本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
最新轻量级多语言NLP工具集Trankit发布1.0版本,来自俄勒冈大学。
基于Transformer,性能已超越之前的热门同类项目斯坦福Stanza。
Trankit支持多达56种语言,除了简体和繁体中文以外,还支持文言文。
先来看一组Trankit与Stanza对文言文进行依存句法分析的结果。
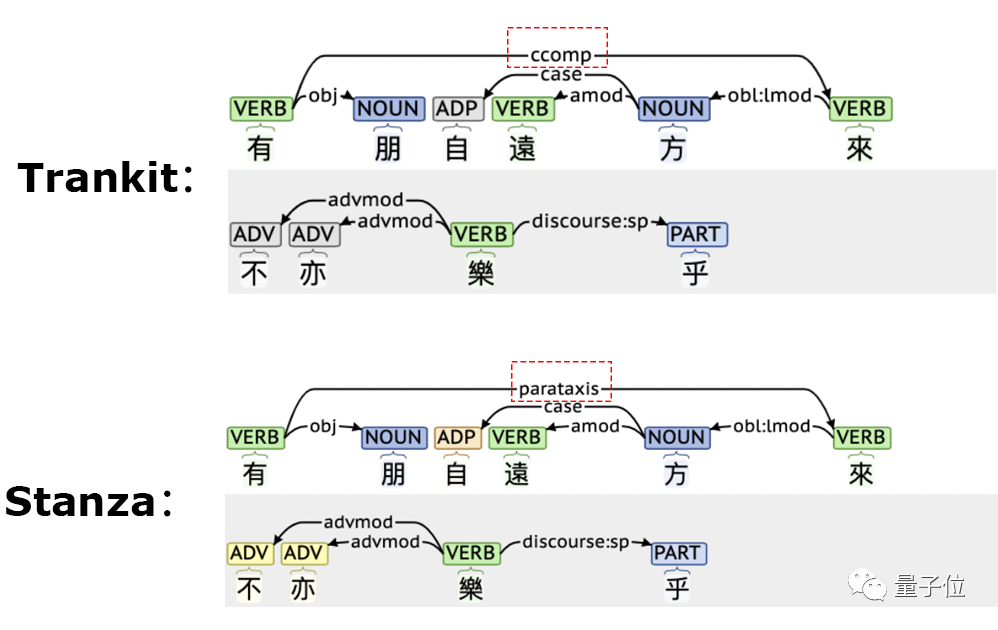
可以看到,Stanza错误的将“有朋自远方来”中的“有”和“来”两个动词判断成并列关系。
在简体中文的词性标注任务上,Trankit对“自从”一词处理也更好。

与Stanza一样,Trankit也是基于Pytorch用原生Python实现,对广大Python用户非常友好。
Trankit在多语言NLP多项任务上的性能超越Stanza。
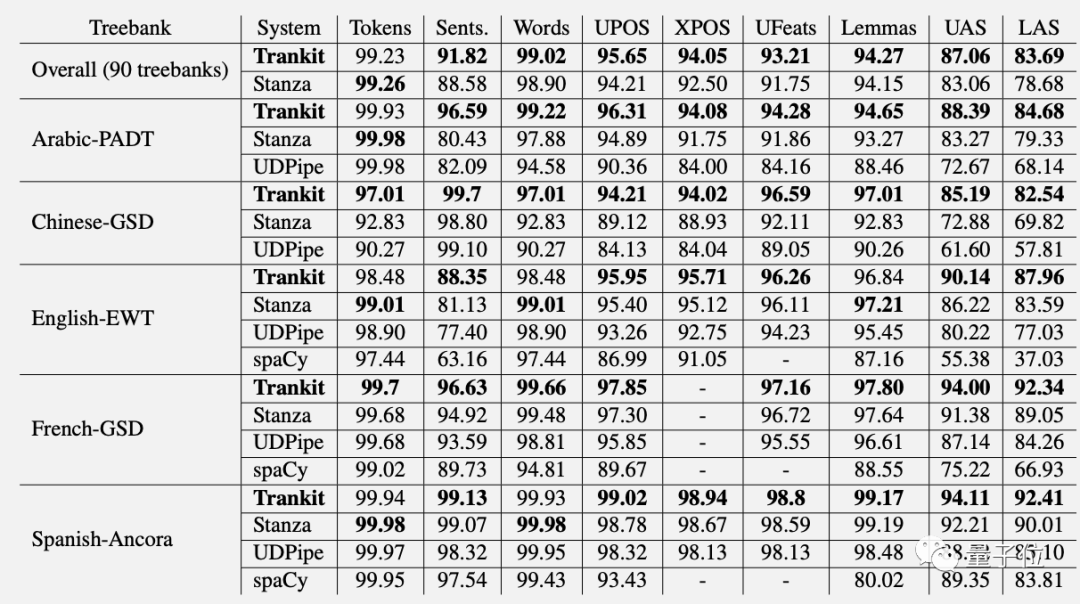
在英语分词上的得分比Stanza高9.36%。在中文依存句法分析的UAS和LAS指标上分别高出14.50%和15.0%。
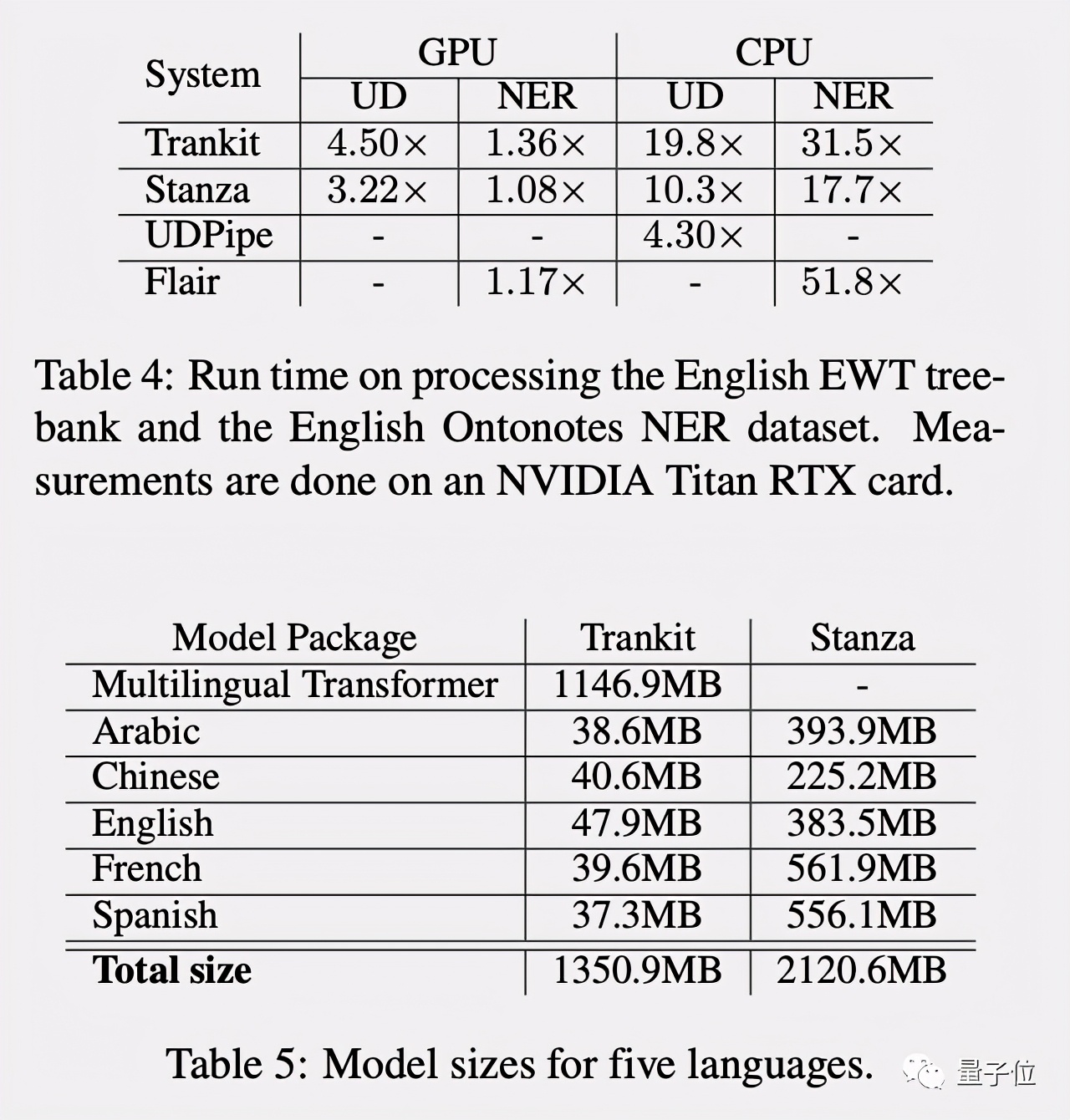
Trankit在GPU加持下加速更多,且占用内存更小,作为一个轻量级NLP工具集更适合普通人使用。
简单易用
Trankit的使用也非常简单,安装只要pip install就完事了。
pip install trankit
- 1.
不过需要注意的是,Trankit使用了Tokenizer库,需要先安装Rust。
初始化一个预训练Pipeline:
from trankit import Pipeline
# initialize a multilingual pipeline
p = Pipeline(lang='english', gpu=True, cache_dir='./cache')
- 1.
- 2.
- 3.
- 4.
开启auto模式,可以自动检测语言:
from trankit import Pipeline
p = Pipeline('auto')
# Tokenizing an English input
en_output = p.tokenize('''I figured I would put it out there anyways.''')
# POS, Morphological tagging and Dependency parsing a French input
fr_output = p.posdep('''On pourra toujours parler à propos d'Averroès de "décentrement du Sujet".''')
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
使用自定义标注数据自己训练Pipeline也很方便:
from trankit import TPipeline
tp = TPipeline(training_config={
'task': 'tokenize',
'save_dir': './saved_model',
'train_txt_fpath': './train.txt',
'train_conllu_fpath': './train.conllu',
'dev_txt_fpath': './dev.txt',
'dev_conllu_fpath': './dev.conllu'
}
)
trainer.train()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
统一的多语言Transformer
Trankit将各种语言分别训练的Pipelines整合到一起共享一个多语言预训练Transformer。
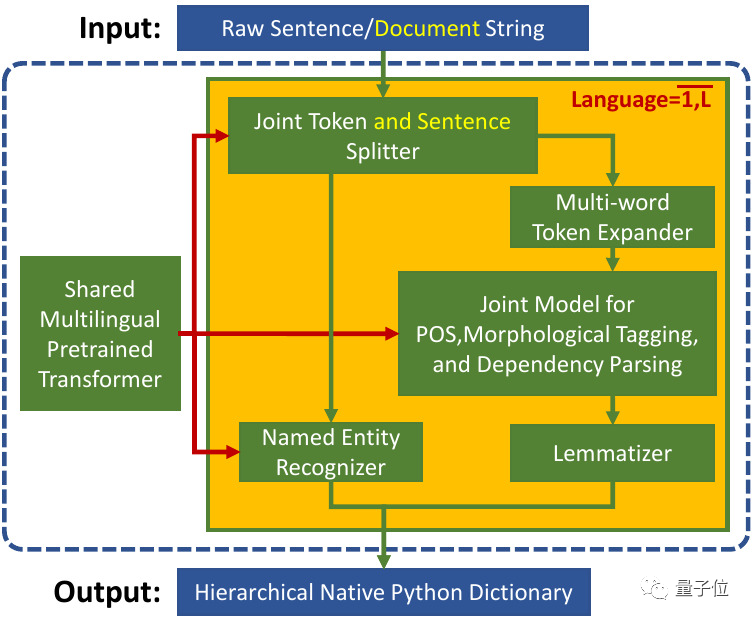
然后为每种语言创建了一组适配器(Adapters)作为传统的预训练模型“微调(Fine-tuning)”方法的替代,并对不同的NLP任务设置权重。
在训练中,共享的预训练Transformer是固定的,只有适配器和任务特定权重被更新。
在推理时,根据输入文本的语言和当前的活动组件,寻找相应的适配器和特定任务权重。
这种机制不仅解决了内存问题,还大大缩短了训练时间。
Trankit团队在实验中对比了另外两种实现方法。
一种是把所有语言的数据集中到一起训练一个巨大的Pipeline。另一种是使用Trankit的方法但把适配器去掉。

在各项NLP任务中,Trankit这种“即插即用”的适配器方法表现最好。
团队表示,未来计划通过研究不同的预训练Transformer(如mBERT和XLM-Robertalarge)来改进Trankit。
还考虑为更多语言提供实体识别,以及支持更多的NLP任务。
Github仓库:
https://github.com/nlp-uoregon/trankit
在线Demo:
http://nlp.uoregon.edu/trankit
相关论文:
https://arxiv.org/pdf/2101.03289.pdf