本文转载自微信公众号「KK架构师」,作者wangkai。转载本文请联系KK架构师公众号。
本文大纲
一、HDFS 是大数据的基石
我们都知道,HDFS 是大数据存储的基石,所有的离线数据都存储在 HDFS 上,而 NameNode 是存储所有元数据的地方(所谓元数据就是描述数据的数据,比如文件的大小,文件都存储在哪些 DataNode 上,文件在目录树的位置等),所以 NameNode 便成为了 HDFS 最关键的部分。
在离线数仓中,会存在很多离线任务,这些离线任务都要往 HDFS 写数据,每次写数据都会经过 NameNode 来保存元数据信息,那么 NameNode 势必会承担非常多的请求。NameNode 作为 HDFS 的核心,肯定自身要保证高可用,数据不能一直在内存中,要写到磁盘里。
所以一个关键的问题来了,NameNode 是用了什么神秘的技术,在保证自身高可用的同时,还能承担巨额的读写请求?
二、NameNode 高可用是如何实现的
下面直接来一个 NameNode 高可用的架构图:
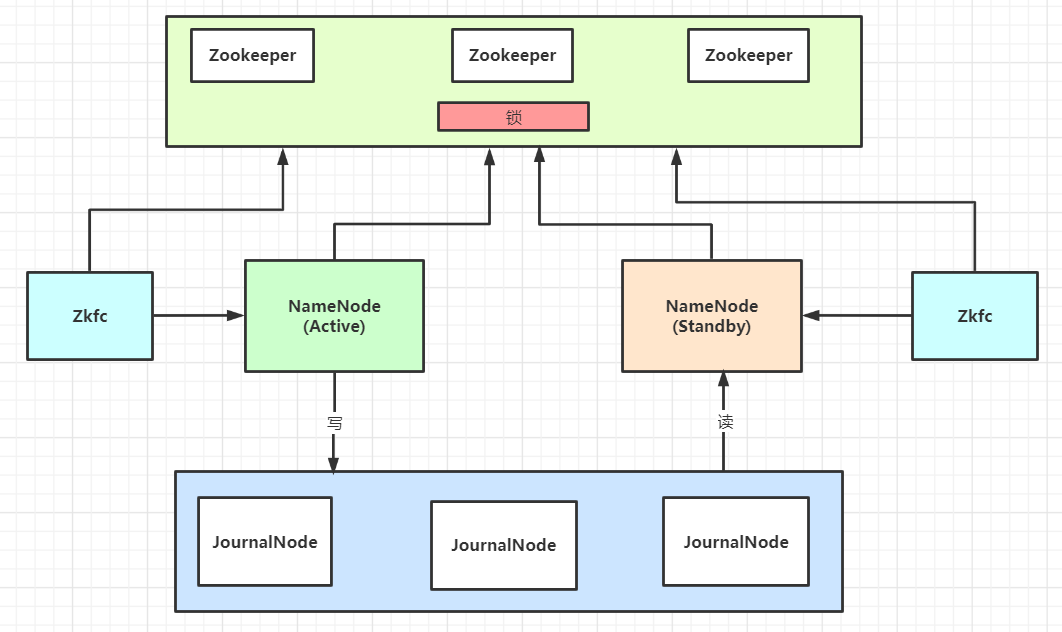
然后解释下如何保证高可用的:
(1)NameNode 只有一个时的单点故障问题
如果我们只部署了一个 NameNode,那么这个 NameNode 是有单点故障的问题的。如何解决,再加一个 NameNode 即可;
(2)当有两个 NameNode ,切换时,数据如何保持同步
两个 NameNode 一起工作,某一个 NameNode 挂掉了,另一个 NameNode 接替工作,这件事成立的必要前提是,两个 NameNode 的数据得时时刻刻保持一致。
那么如何保持数据一致,是不是可以在两个 NameNode 之间搞个共享的文件系统?仔细想想也不行,这样的话,单点故障问题就转移到这个文件系统上了。
(3)使用多节点的 JournalNode 作为主备 NameNode 的数据同步介质
这里引入了 JournalNode 集群,JournalNode 的每个节点的数据都是一样的,并且时刻保持一致。并且只要超过半数的节点存活,整个 JournalNode 集群都可以正常提供服务。
所以,一般会使用奇数个节点来搭建。(为什么一般不用偶数个呢?因为 3 个节点构成的集群,可以容忍挂掉一台机器;而 4 个节点构成的集群,也只能容忍挂掉一台机器。同样是只能挂掉一台,为何不选 3 个节点的呢,还能节省资源)。
使用 JournalNode 集群,一个 NameNode 实时的往集群写,另一个 NameNode 也实时的读集群数据,这样两个 NameNode 数据就可以保持一致了。
(4)一个 NameNode 挂掉,另一个 NameNode 如何立马感知并接替工作
首先不能人工参与切换。那如何实时监听呢?
首先要再引入一个关键组件:Zookeeper。当两个 NameNode 同时启动后,他们都会去 Zookeeper 上注册,谁注册成功了,谁就能获得锁,成为 Active 状态的 NameNode。
另外还需要一个组件:ZKFC,它会实时监控 Zookeeper 进程状态,并且会以心跳的方式实时的告诉 Zookeeper NameNode 的状态。如果一个 NameNode 进程挂了,就会把 Zookeeper 上的锁给另外一个 NameNode,让它成为 Active 的来工作。
三、NameNode 如何既高可用,还能高并发
1、双缓冲技术
NameNode 为了实现高可用,首先自己内存里的数据需要写到磁盘,然后还需要往 JournalNode 里写数据。
所以既然要写磁盘,还是往两个地方写磁盘,那必然性能会跟不上的。
所以这里 NameNode 引入了一个技术,也是本篇文章的重点:双缓冲技术。
双缓冲的设计理念如下图:
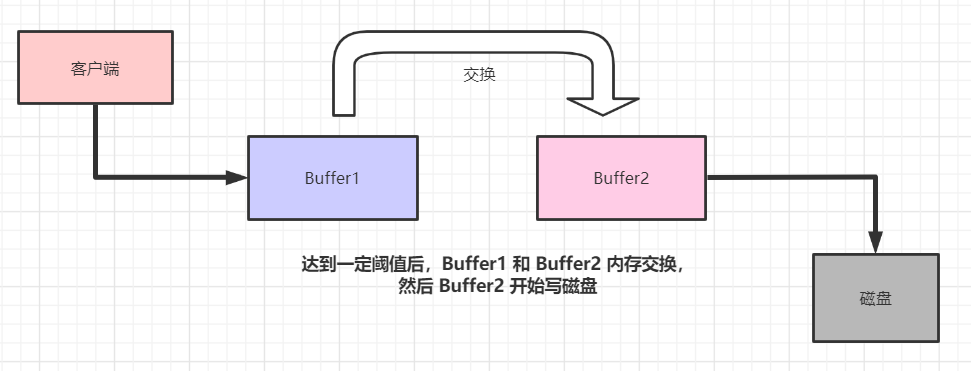
客户端不是直接写磁盘,而是往一个内存结构(Buffer1)里面写数据。当 Buffer1 达到一定阈值后,Buffer 1 和 Buffer 2 交换内存数据。此时 Buffer1 数据为空,Buffer2 开始在后台默默写磁盘。
这样的好处很明显的,前端只需要进行内存写 Buffer1 就行,性能特别高;而 Buffer2 在后台默默的同步日志到磁盘即可。
这样磁盘写,就转化成为了内存写,速度大大提高了。
2、如何实现双缓冲
然而,在真实环境不只一个客户端是这样子的:
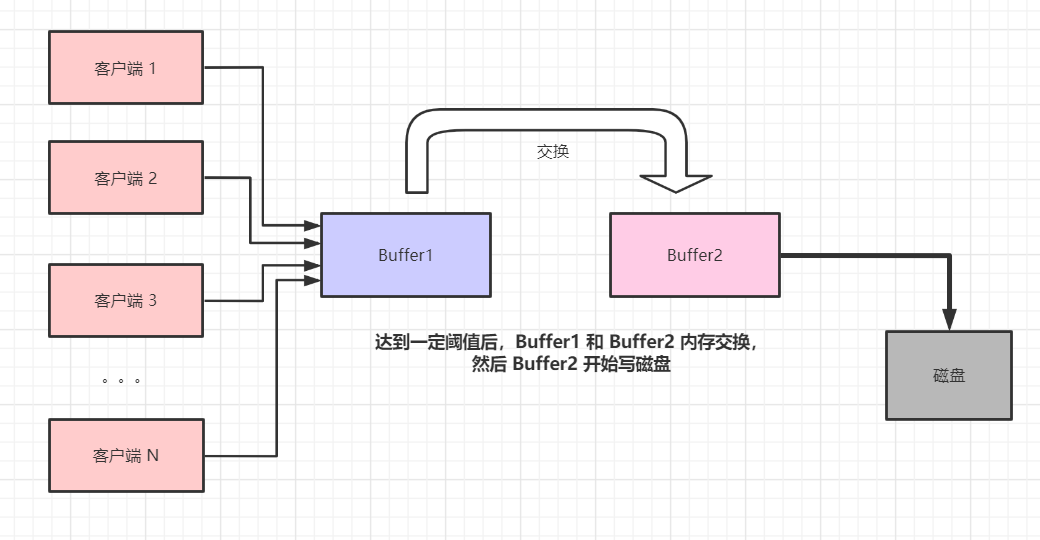
大数据情况下是 N 个客户端同时并发写的,在高并发的情况下,我们必然要去协调多个线程动作的一致性,比如往 Buffer1 的写动作,Buffer1 与 Buffer2 数据交换的动作,Buffer2 写磁盘的动作。
那么我们该如何实现这样一个巧妙的双缓冲呢?下面的代码是我从 Hadoop 源码里抽离出来的关键实现:
- package org.apache.hadoop;
- import java.util.LinkedList;
- public class FSEditLog2 {
- private long txid=0L;
- private DoubleBuffer editLogBuffer=new DoubleBuffer();
- //是否正在刷写磁盘
- private volatile Boolean isSyncRunning = false;
- private volatile Boolean isWaitSync = false;
- private volatile Long syncMaxTxid = 0L;
- //每个线程都对应自己的一个副本
- private ThreadLocal<Long> localTxid=new ThreadLocal<Long>();
- public void logEdit(String content){//mkdir /a
- synchronized (this){//加锁的目的就是为了事务ID的唯一,而且是递增
- txid++;
- localTxid.set(txid);
- EditLog log = new EditLog(txid, content);
- editLogBuffer.write(log);
- }
- logSync();
- }
- private void logSync(){
- synchronized (this){
- if(isSyncRunning){ //是否有人正在把数据同步到磁盘上面
- long txid = localTxid.get();
- if(txid <= syncMaxTxid){
- //直接return,不接着干了?
- return;
- }
- if(isWaitSync){
- return;
- }
- isWaitSync = true;
- while(isSyncRunning){
- try {
- wait(2000);
- }catch (Exception e){
- e.printStackTrace();
- }
- }
- isWaitSync = false;
- }
- editLogBuffer.setReadyToSync();
- if(editLogBuffer.syncBuffer.size() > 0) {
- syncMaxTxid = editLogBuffer.getSyncMaxTxid();
- }
- isSyncRunning = true;
- } //释放锁
- editLogBuffer.flush();
- synchronized (this) {
- isSyncRunning = false;
- notify();
- } //释放锁
- }
- /**
- * 把日志抽象成类
- */
- class EditLog{
- //顺序递增
- long txid;
- //操作内容 mkdir /a
- String content;
- //构造函数
- public EditLog(long txid,String content){
- this.txid = txid;
- this.content = content;
- }
- //为了测试方便
- @Override
- public String toString() {
- return "EditLog{" +
- "txid=" + txid +
- ", content='" + content + '\'' +
- '}';
- }
- }
- /**
- * 双缓存方案
- */
- class DoubleBuffer{
- //内存1
- LinkedList<EditLog> currentBuffer = new LinkedList<EditLog>();
- //内存2
- LinkedList<EditLog> syncBuffer= new LinkedList<EditLog>();
- /**
- * 把数据写到当前内存1
- * @param log
- */
- public void write(EditLog log){
- currentBuffer.add(log);
- }
- /**
- * 交换内存
- */
- public void setReadyToSync(){
- LinkedList<EditLog> tmp= currentBuffer;
- currentBuffer = syncBuffer;
- syncBuffer = tmp;
- }
- /**
- * 获取内存2里面的日志的最大的事务编号
- * @return
- */
- public Long getSyncMaxTxid(){
- return syncBuffer.getLast().txid;
- }
- /**
- * 刷写磁盘
- */
- public void flush(){
- for(EditLog log:syncBuffer){
- //把数据写到磁盘上
- System.out.println("存入磁盘日志信息:"+log);
- }
- //把内存2里面的数据要清空
- syncBuffer.clear();
- }
- }
- }
主要的业务逻辑就是 40 行,但是真的很巧妙。
1、EditLog
我们先看这个 EditLog 内部类,这是对 EditLog 日志的一个封装,就两个属性 txid 和 content,分别是日志的事务id(保证唯一性)和 内容。
2、DoubleBuffer
再看这个 DoubleBuffer 双缓冲类,很简单,就是在内存里面维护了两个有序的 LinkedList,分别是当前写编辑日志的缓冲和同步到磁盘的缓冲,其中的元素就是 EditLog 类。
write 方法就是把一条编辑日志写到当前缓冲里。
setReadyToSync 方法,就是交换两个缓冲,也是最简单的刚学习 Java 就学习过的两个变量交换值的方法。
getSyncMaxTxid 方法,获得正在同步的那个缓冲去里的最大的事务id。
flush 方法,遍历同步的缓冲的每一条编辑日志,写到磁盘,并最终清空缓冲区内容。
3、主类的一些属性说明
(1)全局的事务id
private long txid=0L;
(2)双缓冲结构
private DoubleBuffer editLogBuffer=new DoubleBuffer();
(3)控制变量
private volatile Boolean isSyncRunning = false; // 是否正在同步数据到磁盘
private volatile Boolean isWaitSync = false; // 是否有线程在等待同步数据到磁盘完成
private volatile Long syncMaxTxid = 0L; // 当前同步的最大日志事务id
private ThreadLocallocalTxid=new ThreadLocal(); // 每个线程的线程副本,用来放本线程当前写入的日志事务id
(4)主逻辑 logEdit 方法
这个方法是对外暴露的方法,客户端往双缓冲写数据就是用的这个方法。
假设当前有一个线程1 进到了 logEdit 方法,首先直接把当前类实例加锁,避免别的线程进来,以此来保证编辑日志事务id的唯一自增性。
- // 全局事务递增
- txid++;
- // 往线程本身的变量里设置事务id值
- localTxid.set(txid);
- // 构造 EditLog 变量
- EditLog log = new EditLog(txid, content);
- // 写入当前的 Buffer
- editLogBuffer.write(log);
当它执行完了这些之后,释放锁,开始执行 logSync() 方法。此时由于释放了锁,于是很多线程开始拿到锁,进入了这个方法中。
假设有五个线程进来了分别写了一条日志,于是现在双缓冲是这样子的:
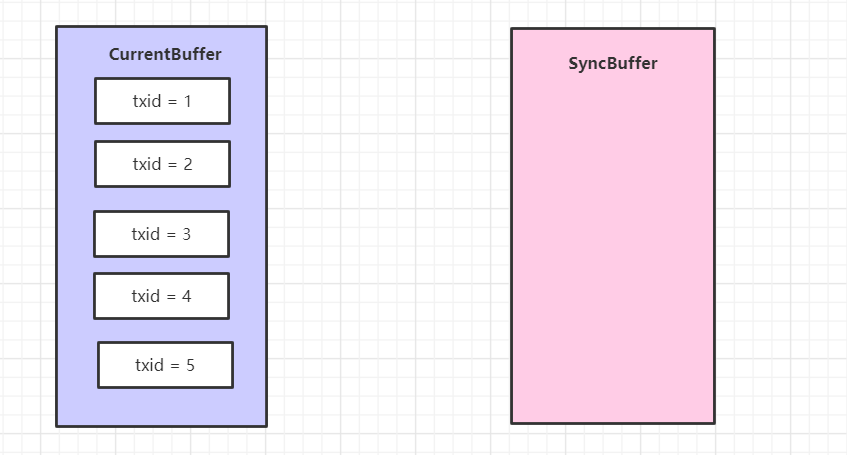
好,然后线程1 开始进入 logSync 方法,第一步就是使用当前类的实例加了锁,保证只有一个线程进来。
检查 isSyncRunning 变量是否为 true,目前是 false,跳过这个方法。
开始执行这个 editLogBuffer.setReadyToSync(); 方法,于是双缓冲的数据直接被交换了。
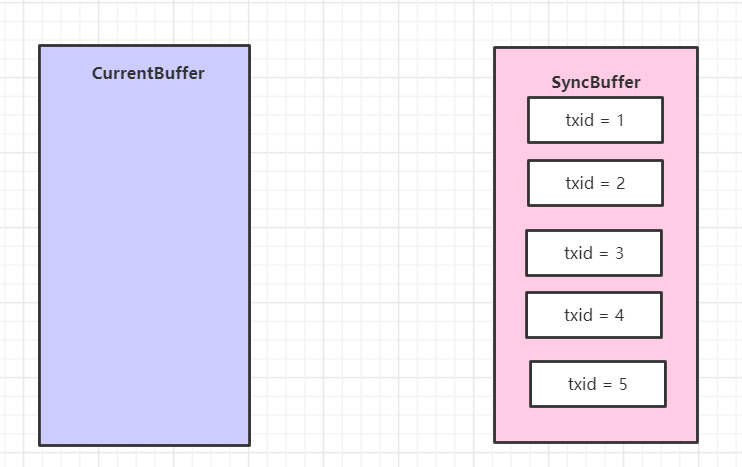
然后获得了全局最大的id,当前是 5,赋值给了 syncMaxTxid 变量
- if(editLogBuffer.syncBuffer.size() > 0) {
- syncMaxTxid = editLogBuffer.getSyncMaxTxid();
- }
然后 isSyncRunning = true; 把这个变量置为 true,表示正在同步数据到磁盘。此时释放锁。
然后 线程 1 开始执行数据同步到磁盘的动作:editLogBuffer.flush() ,这个动作肯定耗费的时间比较久,基本是在 ms 级别。
此时我们假设 线程2 争抢到了锁,进入到了 logSync 方法。
- // 线程2 判断 是否有人正在把数据同步到磁盘上面,这个值被线程 1 改为 true 了
- // 进入到 if 方法
- if(isSyncRunning){
- // 获得到自己线程的事务id,为 2
- long txid = localTxid.get();
- // 2 是否小于 5 ?小于,直接返回,因为此时 5 已经正在被同步到磁盘了
- if(txid <= syncMaxTxid){
- return;
- }
- if(isWaitSync){
- return;
- }
- isWaitSync = true;
- while(isSyncRunning){
- try {
- wait(2000);
- }catch (Exception e){
- e.printStackTrace();
- }
- }
- isWaitSync = false;
- }
线程2 由于自身的编辑日志的事务id 小于当前正在同步的最大的事务id,所以直接返回了,然后线程3 ,线程4,线程5 进来都是这样,直接 return 返回。
假设线程6 此时进来,当前双缓冲状态是这样的
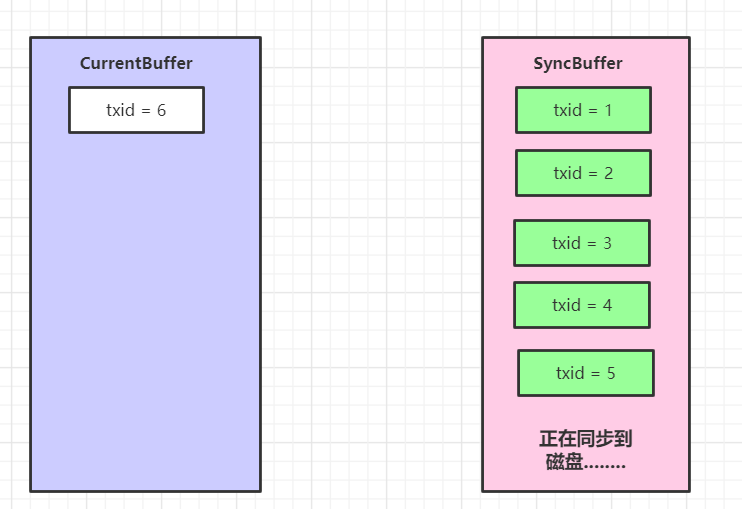
下面线程 6 干的活,参考下面代码里的注释:
- // 线程6 判断是否有人正在把数据同步到磁盘上面,这个值被线程 1 改为 true 了
- // 进入到 if 方法
- if(isSyncRunning){
- // 获得到自己线程的事务id,为 6
- long txid = localTxid.get();
- // 6 是否小于 5 ,不小于继续执行
- if(txid <= syncMaxTxid){
- return;
- }
- // 这个值为 false,继续执行
- if(isWaitSync){
- return;
- }
- // 把 isWaitSync 设置为 true
- isWaitSync = true;
- // 这个值被线程1置为了 true,所以这里在死循环
- while(isSyncRunning){
- try {
- // 等待 2s,wait 会释放锁,同时线程 6 进入睡眠中
- wait(2000);
- }catch (Exception e){
- e.printStackTrace();
- }
- }
- isWaitSync = false;
- }
可以看到 线程 6 在 while 循环里无限等待数据同步到磁盘完毕。然后由于线程 6 把 isWaitSync 值改为了 true,线程 6 在等待期间释放锁,被其他线程抢到之后,其他线程由于 isWaitSync 为true,直接返回了。
当过了一会儿,线程1 把第二个 Buffer 同步到磁盘完毕后,线程1 会执行这些代码
- synchronized (this) {
- isSyncRunning = false;
- notify();
- } //释放锁
把 isSyncRunning 变量置为 false,同时调用 notify(),通知线程 6 ,你可以继续参与锁的竞争了。
然后线程6 ,从 wait 中醒来,重新参与锁竞争,继续执行接下来的代码。此时 isSyncRunning 已经为 false,所以它跳出了 while 循环,把 isWaitSync 置为了 false。
然后它开始执行:交换缓冲区,给最大的事务id(此时为6 )赋值,把 isSyncRunning 赋值为 true。
- editLogBuffer.setReadyToSync();
- if(editLogBuffer.syncBuffer.size() > 0) {
- syncMaxTxid = editLogBuffer.getSyncMaxTxid();
- }
- isSyncRunning = true;
执行完了之后,释放锁,开始执行Buffer2 的同步。然后所有的线程就按照上面的方式有序的工作。
这段几十行的代码很精炼,值得反复推敲,总结下来如下:
(1)写缓冲到内存 和 同步数据到磁盘分开,互不影响和干扰;
(2)使用 synchronize ,wait 和 notify 来保证多线程有序进行工作;
(3)当在同步数据到磁盘中的时候,其他争抢到锁进来准备同步数据的线程只能等待;
(4)线程使用 ThreadLocal 变量,来记录自身当前的事务id,如果小于当前正在同步的最大事务id,则不同步;
(5)有线程在等待同步数据的时候,其他线程写完 editLog 到内存后直接返回;
四、最后的总结
本文详细探讨了 HDFS 在大数据中基石的地位,以及如何保障 NameNode 高可用的运行。
NameNode 在高可用运行时,同时是如何保证高并发读写操作的。双缓冲在其中起到了核心的作用,把写数据和同步数据到磁盘分离开,互不影响。
同时我们还剥离了一段核心双缓冲的实现代码,仔细分析了实现原理。这短短的几十行代码,可谓综合利用了多线程高并发的知识,耐人寻味。