本文转载自公众号“读芯术”(ID:AI_Discovery)
了解聊天机器人的主要用途很重要,每个行业都不能使用同一个聊天机器人,他们有不同的目的和不同的语料库。虽然消息传递组件可以很好地给予答复,但是可能需要时间作出回应。另一方面,考虑到时间问题,可以应用各种其他方法,甚至可以找到一些以规则为基础的系统,以获得适合回答所提问题的语句。
你曾多少次联系旅行社要求退票,得到一个恰当的答复是远远不够的。
现在让我们制作一个简单的聊天机器人,安装以下软件包:
- pip install nltk
- pip install newspaper3k
Package newspaper3k有以下优点:
- 多线程文章下载框架
- 可识别新闻URL
- 可从HTML中提取文本
- 从HTML中提取顶层图像
- 可从HTML提取所有图像
- 可从文本中提取关键词
- 可从文本中提取摘要
- 可从文本中提取作者
- 谷歌趋势术语提取
- 使用10多种语言(英语、德语、阿拉伯语、中文等)
导入库,如下所示:
- #import libraries
- from newspaper import Article
- import random
- import nltk
- import string
- from sklearn.feature_extraction.text import CountVectorizer
- from sklearn.metrics.pairwise import cosine_similarity
余弦相似度或余弦核将相似度计算为X和Y的标准化点积:
- sklearn.metrics.pairwise.cosine_similarity(X, Y=None, dense_output=True)
参数
X{ndarray, sparse matrix} of shape (n_samples_X, n_features) 输入数据。
Y{ndarray,sparse matrix} of shape (n_samples_Y, n_features), default=None 输入数据。
如果没有,输出将是X. dense_outputbool中所有样本之间的成对相似性,default =True是否返回密集输出,即使输入是稀疏的。如果为False,则如果两个输入数组都是稀疏的,则输出是稀疏的。
返回
核矩阵:ndarray of shape(n_samples_X, n_samples_Y)
- import numpy as np
- import warnings
- warnings.filterwarnings('ignore')
这里从一个医疗保健网站获取数据:
- article=Article("https://www.mayoclinic.org/diseases-conditions/chronic-kidney-disease/symptoms-causes/syc-20354521")
- article.download()
- article.parse()
- article.nlp()
- corpus=article.text
- print(corpus)
- #tokenization
- text=corpus
- sentence_list=nltk.sent_tokenize(text) #A list of sentences
- #Print the list of sentences
- print(sentence_list)
准备好了语料库之后,你需要考虑用户或客户可能会问或说的问题,这与我们的内容无关。它可以是问候语、感谢语,也可以是拜拜之类的信息。团队需要就这些信息和他们的反应进行考量。
问候机器人响应:
- #Random response to greeting
- def greeting_response(text):
- text=text.lower()
- #Bots greeting
- bot_greetings=["howdy","hi","hola","hey","hello"]
- #User Greetings
- user_greetings=["wassup","howdy","hi","hola","hey","hello"]
- for word in text.split():
- if word in user_greetings:
- return random.choice(bot_greetings)
- #Random response to greeting
- def gratitude_response(text):
- text=text.lower()
感谢机器人响应:
- #Bots gratitude
- bot_gratitude=["Glad tohelp","You are most welcome", "Pleasure to be ofhelp"]
- #User Gratitude
- user_gratitude=["Thankyou somuch","grateful","Thankyou","thankyou","thankyou"]
- for word in text.split():
- if word in user_gratitude:
- return random.choice(bot_gratitude)
种类列表:
- # Default title text
- def index_sort(list_var):
- length=len(list_var)
- list_index=list(range(0,length))
- x=list_var
- for i in range(length):
- for j in range(length):
- if x[list_index[i]]>x[list_index[j]]:
- #swap
- temp=list_index[i]
- list_index[i]=list_index[j]
- list_index[j]=temp
- return list_index
聊天机器人响应功能来自于对预定义文本的余弦相似性的响应。
- #Creat Bots Response
- def bot_response(user_input):
- user_input=user_input.lower()
- sentence_list.append(user_input)
- bot_response=""
- cm=CountVectorizer().fit_transform(sentence_list)
- similarity_scores=cosine_similarity(cm[-1],cm)
- similarity_scores_list=similarity_scores.flatten()
- index=index_sort(similarity_scores_list)
- index=index[1:]
- response_flag=0
- j=0
- for i in range(len(index)):
- ifsimilarity_scores_list[index[i]]>0.0:
- bot_response=bot_response+''+sentence_list[index[i]]
- response_flag=1
- j=j+1
- if j>2:
- break
- if response_flag==0:
- bot_response=bot_response+""+"I apologize, I dont understand"
- sentence_list.remove(user_input)
- return bot_response
对于退出聊天,退出列表中的单词写为“退出”,“再见”,“再见”,“退出”。
响应这些话,聊天机器人将退出聊天。
启动聊天机器人,尽情享受吧!
- #Start Chat
- print("Doc Bot: I am DOc bot and I will answer your queries about chronickidney disease, if you want to exit type, bye")
- exit_list=['exit','bye','see you later','quit']
- while(True):
- user_input=input()
- if user_input.lower() in exit_list:
- print("Doc Bot: Bye Bye See youlater")
- break
- elif greeting_response(user_input)!=None:
- print("Doc Bot: "+greeting_response(user_input))
- elif gratitude_response(user_input)!=None:
- print("Doc Bot: "+gratitude_response(user_input))
- else:
- print("Doc Bot: "+bot_response(user_input))
请参见下面聊天机器人的回复:
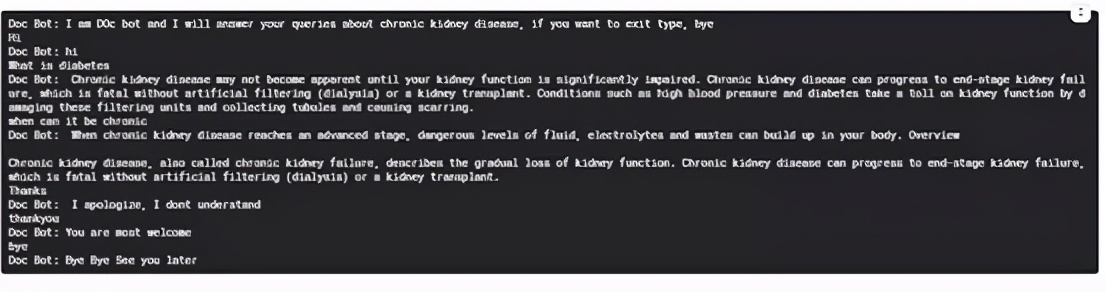
“谢谢”并不在我们的机器人感谢程序中,因此我们要传达这样的信息。随着时间的推移,你可以扩大这样的词汇表,或者使用正则表达式对其进行微调。
举个小例子,与聊天机器人开始聊天,应该是快速和简单的。你需要针对不同行业对聊天机器人进行微调,这些行业的语料库来自实时数据或云端的一些储存。
此外,需要注意的是,实时数据要面对挑战,聊天必须基于最新的数据作出回应,例如在旅行社订票。