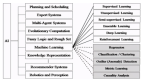
1 人工智能和机器学习
在正文开始之前,先请大家看一张人工智能、机器学习、深度学习关系图,如下图1.1所示
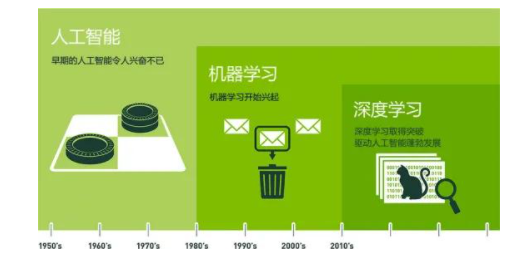
图1.1 人工智能、机器学习、深度学习关系图
现在我们带着一个问题——“你心目中的人工智能是什么样的?”,我们往下看可能枯燥的文字就会变得有趣了。
人工智能之父——“艾伦·麦席森·图灵”提出了一种用于判定机器是否具有智能的试验方法,即图灵试验。此原则说:如果一个人使用任意一串问题去询问两个他不能看见的对象:一个是正常思维的人;一个是机器,如果经过若干询问以后他不能得出实质的区别,则他就可以认为该机器业也具备了人的“智能”。
人工智能最早的应用——在二战期间,图灵曾协助英国军方破译德国著名的密码系统Enigma,为扭转二战盟军的大西洋战场战局立下汗马功劳。将英国战时情报中心每月破译的情报数量从39000条提升到84000条,让二战至少提前结束了几年。感兴趣的小伙伴可以观看相关的电影“模仿游戏”。这里就不再提及。
机器学习:机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能核心,是使计算机具有智能的根本途径。
机器学习本质上就是借鉴了我们人类的学习方法,例如:人的绝大部分智能是通过后天训练和学习得到的,并不是天生就具备的,新生儿刚出生的时候没有认知能力,在成长的过程中不断得到信息,对大脑形成刺激,从而建立认知能力。给孩子建立“苹果”、“橙子”的抽象概念,我们就需要不断地带他认识很多“苹果”、“橙子”的实例和图片,建立起他对“苹果”、“橙子”的认知。
图1.2 认知识物卡
机器学习中的经典算法发展史
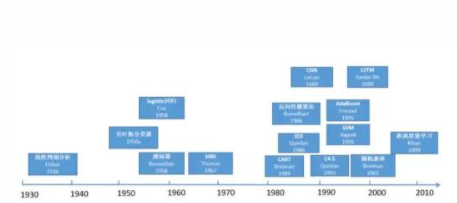
图1.3 机器学习经典算法
在这里就只拿被称为机器学习天花板的SVM经典算法来阐明一下机器学习的实现原理吧!
还是老样子,我们带着实际问题来了解SVM这样会更加的清晰。比如给你一堆“猫”和“狗”的图片,让你将“猫”和“狗”分别识别出来,你会怎么做呢?
图1.4 猫狗图片
像这些图片,我们由于早早的建立起了对“猫”和“狗”的认知,所以我们就能很轻松的分类出来,但是我们没多少人愿意做这种枯燥无趣的工作,我们有机器,何不训练机器来帮助我们完成这种简单无趣的工作呢?
2 数字图像和模拟图像
在给大家揭开机器学习和深度学习的神秘面纱之前,先介绍一下图像处理中的最重要的一项——“图像”。图像现在大致可分为“模拟图像”与“数字图像”。
模拟图像:又称连续图像,是指在二维坐标系中连续变化的图像,即图像的像点是无限稠密的,同时具有灰度值(即图像从暗到亮的变化值)。连续图像的典型代表是由光学透镜系统获取的图像,如人物照片和景物照片等,有时又称模拟图像。用胶卷拍出的相片是模拟图像,根据胶卷洗一寸的照片与洗二寸的照片,不影响视觉效果。但模拟图像包含的信息量巨大,而我们通常需要使用计算机对图像进行处理,所以需要由有限行和有限列组成数字图像。如图2.1所示:
图2.5 猫狗分类点集
其中红色的点我们可以认为是“猫”,蓝色的点我们认为是“狗”。我们通过上述的特征可以明显的看出这红点和蓝点之间存在间隔!而我们让机器能够找出一个线将红点和蓝点分离开来就可以让机器来帮助我们识别图片到底是猫还是狗啦!(具体算法不过多介绍,感兴趣的可以百度SVM)分类效果如下图所示:
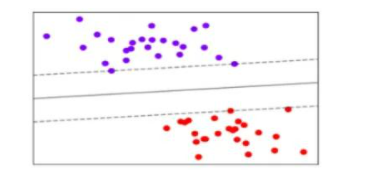
图2.6 SVM二分类线
我们可以看到图中有一条实线,新的图片经过计算后结果在实线上方的我们就认为它是蓝色的点为“狗”,反之则是红色的点也就是“猫”,这是一个简单的二分类,以此类推,我们可以实现多分类!如图所示:
图2.7 SVM三分类线
由这个“猫”和“狗”的分类我们基本可以得到机器学习解决问题的流程:
3 深度学习
如同机器学习是在人工智能的基础发展来的一个分支,深度学习则是在机器学习的基础上发展来的一个分支。
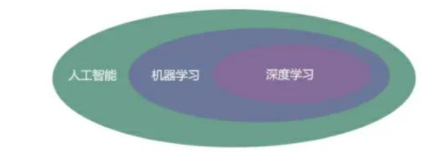
图3.1 深度学习比例图
深度学习也被称为人工神经网络,它是建立在我们对于自身认知水平上的产物,就拿下图生物研究成果来说,我们通过眼睛来收集信息,通过神经元网络来传递给大脑,最后得出我们观察到的结果。
图3.2 人体神经网络结构图
深度学习也正如同于此,我们还是举个简单的实例来分析一波深度学习的工作方式。现在给我们的问题是一个简单的手写数字识别0-9这10个数字。让我们能够正确的识别这10个数字。过程其实比较简单:
我们首先将手写数字图片收集起来,将相对应的数字图片进行相对应的标签。
将图片和标签都告诉计算机,让其在构建好的卷积网络中训练学习。
对学习好的模型进行验证极其应用。
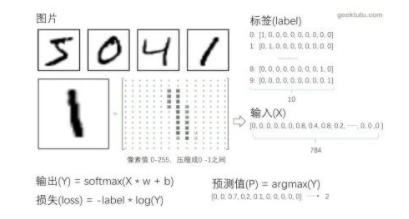
图3.3 图片标注训练图
为什么说深度学习为人工神经网络。接下来我们可以看看这幅图片。
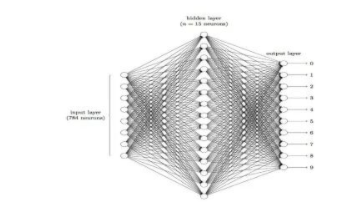
图3.4 手写数字神经网络图
Input layer输入层可以看成输入的图片,空心圆圈我们暂且理解为像素好了,这些像素经过中间hidden layer隐藏层(可以看成神经元的传输)的运算,最后输出到output layer输出层为10个数,这10个数经过运算以后范围一般为0-1之间,从上到下可以看成为0-9这是个数字的概率值。例如:我们把一张数字9的图片放入训练好的模型中,最后到output layer的时候这十个数的数组为[0.12,0.32,0.33,0.10,0.01,0.01,0.01,0.01,0.15,0.99]
分别表示这计算机认为这张图片是0的概率是0.12……9的概率为0.99。那么我们计算机会挑选概率最大的0.99对应的标签来认为这张图片就是9。这些hidden layer的隐藏层如同我们的神经网,起到自动提取特征运算的作用,并且从而对比传统机器学习算法具有更高的准确率。
那么深度学习就一定比传统机器学习好吗?其实不然,他们都各有优劣。
深度学习优点:
1、精准度高(超出传统机器学习一截),适用性广。
2、端到端,保密性强(hidden layer隐藏层就相当于一个小黑盒,不到最后的输出结果你不知道目前到了哪一步)。
3、不需要手动提取特征。
……
深度学习缺点:
1、计算量大、硬件要求高(网络层数越多计算量越大)。
2、训练时间久,通用性不强(训练的它能识别,不训练的它可能不知道)。
3、不成熟(全世界的专家都在研究hidden layer隐藏层,我们人类竟然能造出不知道具体原理的东西,只知道它能这样实现功能)。
……
机器学习优点:
1、通用性强。
2、硬件要求低。
3、运算时间短。
4、比较成熟。
……
机器学习缺点:
1、过分依赖于二值化。
……
到了这里想必大家对人工智能、机器学习和深度学习有了一定的了解,回到最初的问题“你心目中的人工智能是什么样的呢?”,可能现在的技术和你想的略有差距。但未来一定有像电影里的那种人工智能机器人(好了,偏离主题了)