在进行数据分析与可视化之前,得先处理好数据,而很多时候需要处理的都是文本数据,本文总结了一些文本预处理的方法。
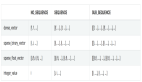
将文本中出现的字母转化为小写
- input_str = """
- There are some people who think love is sex
- And marriage
- And six o'clock-kisses
- And children,
- And perhaps it is,
- Miss Lester.
- But do you know what I think?
- I think love is a touch and yet not a touch
- """
- input_str = input_str.lower()
- print(input_str)
结果如下:

删除或者提取文本中出现的数字
如果文本中的数字与文本分析无关的话,那就删除这些数字。
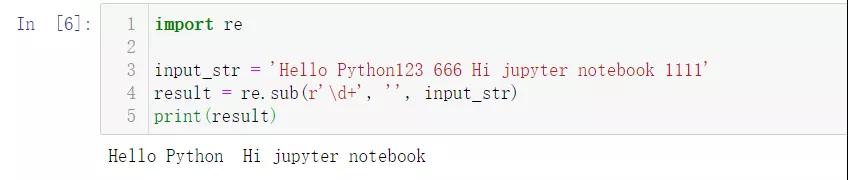
- import re
- input_str = 'Hello Python123 666 Hi jupyter notebook 1111'
- result = re.sub(r'\d+', '', input_str)
- print(result)
结果如下:
而在有些情况下,比如获取的数据中,招聘岗位信息里薪资是 15K 这样的,商品购买信息里商品购买人数是 8500+ 人购买了此商品,这时我们需要从中提取出数字。
- input_str = '薪资:15K 8500+人付款 3.0万+人付款'
- result = re.findall("-?\d+\.?\d*e?-?\d*?", input_str)
- print(result)
结果如下:

滤除文本中标点符号
- import re
- input_str = """This &is [an] example? \叶庭云<< 1""!。。;11???【】>>1 *yetingyun/p:?| {of} string. with.? punctuation!!!!"""
- s = re.sub(r'[^\w\s]', '', input_str)
- print(s)
结果如下:

可以看到文本中乱七八糟的符号都被滤除了,用正则表达式过滤文本中的标点符号,如果空白符也需要过滤,可以使用 r'[^\w]'。原理很简单:在正则表达式中,\w 匹配字母或数字或下划线或汉字(具体与字符集有关),^\w表示相反匹配。
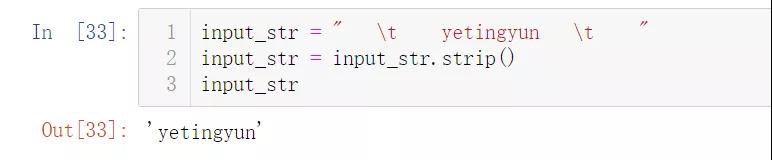
删除两端无用的空格
- input_str = " \t yetingyun \t "
- input_str = input_str.strip()
- input_str
结果如下:
中文分词,滤除停用词和单个词
- # 从Github下载停用词数据 https://github.com/zhousishuo/stopwords
- import jieba
- import re
- # 读取用于测试的文本数据 用户评论
- with open('comments.txt') as f:
- data = f.read()
- # 文本预处理 去除一些无用的字符 只提取出中文出来
- new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
- new_data = "/".join(new_data)
- # 文本分词 精确模式
- seg_list_exact = jieba.cut(new_data, cut_all=False)
- # 加载停用词数据
- with open('stop_words.txt', encoding='utf-8') as f:
- # 获取每一行的停用词 添加进集合
- con = f.read().split('\n')
- stop_words = set()
- for i in con:
- stop_words.add(i)
- # 列表解析式 去除停用词和单个词
- result_list = [word for word in seg_list_exact if word not in stop_words and len(word) > 1]
- result_list
结果如下:
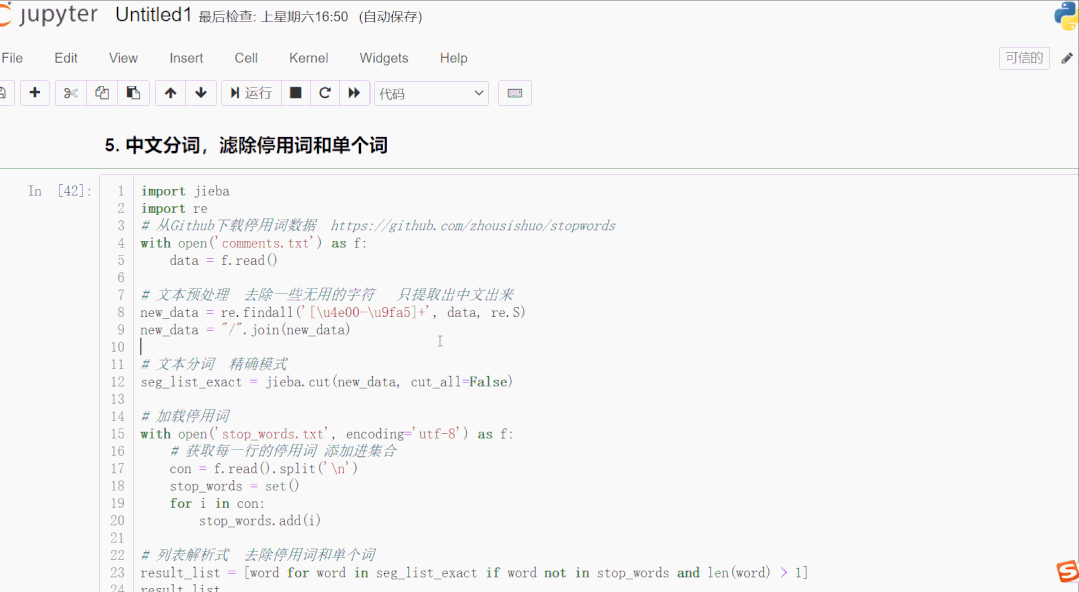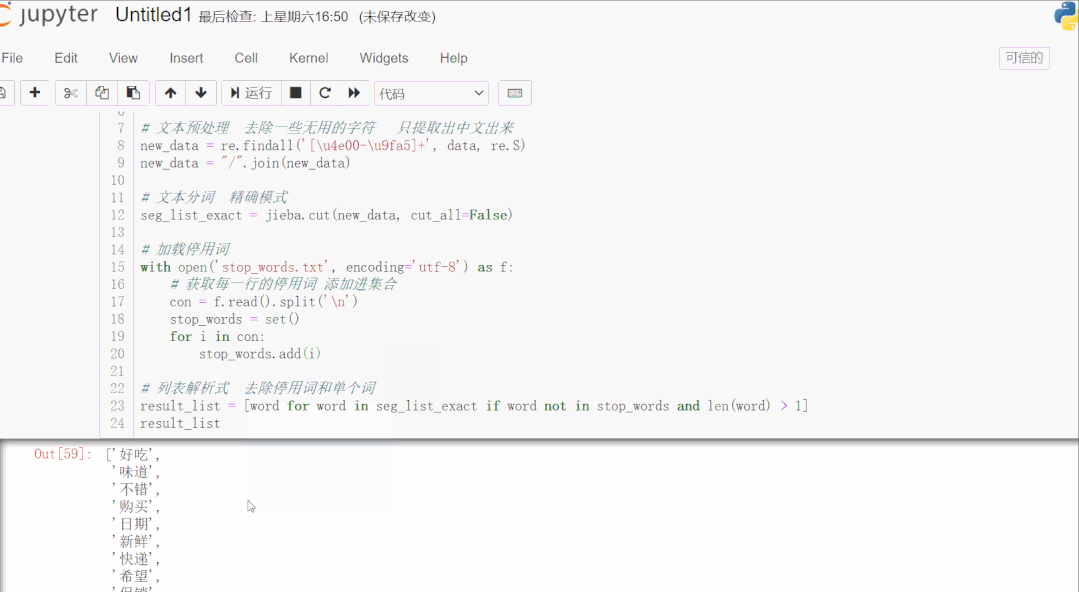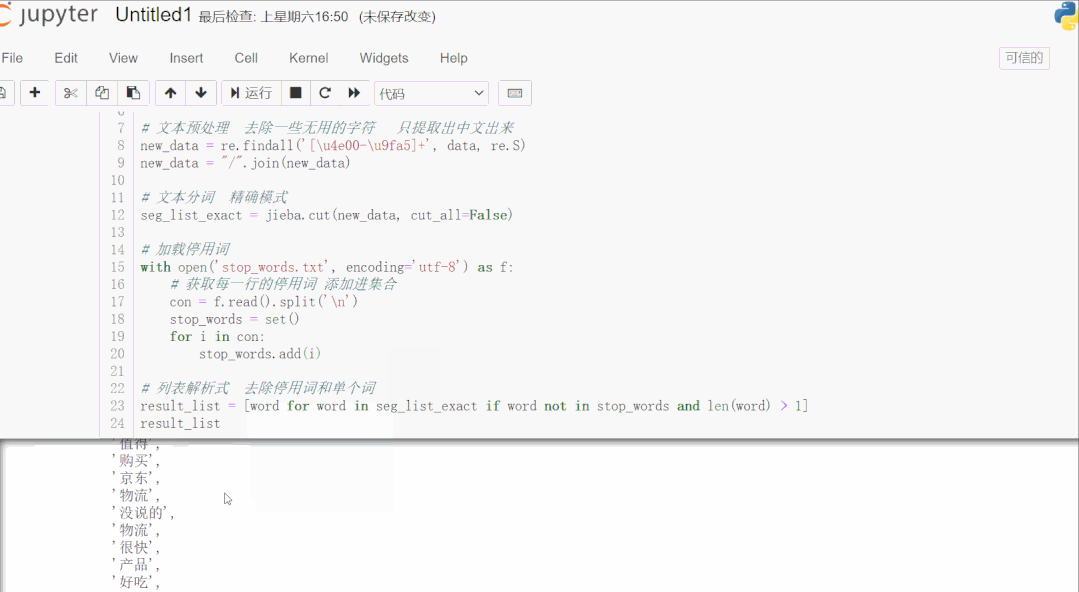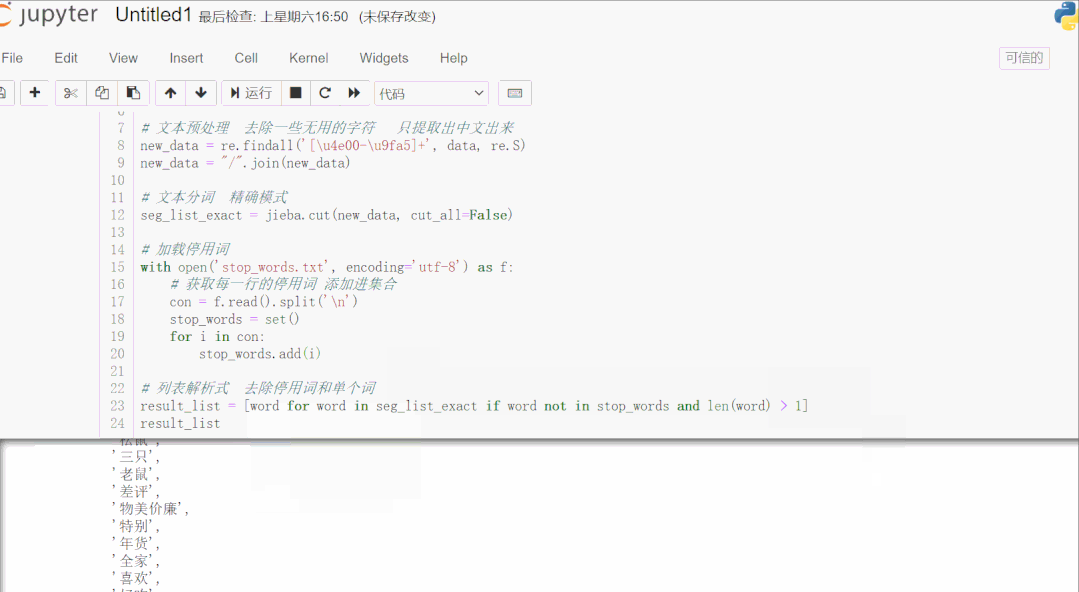
首先读取用于测试的文本数据,该数据是爬取的商品评论,这一类数据通常有很多无意义的字词和符号,通过正则表达式滤除掉无用的符号,只提取出中文出来。使用 jieba 库进行文本分词,加载停用词数据到集合,然后一行列表解析式滤除停用词和单个词,这样效率很高。停用词数据可以下载一些公开的,再根据实际文本处理需要,添加字词语料进去,使滤除效果更好。
Github下载停用词数据:https://github.com/zhousishuo/stopwords
SnowNLP是一个 Python 写的类库,可以方便的处理中文文本内容,是受到了 TextBlob 的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和 TextBlob 不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的 unicode 编码,所以使用时请自行 decode 成 unicode 编码。
使用 SnowNLP 处理中文文本数据非常方便,以词性标注和关键词提取为例:
- from snownlp import SnowNLP
- word = u'今天天气好 这个姑娘真好看'
- s = SnowNLP(word)
- print(s.words) # 分词
- print(list(s.tags)) # 词性标注

- from snownlp import SnowNLP
- text = u'''
- 自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。
- 它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
- 自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
- 因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,
- 所以它与语言学的研究有着密切的联系,但又有重要的区别。
- 自然语言处理并不是一般地研究自然语言,
- 而在于研制能有效地实现自然语言通信的计算机系统,
- 特别是其中的软件系统。因而它是计算机科学的一部分。
- '''
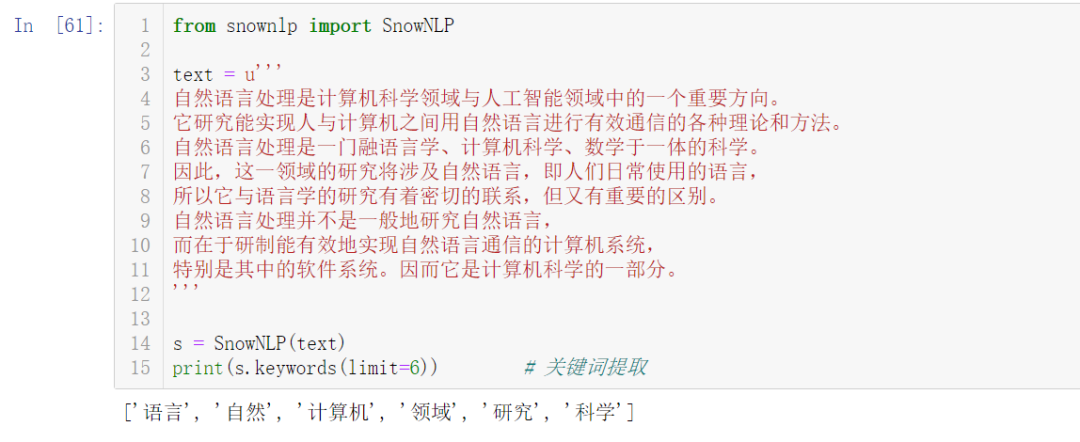
- s = SnowNLP(text)
- print(s.keywords(limit=6)) # 关键词提取
本文转载自微信公众号「修炼Python」,可以通过以下二维码关注。转载本文请联系修炼Python公众号。