1 热点key产生原因
1.1 消费的数据>>>生产的数据
- 比如电商秒杀活动、明星头条微博
- 大量发布、浏览的热点新闻、热点评论等读多写少场景
1.2 分片的请求量突破单点性能极限
在服务端读数据进行访问时,往往会对数据进行分片,此过程中会在某一主机 Server 上对相应的 Key 进行访问,当访问超过 Server 极限时,就会导致热点 Key 问题。
2 热点Key的危害
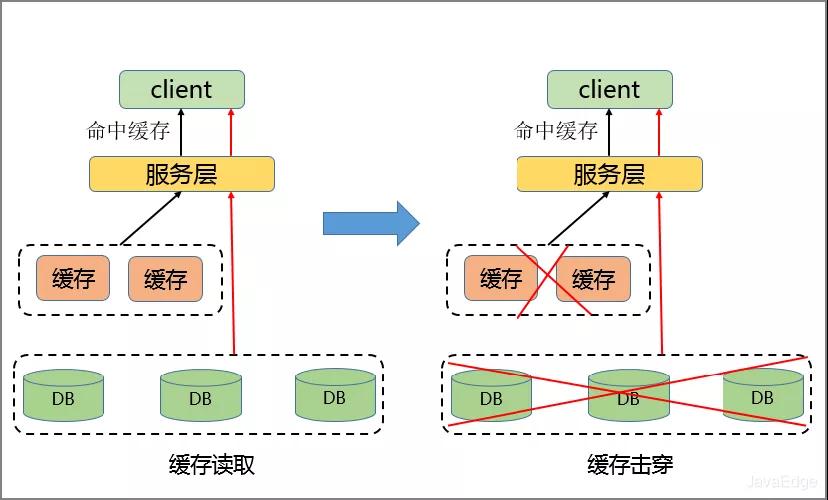
- 流量过于集中,突破物理网卡的极限
- 请求过多,缓存分片服务被打垮
- 缓存击穿
热点Key请求某一主机,超过该主机网卡上限时,导致服务器中的其它服务无法正常进行
=》
热点过于集中,热点Key缓存过多,超过目前缓存容量,导致缓存分片服务被打垮
=》
缓存服务崩溃,此时再有请求产生,会缓存到后台DB,导致缓存击穿,进一步还会导致缓存雪崩。
3 解决方案
3.1 服务端缓存
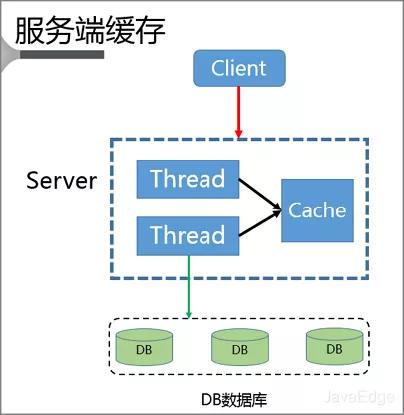
Client会将请求发送到Server,而Server是多线程服务,本地就具有一个基于Cache LRU策略的缓存空间。当Server本身拥堵时,Server不会将请求进一步发送给DB而是直接返回,只有当Server本身畅通时才会将Client请求发送至DB,并且将该数据重新写入缓存。此时就完成了缓存的访问跟重建。
缺陷
- 缓存失效,多线程构建缓存问题
- 缓存丢失,缓存构建问题
- 脏读
3.2 使用Memcache、Redis
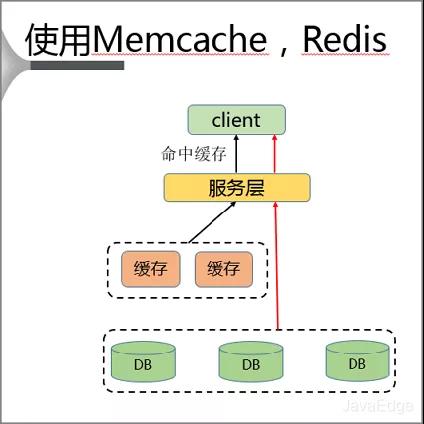
在客户端单独部署缓存。使用过程中Client首先访问服务层,再对同一主机上的缓存层进行访问。该种解决方案具有就近访问、速度快、没有带宽限制的优点。
缺陷
- 内存资源浪费
- 脏读
3.3 本地缓存
缺陷
- 需要提前获知热点
- 缓存容量有限
- 不一致性时间增长
- 热点Key遗漏
3.4 随机后缀
使用Redis做缓存,那可以把一个热点Key的缓存查询压力,分散到多个Redis节点。一个非常热点的数据,数据更新不是很频繁,但是查询非常频繁,要保证基本保证100%的缓存命中率,该怎么处理?
核心思想:空间换时间,即同一热点key保留2份:
- 不带后缀
不带的后缀的有TTL
- 带后缀
带后缀的没有TTL
先查询不带后缀的,查询不到,则:
- 后端查询DB更新缓存
- 查询带后缀返回给调用方
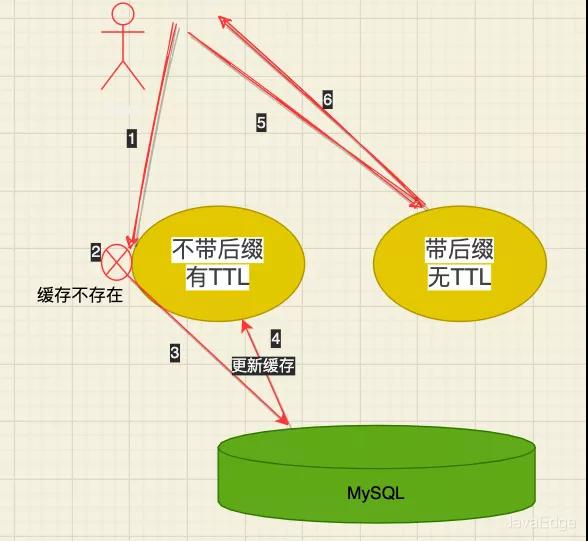
这样即可尽可能避免缓存击穿。
参考
https://www.alibabacloud.com/help/zh/doc-detail/67252.htm
本文转载自微信公众号「JavaEdge」,可以通过以下二维码关注。转载本文请联系JavaEdge公众号。