













据外国媒体报道,互联网科技巨头亚马逊正开始探索 RISC-V,以考虑替代 Arm 处理器的方案,因为后者正在被英伟达收购。
此前,亚马逊已经拥有了自己专属的 AWS 数据中心芯片、人工智能芯片以及各类移动智能设备上的 Arm 芯片。
像亚马逊一样,国内外很多此前只涉及软件和互联网的科技巨头都拥有了自主研发的芯片,并且取得了经市场验证的良好效果。
谷歌的 TPU 和自身的 TensorFlow、算力平台共同组成了全世界最好的人工智能技术生态;亚马逊的 Inferentia 集群比英伟达 T4 降低了 25% 延迟和 30% 成本。
其他互联网巨头也正在加速入场,微软去年12月份表示正在研发Arm芯片;字节跳动近期也开始芯片人才的招聘,探索Arm芯片。字节跳动的相关负责人回应媒体询问时证实,「是在组建相关团队,在AI芯片领域做一些探索。」

字节跳动官网上芯片工程师的招聘信息。
在外界看来,互联网巨头自研芯片已经成为必然,这势必会对原本以芯片为主业的半导体巨头和芯片创业公司产生较大影响。
在这个过程中,需要搞明白一个最核心的问题——互联网巨头为什么要自己造芯片,以及在何种情况下才会选择自研芯片。
业务边界的持续扩展,数据量的激增,人工智能技术的发展,让互联网巨头对芯片的需求持续增加。
同时,外部的芯片设计工具和 IP 服务也逐渐变强,芯片产业链的完善为巨头自主做芯片提供了成熟的产业基础。博通每年都会给客户提供大量定制芯片;苹果引人关注的 M1 背后,其实也有很多其他公司的身影。这种产业链协同和合作帮助互联网巨头降低了研发芯片的门槛。
对计算需求的增加和制造门槛的降低只是提供了一个必要背景,在应用层面上,同一个任务会有无数种硬件解决方案,互联网巨头们的工作就是选择哪种硬件方案以及是否需要自己做,自研芯片只是众多选择中的一项。他们真正关心的是最具性价比的解决计算任务,而非必须要有自己的芯片。
而决策的唯一依据就是不同方案的成本与收益对比,也就是找到 ROI 最大的方案。
自主研发芯片有着非常高的整体研发成本,包括购买 IP、人员成本、实验和流片等。互联网巨头们大部分的成功经验都集中在软件和互联网领域,他们进入芯片领域也是从零开始,没有太多可以节省的成本。
湾区一位芯片专家介绍说,谷歌开始做芯片时,从博通挖了很多 ASCI 业务的人,从上到下组建一个全新领域的专业团队和运营体系,而这种体系与公司此前所擅长的是完全不同的,这又带来在企业文化和管理上的额外成本和风险。
自主研发芯片的高投入决定了它只适用于可以带来更高收益的应用场景——芯片能和公司自身业务系统、网络结构和训练框架等紧密结合,实现计算成本的显著下降,产品性能和和用户体验的显著增长。
只有这样,自研芯片才能获得最高的 ROI,企业选择自研方案才有意义。下面以 Arm 芯片、训练芯片、Codec 和 Smart NIC 等四种芯片为例。
众所周知,摩尔定律的速度已经开始变缓,数据中心同构体系下基于 x86 的硬件成本没办法继续下降。想要实现计算成本的下降,只能将负载拆分,然后用不同架构和处理器来分别处理,很多负载又是和企业自身网络结构强相关的,那企业就需要针对这些任务去定制芯片,在这种情况下,企业自主研发 Arm 芯片就是有助于节省成本的。
除了与网络结构强相关,与训练框架强相关也会促使公司自主研发芯片。比如有 TensorFlow 的谷歌就一定要去做 TPU,因为谷歌是通过公有云为用户提供算力租赁和模型训练服务,而一个模型在其平台训练完成所需要的时间和费用是用户决定是否使用该平台的最主要因素。谷歌 TPU 与 TensorFlow、云计算的强协同,会带来远超通用训练工具的效果,以及更低的成本。
在去年的 MLPerf 基准测试结果中,谷歌的 TPU 集群打破了 8 项测试纪录中的 6 项。在 4096 块 TPU 的加持下,谷歌的超级计算机可以在 33 秒内训练 ResNet-50、BERT、Transformer、SSD 等模型。在使用 TensorFlow 框架时,BERT 的训练时间缩短到 23 秒。
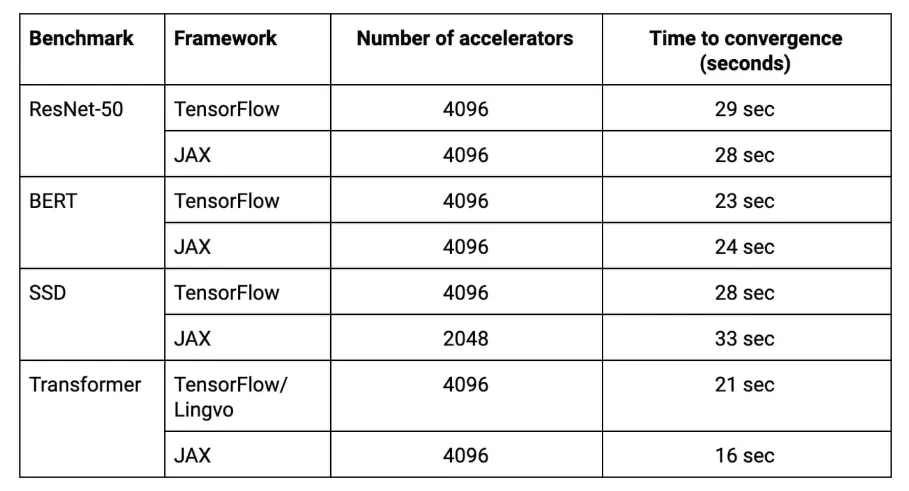
在一个图像分类任务中,用 ImageNet 数据集训练 ResNet-50 v1.5 达到 75.90% 的准确率,256 个第四代 TPUs 可以在 1.82 分钟内完成,这几乎相当于 768 个英伟达 A100 显卡和 192 个 AMD Epyc 7742 CPU 内核(1.06 分钟)的速度。
单从芯片架构上来说,TPU 和 GPU 不会产生如此大差异。谷歌 TPU 集群比 A100 快这么多的原因是,用于训练的芯片与公司自身的网络结构和训练框架强相关,TPU 不仅支持自身的网络结构,还向上支持自己的训练框架,谷歌知道 TensorFlow 如何去做加速,所以效果肯定会优于通用的 GPU。那最后带来的结果就是,用户在谷歌的平台上获得了更高性价比的服务,谷歌更好的建立人工智能技术生态。所以,谷歌自主研发 TPU 就是有意义的。
华为也是此类情况,他们拥有升腾 910、MindSpore 和云计算,因此,华为的人工智能技术平台就拥有了竞争力。徐直军曾表示,昇腾 910、MindSpore 的推出,标志着华为已完成全栈全场景AI解决方案(Portfolio)的构建,也标志着华为 AI 战略的执行进入了新的阶段。
对于其他类型的定制芯片也是如此,比如 Facebook 做自己的 Codec,这是因为在 Facebook 自身的业务和软件体系下,上行下行的编解码处理非常重要。比起使用通用 CPU ,Facebook 选择自己开发 Codec 就更划算。
还有智能网卡 Smart NIC,几乎所有的互联网巨头都会自主研发,尤其是提供公有云服务的企业。因为公有云涉及庞大的网络结构,企业需要去匹配负载和网卡,所以每家企业对 Smart NIC 的需求都是个性化的,不具有通用性,需要定制化,这也是英伟达的 DPU 在市场中表现并不好的原因。
还有一个重要因素是互联网巨头都具有规模效应,他们拥有最庞大的机房,为数以千万计的用户提供服务,只要性能有微小提升,或者价格有微小下降,就会为用户带来巨大价值。
总结来说,对于互联网巨头,如果芯片的应用场景和自身业务及软件强相关,自身对此有个性化需求,最终能通过规模效应最大化收益,那他们就会选择自主研发。
在其他场景下,当巨头的芯片需求不是个性化的,所需芯片和自身业务、网络拓扑结构和软件体系没有强相关性,或者说他们需要的是通用芯片时,那巨头们就无法通过定制来降低成本,也就没有必要为了一个非定制需求去承担通用芯片的全部研发成本。
更加合理的方式应该是向其他半导体公司购买,或者战略投资芯片创业公司进行布局,以与其他客户或投资机构共同分摊研发成本。x86 CPU 和推理芯片就是属于这个范畴。
很多公司是没办法通过优化自身的拓扑结构和软件体系来实现 x86 CPU 性价比的大幅提升的,所以最佳选择就是直接向英特尔购买。
推理芯片也是如此,它在人工智能领域的通用性很强,需要根据算法来进行调整和演进,需要较好的可编程性,那这类芯片就和巨头自身的网络拓扑结构和训练框架并没有那么直接的关系,大企业也就无法通过深度定制和自主研发大幅降低成本或提升性能,最好的选择也是购买及投资。
亚马逊在自主研发与业务相关芯片的同时,也投资了通用人工智能芯片初创公司 Syntiant。字节跳动一方面探索自主研发 Arm 芯片,另一方面,他们投资的一家芯片公司的主要产品也是云端推理芯片。
Syntiant 的深度学习处理器
互联网巨头不同的芯片策略和行动为他们实现了最大化收益,同时也使得他们在半导体领域的角色开始变得多样。
他们是最大的芯片客户,有着最丰富的计算场景和异常庞大的业务负载,每年为几家大型半导体公司和新兴芯片创业公司带来海量订单;同时,他们已经开始定制芯片或自主研发芯片,在某种程度上成为这些半导体大公司和创业公司的潜在竞争对手,或者给他们带来产品替代风险;最后,他们还是资本巨头,可以借助资本杠杆,通过投资和并购来完善自己的技术生态。
这些让互联网巨头、半导体巨头和芯片创业公司之间的关系微妙且复杂,从而也让市场格局和产业发展趋势也更加不明确。
但如果我们对以上互联网巨头已有策略、行为和结果进行分析,那就很容易发现他们自己在市场中的定位,在一定程度上就可以避免和他们直接竞争,同时还可以围绕着他们的需求发现更多机会。
比如,根据谷歌的行动,我们就可以判断训练芯片可能就更加适合已经有成熟训练框架和算力的巨头去做,谷歌已经证明了,通过芯片、训练框架和算力的强绑定可以获得比 GPU 更好的效果。
如果创业公司只做一个训练芯片,没有自己的训练框架,也无法与不同客户的网络拓扑结构和软件系统产生强耦合关系,那是很难与英伟达去竞争的,同时也面临谷歌的竞争。
而以推理芯片为代表的人工智能通用芯片就会存在更大机会,它是独立的,考虑的是可编程性和灵活性,与客户的网络及软件没有强相关性。
互联网巨头对此没有定制化开发的需求,反而因为自身的需求及成本收益的考虑,会更倾向于战略投资这个方向的创业公司,或直接购买这类芯片。
同时,一个领域专用的推理芯片也是可以在性价比方面超过 GPU 的。GPU 的应用领域较广,包括 Graph、人工智能和高性能计算等,人工智能又包含推理和训练。GPU 巨头很难去选一个细分领域,为一个小市场去重新设计一套架构,他们依然是以一个市场领导者的角色去关注最通用、最广泛的市场。
而创业公司完全可以选择一个最细分的方向,比如说云端推理芯片,然后专注于架构和性能提升上,且花费更低的成本,从而在这个细分市场上取得成功。















