对于节假日,难得的假期,尤其是外出的时候碰上几个数据库报警,那些报警又属于不得不处理的时候,真是让人上火,所以也想了一些办法来尽可能杜绝和避免这种情况。
一般来说是这样的几种策略:
1)提前在节假日的时候把报警的阈值调低,然后提前处理一波
2)在假期中期,主动进行巡检分析,至少在可控的时间里碰到问题提前处理比临时出现问题紧急解决要好得多。
3)多人互备,通常这种情况比较苦逼,得背着电脑到处跑,还得注意电脑电源,网络
当然也有一些机制可以借鉴,大体也是两类:
1)对于一些通常可控的处理问题,可以设定周期性任务进行提前处理,比如数据库的binlog增长较快,可以设置周期性任务来清理,通常定制化,本地化程度较高
2)对于一些可以预见的问题,可以设置处理动作脚本,然后周期性扫描,一旦发现问题就触发处理机制,所以这种模式通常是会碰到报警/报警恢复的周期性交替。
当然这些策略还不是上策,毕竟不够通用,有的时候问题还具有差异性,需要差异化处理。
举个例子来说,磁盘报警,如果磁盘报警在80%,那么问题其实紧急度还没那么高,处理机制优先处理磁盘空间能搞定最好,如果达到了90%,磁盘空间的清理改进空间就很有限了,就需要清理数据库日志等,如果继续增长问题的紧急度就会逐步升级,就需要接入业务逻辑,从一些日志表的数据来入手了。
大多数情况下的问题,通常通过系统空间清理和binlog的清理能够减缓问题的进一步升级,所以能够缓冲几个小时的时间也是很难得的。
和移动端的接入,也是和开发同事进行了深入沟通后集成起来的,这是一套已经稳定运行许久的功能模块,这方面我们还算是接入相对晚了。
移动端对于磁盘报警的处理,我定义的处理流程如下:
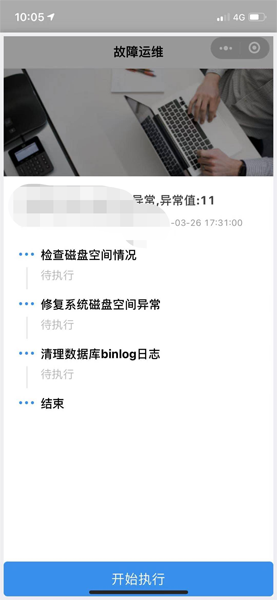
在触发报警后,在移动端可以对每个处理动作进行处理,后端会有相应的API和脚本进行调用,返回相应的数据参数。
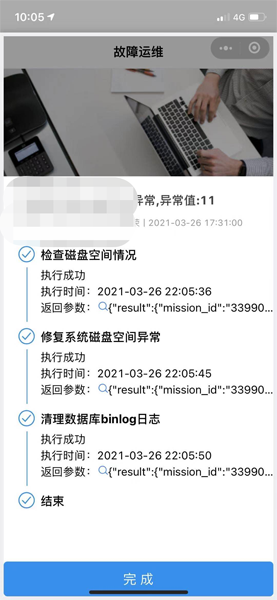
整个流程中,对于报警类别的定义和处理流程的编排是相对核心的步骤。
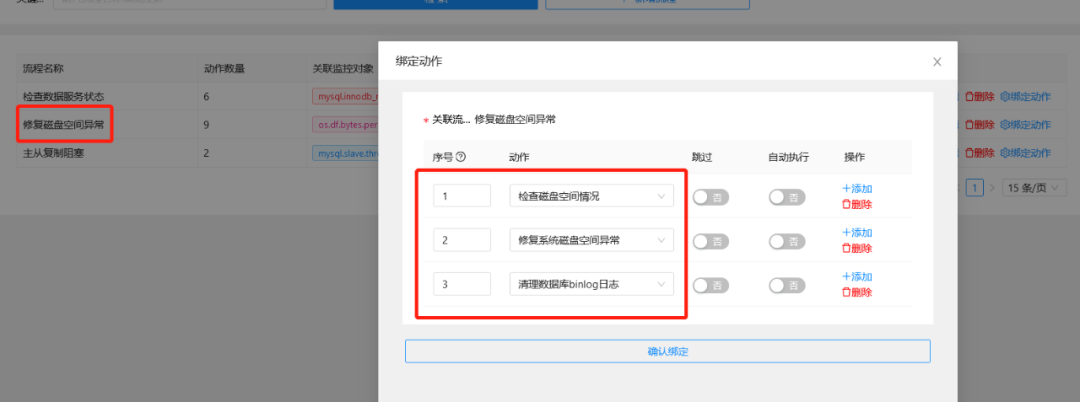
拆分下来,最细粒度的是每一个处理动作的定义。
后续基本能够放心的外出,在收到临时的报警后,心里也会波澜不惊了。
无论如何,这都是故障自愈的一个好的开始。
本文转载自微信公众号「杨建荣的学习笔记」,可以通过以下二维码关注。转载本文请联系杨建荣的学习笔记公众号。