【51CTO.com快译】过去这几年,数据的创建和使用方式出现了一个微妙但明显的趋势。据IDC声称:“全球数据总量将从2018年的33 ZB猛增到2025年的175ZB,年复合增长率高达61%。”这在改变数据处理和分析方面的基本规则。
这个数据趋势在为以前未重视的一系列新的用例(use case)铺平道路,还在改变处理和使用一些现有用例的方式,这反过来需要一种新颖的、更现代的方法来适应这些场景。比如说,可以将来自许多不同数据源的不同数据集(比如图像、文本、语音或视频)实时部分或全部组合起来,以支持可能全面改变我们日常生活和业务方式的用例。
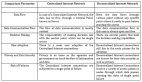
我们今天面临的挑战
由于这方面的步伐很快,我们无法轻松处理。市面上的大多数现有系统和平台主要是为特定类型的数据(创建这些工具时)设计的(理应如此)。然而,正如我们所见,由于当前的最新趋势,数据的形状和大小在发生变化,因此数据创建和使用方面的基本前提不再适用。因此,现有基础架构的要求与支持存在不匹配的情况就可以理解了。
我们需要一种专门为这个趋势而开发的新方法,以适应和迎合事关大多数公司存活的一系列新用例。集成不同异构工具以创建一种同构解决方案框架所采用的通常方法根本行不通。
融合不同维度
如果您仔细观察一下,会发现不同的问题空间(problem space)正在核心处融合。比如说,为了完成监控常规操作这项简单工作,我们需要实时摄取和处理文本和语音等各种数据(数据流),在本地(边缘或设备内)和云层面都要有预测性(AI)。由于进行这种操作的速度和规模,几乎不可能使用孤立的或“拼凑而成”的平台。这种平台根本无法扩展。
这是我们需要处理的第一个核心问题。
我们还必须融合来自解决方案空间的所有参与维度,以应对我们目前面临的不同挑战的这种大融合,这个问题会变得越来越重大、越难处理。我们必须打破孤岛,创建一个融合的架构空间,然后该架构空间应该线性扩大,以匹配数据的速度和数量。
融合解决方案空间中不同维度的这种做法将提供直接集成和支持不同格式数据的方式。高级抽象将为处理各种数据提供一致的接口。数据流和人工智能的融合可以以一种绝对和预测性的方式持续处理数据。直接集成将使用户可以完全控制系统所获取和处理的每个字节,这将缩短延迟以实现高速精密处理。数据流处理将确保实时地持续聚合、运行统计、事件预测及相关操作。
这种融合优先的方法还将便于实现系统的真正线性扩展。如果是孤立的架构,我们发现针对不同的垂直领域一起扩展总是极其困难,也无法进一步完全利用资源。但是借助融合,我们不需要费心地扩展单个维度,资源利用率很高肯定随之而来。
进一步的孤立(半孤立)架构迫使太多的网络跳数以及太多的数据副本。在这种场景下,即使处理效率很高,这种架构也无法实现低延迟(或高速度)。我们需要尽量减少网络跳数和数据复制。通过融合,我们可以尽量减少网络跳数和数据复制,从而提升性能。
结论
各种数据迅速爆炸以及突然需要实时捕获和分析所有这些数据,迫使我们摆脱特定系统传统的分散综合架构。我们需要采用计算模型的直接融合的可扩展单元,不仅应对当前情形,还可以在未来几年保持创新、市场上立于不败之地。
原文标题:Why A Novel Data Processing Philosophy Is Necessary For An Emerging Data Trend,作者:Sachin Sinha
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】