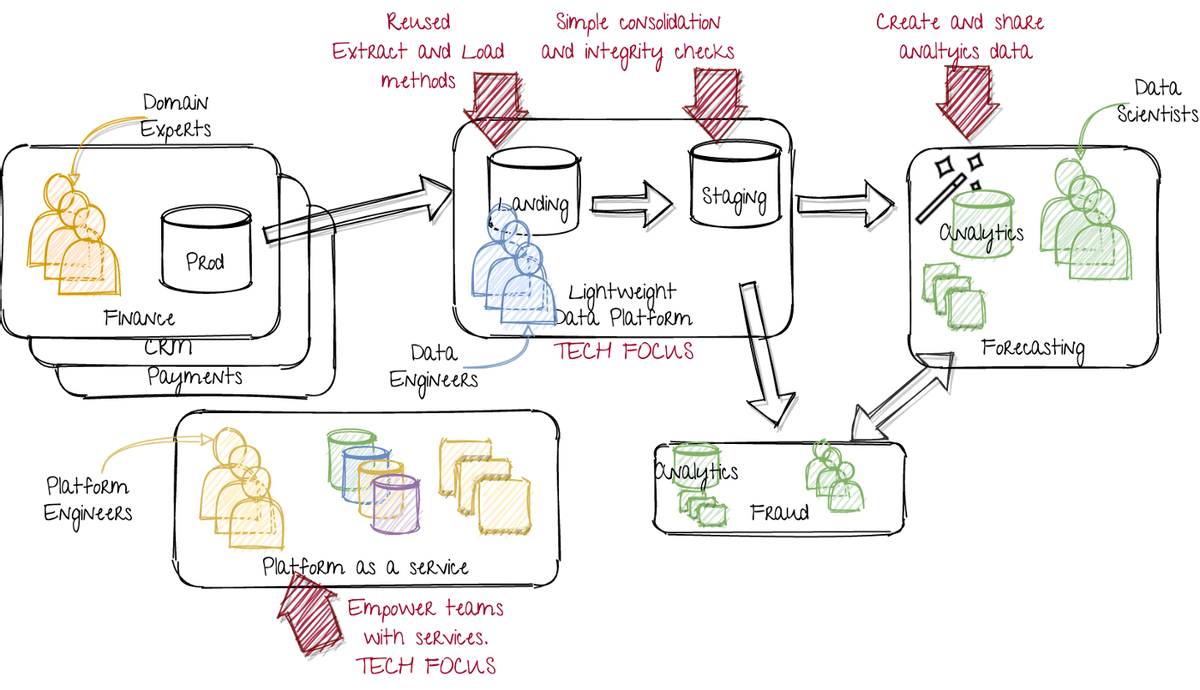
> Scaling up by on-boarding more teams
与上一个图像相比,我们现在有一个额外的数据科学团队,开发欺诈检测产品。他们应该能够从平台工程师中重用开发的服务并从第一支预测团队中重复使用数据。
以下步骤:专业化和缩放
不要忘记这些数据平台举措的目标。目标是启用更多数据产品。因此,除了登上多个数据科学团队,还可以努力向生产模式工作。授权第一个(少数)团队实际嵌入他们的模型预测到业务中。
使用这些平台,流程和工作方式,下一步不太清楚。有很多机会可以提高服务素质和团队合作。
根据业务需求,可以提高所提供服务的质量。也许需要一个实时特征存储,一个新的型号服务平台,自动ml工具或更好的模型监控?
就球队的一致性而言,可能需要一些班次。也许很多案例需要一个“客户360视图”,这可能导致创建一个团队来管理该统一视图,具有一些自动生成的功能。各种类似的常见问题可以用作创建新的常见解决方案的主动性。
总结
通过对其开发的敏捷方法,我已经显示了一种朝着更多数据驱动组织移动的方式。该帖子希望将您的情况进行比较,而不是将任何解决方案提出“最佳方式”。
这种方法的关键组成部分是:
- 敏捷(内部)客户集中的方法。
- 平台思考。
- 删除瓶颈,同时提供一个灵活性的平台,并赋予数据科学团队。
- 自由团队,自由和自主。它们可以自由地使用适合它们的服务,并可以自主准备他们的数据。