本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
近日,麻省理工学院检查了10个最常引用的AI数据集。他们发现其中存在大约3.4%的数据不正确或标签错误,这可能会导致使用这些数据集的AI系统出现问题。
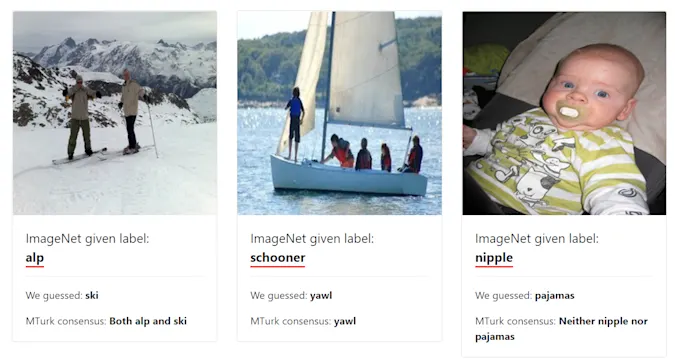
这些数据集被引用次数均超过10万次,其中包括来自新闻的文本数据集, 亚马逊和IMDb评论。上图就是几个明显标签错误的例子。
为了发现可能的错误,研究人员使用了Confident Learning,检查数据集的标签噪声。
研究人员发现QuickDraw数据集错误最多,大约有500万,约占数据集的10%。