












在处理一些复杂逻辑时候,python这种面向过程的语言相比于SQL更符合人的思维方式。相信有不少同学曾经感慨,如果能用python处理数据库中的数据就好了。那么今天它来了。
首先用python写处理复杂逻辑的自定义的函数(一阳指),再将函数代码嵌入SQL(狮吼功)就能合并成了一整招:UDF
下面我用一个栗子来说明一些两者处理数据过程中的差异,在介绍栗子之前,先介绍一些with as。与python 创建函数或者类一样,with as 用于创建中间表
简单来做个介绍
- select
- *
- from(select * from table where dt='2021-03-30')a
可以写成
- with a as (select * from table where dt='2021-03-30' )
- select * from a
简单的SQL看不出这样的优势(甚至有点多此一举),但是当逻辑复杂了之后我们就能看出这种语法的优势,他能从底层抽取中间表格,让我们只专注于当前使用的表格,进而可以将复杂的处理逻辑分解成简单的步骤。
如下面地表格记录了用户适用app过程中每个行为日志地时间戳,我们想统计一下用户今天用了几次app,以及每次的起始时间和结束时间是什么时候,这个问题怎么解呢?

SQL实现方式
首先用with as 构建一个中间表(注意看on 和 where条件)
- with t1 as
- (select
- x.uid,
- case when x.rank=1 then y.timestamp_ms
- else x.timestamp_ms
- end as start_time,
- case when x.rank=1 then x.timestamp_ms
- else y.timestamp_ms end as end_time
- from
- (select
- uid,
- timestamp_ms,
- row_number()over(partition by uid order by timestamp_ms) rank
- from tmp.tmpx) x
- left outer join
- (select
- uid,
- timestamp_ms,
- row_number()over(partition by uid order by timestamp_ms) rank
- from tmp.tmpx) y
- on x.uid=y.uid and x.rank=y.rank-1
- where x.rank=1 or y.rank is null or y.timestamp_ms-x.timestamp_ms>=300)
首先我们用开窗函数错位相减,用where条件筛选出我们需要的列,其中
x.rank=1 抽取出第一行
y.rank is null 抽取最后一样
y.timestamp_ms-x.timestamp_ms>=300抽取满足条件的行,如下:

当然这个结果并不是我们要的结果,需要将上述表格中某一行数据的end-time和下一条数据的start-time结合起来起来,构造出时间段
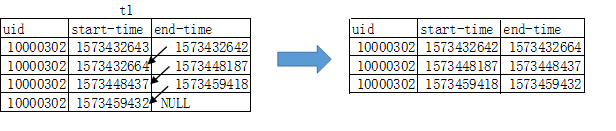
好的,按照上面我们所说的那么下面我们不用关心底层的逻辑,将注意力专注于这张中间表t1
- select
- a.uid,end_time as start_time,start_time as end_time
- from
- (select uid,start_time,row_number()over(partition by uid order by start_time) as rank from t1) a
- join
- (select uid,end_time,row_number()over(partition by uid order by end_time) as rank from t1)b
- on
- a.uid=b.uid and a.rank=b.rank+1
同样,排序后错位相减,然后就可以打完收工了~
UDF实现方式
首先我们假设上述数据存储在csv中,
用python 处理本地文件data.csv,按照python的处理方式写代码(这里就不一句句解释了,会python的同学可以跳过,不会的同学不妨自己动手写一下)
- def life_cut(files):
- f=open(files)
- act_list=[]
- act_dict={}
- for line in f:
- line_list=line.strip().split()
- key=tuple(line_list[0:1])
- if key not in act_dict:
- act_dict.setdefault(key,[])
- act_dict[key].append(line_list[1])
- else:
- act_dict[key].append(line_list[1])
- for k,v in act_dict.items():
- k_str=k[0]+"\t"
- start_time = v[0]
- last_time=v[0]
- i=1
- while i<len(v)-1:
- if int(v[i])-int(last_time)>=300:
- print(k_str+"\t"+start_time+"\t"+v[i-1])
- start_time=v[i]
- last_time = v[i]
- i=i+1
- else:
- last_time = v[i]
- i=i+1
- print(k_str+"\t"+start_time+"\t"+v[len(v)-1])
- # print(k_str + "\t" + start_time + "\t" + v[i])
- if __name__=="__main__":
- life_cut("data.csv")
得到结果如下:
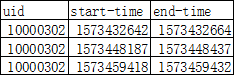
那么下面我们将上述函数写成udf的形式:
- #!/usr/bin/env python
- # -*- encoding:utf-8 -*-
- import sys
- act_list=[]
- act_dict={}
- for line in sys.stdin:
- line_list=line.strip().split("\t")
- key=tuple(line_list[0:1])
- if key not in act_dict:
- act_dict.setdefault(key,[])
- act_dict[key].append(line_list[1])
- else:
- act_dict[key].append(line_list[1])
- for k,v in act_dict.items():
- k_str=k[0]+"\t"
- start_time = v[0]
- last_time=v[0]
- i=1
- while i<len(v)-1:
- if int(v[i])-int(last_time)>=300:
- print(k_str+"\t"+start_time+"\t"+v[i-1])
- start_time=v[i]
- last_time = v[i]
- i=i+1
- else:
- last_time = v[i]
- i=i+1
- print(k_str+"\t"+start_time+"\t"+v[len(v)-1])
这个变化过程的关键点是将 for line in f 替换成 for line in sys.stdin,其他基本上没什么变化
然后我们再来引用这个函数
先add这个函数的路径add file /xxx/life_cut.py 加载udf路径,然后再使用
- select
- TRANSFORM (uid,timestamp_ms) USING "python life_cut.py" as (uid,start_time,end_time)
- from tmp.tmpx
总结
从上述案例我们可以看出,
UDF和SQL的区别在于,在处理复杂逻辑时候,UDF相比SQL能更高效地组织起来逻辑并落地实现功能。UDF和普通脚本的关键区别所在在于将 for line in f 替换成 for line in sys.stdin,常规函数一般是将文件一行行读入,UDF是从标准输入一行行加载数据。希望大家平时没事的时候好好练练python,切莫书到用时方恨少。

















