前言
nodejs的出现为前端行业带来了无限的可能性,让很多原来只负责客户端开发的同学也慢慢开始接触和使用服务器端技术.
虽然nodejs带来了很多的好处,但是它也存在自身的局限性.和那些传统老牌的编程语言相比,如JAVA,PHP.nodejs并不能成为它们的替代品,而且在可预估的未来,也很难撼动那些老牌编程语言的地位.
目前nodejs主要有以下几个应用场景.
- 前端工程化,比如rollup,webpack在工程化方向的探索
- nodejs中间层
- 客户端集成nodejs,比如electron
- 市面上一些不太复杂的应用选择nodejs作为后端编程语言
本文主要讲一讲nodejs作为中间层的一些实践,查看下图.
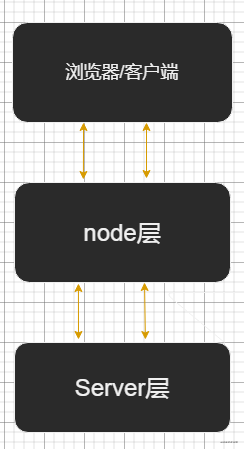
传统的的开发模式由浏览器直接和Server层直接通信,中间层的加入意味着在浏览器和Server层之间额外添加了一层.
原来客户端直接向Server发送请求,Server层收到请求后经过计算处理将结果返回给浏览器.
如今浏览器将请求发送给node层,node层经过一轮处理后再向Server层发起请求.Server层处理完毕将响应结果返回给node层,node层最后将数据返回给浏览器.
因为node层的出现,Server层可以只用关注业务本身,而不必理会前端对字段的特殊要求。
node层可以向server层获取数据,再通过对数据的计算整合转换成符合前端UI要求的数据格式.另外整个应用如果采用微服务架构,那么Server层会有很多台管理单独业务模块的服务器,node层就很好的适配了微服务的架构,它可以向多台服务器发起请求获取到不同模块的数据再整合转化发送给前端.
下面着重介绍一下nodejs作为中间层的部分实践.
代理转发
代理转发在实际中有很多广泛的应用.浏览器首先将请求发送给node服务器,请求收到后node服务器可以对请求做一些处理,比如将原来的路径变换一下,请求头的信息改变一下,再把修改后的请求发送给远程真实的服务器.
远程服务器计算出响应结果再返回给node服务器,node服务器仍然可以对响应做选择性处理再分返回给浏览器.
代理转发可以解决前端日常开发中经常遇到的跨域问题,另外它还屏蔽了远程真实服务器的细节,让浏览器只与node服务器通信.下面是简单的实践.
- const express = require('express');
- const { createProxyMiddleware } = require('http-proxy-middleware');
- const app = express();//创建应用
- app.use("/api",createProxyMiddleware( //设置代理转发
- {
- target: 'http://www.xxx.com', //举例随便写的地址
- changeOrigin: true,
- pathRewrite: function (path) {
- return path.replace('/api', '/server/api');
- }
- })
- );
- app.use("*",(req,res)=>{ //不是以'/api'开头的路由全部返回"hello world"
- res.send("hello world");
- })
- app.listen(3000);
http-proxy-middleware是一个第三方依赖包,可以非常方便设置代理转发,需要通过npm安装.
如果当前访问的路径是以/api开头,那么该请求就会被http-proxy-middleware拦截.观察http-proxy-middleware里面配置的参数.
- target代表远程真实服务器的地址.
- changeOrigin设置为true,表示将请求转发到target地址上.
- pathRewrite是对请求路径做一下处理,将/api转换成/server/api.
上面的案例意思很明显,假如当前浏览器访问http://localhost:3000/api/list.因为这个路径以/api开头所以会被拦截,从而触发pathRewrite函数修改访问路径.最终访问路径就变成了http://www.xxx.com/server/api/list,然后就会向这个路径发起请求,得到响应后再返回给浏览器.
接口聚合
上面介绍的接口转发在实践中很少会单独应用,如果仅仅只是为了转发一下数据,那还不如直接用nginx配置一下,转发就搞定了.
如果接口聚合和接口转发都需要,那么从代码层面去解决还是优先考虑的方式.
接口聚合是什么意思呢?假设现在企业有两个销售体系,一个是线上的电商平台销售,另一个是线下实体店.它们分别属于不同的团队运营,维护着不同的数据系统.
如果当前请求只是想查询一下电商平台某款商品的信息,只需要将接口转发给电商平台系统即可.同理如果仅仅只是查询线下实体店某一天的销售业绩,可以直接把请求转发给线下数据系统查询,再把响应数据返回.上面介绍的插件http-proxy-middleware支持配置多个代理路径,详细可查询文档.
现在有这么一个需求,目标是查询本周某款商品在线上和线下销售数据的对比.那么这个时候就需要node层向两个远程服务器发送请求分别获取线上销售数据和线下销售数据,将这两部分数据聚合处理后再返回给前端.简单实践如下.
- const express = require('express');
- const { createProxyMiddleware } = require('http-proxy-middleware');
- const app = express();//创建应用
- //伪代码
- app.get("/getSaleInfo",async (req,res)=>{
- const online_data = await getOnline(); //获取线上数据
- const offline_data = await getOffline(); //获取线下数据
- res.send(dataHanlder(online_data,offline_data)); //对数据处理后返回给前端
- })
- proxyHanlder(app);//伪代码,将代理转发的逻辑封装起来
- app.use("*",(req,res)=>{
- res.send("hello world");
- })
- app.listen(3000);
/getSaleInfo代表着将两条数据聚合的自定义路由,如果需要聚合数据的需求比较多,这块逻辑要单独封装到路由模块中管理,并且要写在代理转发的前面.
这样就确保了需要转发的接口就交给转发的逻辑处理,需要个性化处理数据的接口就单独编写路由操作数据.
数据缓存
缓存对于提升系统性能,减小数据库压力起到了无足轻重的作用.一般常用的缓存软件是redis,它可以被理解成数据存储在内存当中的数据库.由于数据放在内存中,读写速度非常快,能极快的响应用户的请求.
在node层部署redis管理缓存数据,可以提升整体应用性能.但不是什么数据都建议存放在redis中,只有那些不经常变动的数据应该设置成缓存.
比如商品的信息数据,浏览器对某个商品发起请求,想查看该商品的详情.请求第一次到达node层,redis此时是空的.那么node开始请求server层得到响应结果,此时在将响应结果返回给浏览器之前,将该次请求的访问路径作为key值,响应结果作为value存储到redis中.这样之后再有相同的请求发来时,先查看redis有没有缓存该请求的数据,如果缓存了直接将数据返回,如果没有缓存再去请求server层,把上述流程再走一遍.
redis还可以对缓存数据设置过期时间和清除,可以根据具体的业务操作.简单实践如下.
- const express = require('express');
- const app = express();//创建应用
- //伪代码
- app.use("*",(req,res,next)=>{
- const path = req.originalUrl; //获取访问路径
- if(redisClient.getItem(path)){ //查看redis中有没有缓存该条接口的数据
- res.send(redisClient.getItem(path)); // 返回缓存数据
- }else{
- next(); //不执行任何操作,直接放行
- }
- })
- aggregate(app); //伪代码,将接口聚合的逻辑封装起来
- proxyHanlder(app);//伪代码,将代理转发的逻辑封装起来
- app.use("*",(req,res)=>{
- res.send("hello world");
- })
- app.listen(3000);
接口限流
node做中间层可以对前端无节制的访问做限制.比如有些恶意的脚本循环访问接口,一秒钟访问几十次增大了服务器的负载.
redis可以帮助我们实现这一功能.用户第一次访问,解析出本次请求的ip地址,将ip作为key值,value置为0存到redis中.
用户第二次访问,取出ip找到redis中对应的value,然后自增1.如果是相同的人重复大量访问,value在短期内就自增到了很大的数字,我们可以每次获取这个数字判端是否超过了设定的预期标准,超过则拒绝本次请求.简单实践如下.
- const express = require('express');
- const app = express();//创建应用
- //伪代码
- app.use("*",(req,res,next)=>{
- const ip = req.ip;
- let num = 0;
- if(redisClient.getItem(ip)){ //是否缓存了当前的ip字段
- num = redisClient.incr(ip); //每访问一下,计数加1
- }else{
- redisClient.setItem(ip,0);
- redisClient.setExpireTime(5); //设置过期时间为5秒,5秒后再获取该ip为空
- }
- if(num > 20){
- res.send("非法访问");
- }else{
- next();//放行
- }
- })
- cacheData(app)//伪代码.缓存接口数据
- aggregate(app); //伪代码,将接口聚合的逻辑封装起来
- proxyHanlder(app);//伪代码,将代理转发的逻辑封装起来
- app.use("*",(req,res)=>{
- res.send("hello world");
- })
- app.listen(3000);
在应用的前面设置一层限流中间件,每次访问来临先判端是否缓存过.第一次访问肯定没有缓存,就将当前ip对应的值设置为0并添加过期时间为5秒钟.下一次相同的用户再访问时就会将value自增1.
最后的效果就达到了5秒内调用接口的次数超过20次便拒绝访问.
日志操作
系统没有日志,相当于人没有双眼.日志可以帮助我们发现分析定位线上系统出现的错误.另外通过日志数据也可以进行统计计算得出某些结论和趋势.
node层能够承担起管理日志的功能,以接口访问日志为例.在系统中新建一个日志文件夹,每次有请求访问时,首先解析请求的路径、当前的访问时间以及携带的参数和终端数据信息.然后在日志文件夹创建一个txt文件存放当天日志情况,将上述数据和该请求的响应结果组合成一条记录插入txt文件中.下一次访问继续走上面流程往txt文件添加访问日志.像上面介绍的代理转发,插件http-proxy-middleware支持配置如何返回响应结果,那么在相应的事件函数钩子里就可以同时得到请求和响应,有了这两块数据就可以存放到日志中.
这里还能制定很多的配置策略.可以选择一天一个日志文本,如果访问量巨大也可以选择一个小时一个日志文本,依据实际情况而定.
另外随着时间的延长,日志文件夹的文件内容会越来越多.这就需要编写linux操作系统定时任务来迁移和备份这些日志数据.
日志操作简单实践如下.
- //伪代码
- app.use("/getList",async (req,res)=>{
- const list = await getProductList(); //获取商品数据
- const { 访问时间,访问路径,参数 } = req;
- logger.log('info',`${访问时间}-${访问路径和参数}:${list}`);//将数据存储到日志文件中
- res.send(list);//将结果返回给客户端
- })
结尾
中间层另外还可以做很多其他事情,比如监控、鉴权和服务器端渲染(SSR).这部分由于内容比较多可以单独成章,网络上也有大量如何实践的文章,可搜索查阅学习.
其实上面所谈到的所有功能其他编程语言都可以做到,这也成为了很多人质疑是否需要在架构上额外再加一层的顾虑.
添加nodejs中间层,对于前端同学来说肯定是好消息.因为它能让前端承担更多的工作任务,让前端的业务比重变大.另外后端从此只需要关注自身业务,前端继续干着自己擅长的事,从整体上是能提升开发效率.
但从宏观角度上看,架构额外增加一层势必会造成整个应用性能上的损耗,另外在部署,测试层面都会增大运维成本.
当下前后端分离已经成为了主流的开发模式,很多类型的应用需要seo的支持以及首屏加载速度,因此服务器端渲染不可或缺.前端项目目前大多采用react或vue框架开发,如果用nodejs承担服务器端渲染的任务,那么可以确保一套代码既可以做客户端渲染也能支持服务器端渲染,而这些工作都可以让前端程序员独立来完成.服务器端渲染技术非常重要,后面会开一个小节单独讲解.
综上来看,nodejs做中间层最有价值的功能是服务器端渲染和接口数据聚合.如果企业应用数量较少业务简单还没有规模化,不建议添加中间层,那样反而让简单的事情变得复杂.