在《RealPython 基础教程:Python 字典用法详解》这篇文章中,我们介绍了 dict 的特性:
- dict 是存储键值对的关联容器
- dict 中的 key 是唯一的
- 可使用 dict[key] 语法来快速访问 dict 中的元素
- Python 3.6 之后的版本会保持元素添加到 dict 中的顺序
那么,Python 底层是如何支撑这些特性的呢?其运行效率如何?
我们今天就来简单探索一下 dict 在 Python 中的底层实现,并尝试结合 CPython 源码来回答上边的问题。
【基本原理】
首先我们来思考一下如何从一批数据中快速查找一个元素。
在计算机中,对数据的访问是基于数据的存储方式的,不同的存储方式访问效率差别很大。
我们熟知的 list,底层是基于数组实现的。数组的优点在于能通过索引实现随机访问,非常快,时间复杂度为O(1)。但前提是,你需要知道被访问的元素的位置。而对于 key-value 这种关联数据,我们在应用中并不关注其存放位置。
如果单纯使用数组来存放 key-value,我们需要按顺序比对数组中的每个元素,找到目的 key。当数据量很大时,这种查找效率很低。
有没有能实现高效比对的数据结构呢?有!
学过 C++ 的同学应该知道,C++ 标准库提供了一个关联容器:map。它可以高效地存取键值对,其底层是基于红黑树来实现的。红黑树是一个自平衡的二叉搜索树,查找效率很高。
那么,Python 中的 dict 是基于红黑树实现的吗?答案是否定的。
Python 为了实现更快的访问速率,采用了另一种存储结构:哈希表。
哈希表基于数组随机访问的特性,使用哈希算法来快速计算 key 的哈希值,从而定位元素在底层数组中的位置,实现元素的快速访问。
这种结构的访问效率和数组相同,但是存在一定的缺点:哈希算法无法保证对每个 key 求值结果的唯一性,因而不同的 key 可能会得到相同的存放位置。这就导致了冲突。
哈希表需要采取一定的策略来避免键冲突。当然,存在冲突的键的访问效率也会有所降低。
下面我们就来看一下 CPython 是如何通过哈希表来实现 dict 的。
【字典相关数据结构】
1,字典对象 PyDictObject
- typedef struct {
- PyObject_HEAD
- /*字典用元素的个数*/
- Py_ssize_t ma_used;
- /*全局唯一的版本号,会在 dict 被修改时发生变化*/
- uint64_t ma_version_tag;
- /*存放元素或元素 key,承担哈希表的具体实现*/
- PyDictKeysObject *ma_keys;
- /*
- 当哈希表为组合(combined)模式时,value 存储在 ma_keys 的每个 PyDictKeyEntry 对象中,此值为 NULL。
- 当哈希表为分离(splitted)模式时用于存储元素的 value。
- */
- PyObject **ma_values;
- } PyDictObject;
每个 dict 都是一个 PyDictObject 对象。
此结构中,最重要的是 ma_keys 这个成员变量,它是实现哈希表的关键所在。
2,哈希表 PyDictKeysObject
- struct _dictkeysobject {
- Py_ssize_t dk_refcnt;
- /* 哈希表(dk_indices)的大小,其值为 2 的乘幂. */
- Py_ssize_t dk_size;
- /* 用于在哈希表(dk_indices)中执行查找的函数*/
- dict_lookup_func dk_lookup;
- /* dk_entries 中可用 entries 的个数 */
- Py_ssize_t dk_usable;
- /* dk_entries 中已用 entries 的个数 */
- Py_ssize_t dk_nentries;
- /* 哈希表. 可动态 resize。64位系统上其最小尺寸为8,32位系统上最小尺寸为4. */
- char dk_indices[];
- /* "PyDictKeyEntry dk_entries[dk_usable];" */
- };
- typedef struct _dictkeysobject PyDictKeysObject;
从名称来看,PyDictKeysObject 是用来存储字典元素的 key 的。而实际上,在组合模式下,它存储的是 key-value 对。那么,无论哪种模式,至少 key 是存储在这个对象中的。
这个对象是我们研究的重点。
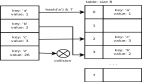
PyDictKeysObject 的内存布局如下所示:

我们在上边代码中简单标注了 PyDictObject 各成员变量的含义。现在重点关注dk_indices。
dk_indices 是一个 char 类型的数组,从定义来看,这是一块裸内存。它正是哈希表真正使用的存储空间。
dk_indices 数组的前部分存放的是字典元素(键值对)在 dk_entries 中的索引值。我们可把这部分叫做:哈希表索引内存块。
根据数组大小的不同,每个索引值的类型具有不同的解释方法。
| 索引类型 | 数组大小 dk_size |
|---|---|
| int8 | dk_size <= 128 |
| int16 | 256 <= dk_size <= 2**15 |
| int32 | 2**16 <= dk_size <= 2**31 |
| int64 | dk_size >= 2**32 |
由此可见,数组越大,每个值表示的索引范围也越大。
每个索引值的取值区间为[0, dk_size*2/3],或者为:-1(内存未被使用过),-2(内存已使用过)。
dk_indices 数组的后半部分用于存储 dict 中的元素。这段空间被解释为:PyDictKeyEntry dk_entries[dk_usable]。我们可把这部分叫做:哈希表键值对内存块。
dk_entries 中元素的个数为 dk_size 的 2/3。这个值既能有效减少 key 的冲突,也可提升内存空间的利用率。
3,字典元素
- typedef struct {
- Py_hash_t me_hash; /* 对 me_key 哈希值的缓存 */
- PyObject *me_key;
- PyObject *me_value; /* 仅当哈希表为组合模式时有意义 */
- } PyDictKeyEntry;
哈希表为组合模式时,这里边存放的就是我们的键值对。
哈希表为分离模式时,仅通过 me_key 存储元素是 key。
【hash 表】
从上边数据结构的定义中,我们已经知道,dict 会将键值对存放在一块连续的内存空间 dk_indices 中。dk_indices 正是 dict 使用的哈希表。
那么, 如何理解 dk_indices 这个哈希表呢?
通常,哈希表有两种实现方式:冲突链和开放寻址。这两种方式对应的是两种解决键冲突的方法。
冲突链:将哈希值相同的 key 组织为一个链表。
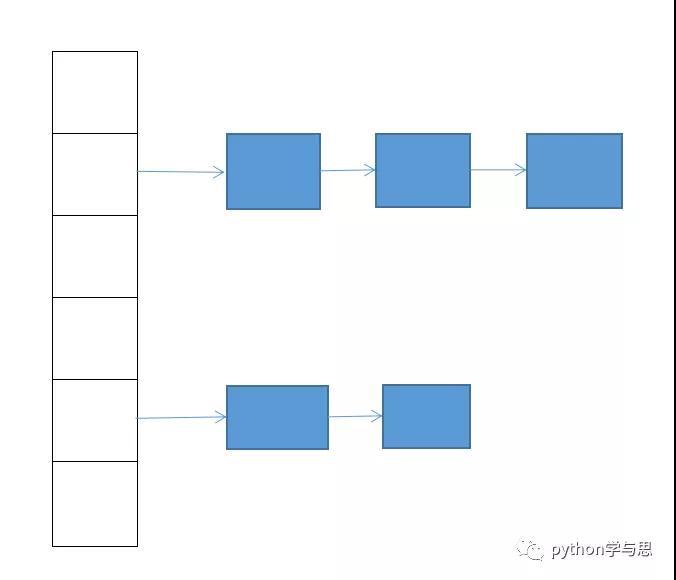
哈希表只存放指向元素链表的指针,哈希值相同的元素依次追加到每个链表的尾部。
开放寻址:从哈希表中的冲突位置查找下一个可用的位置。
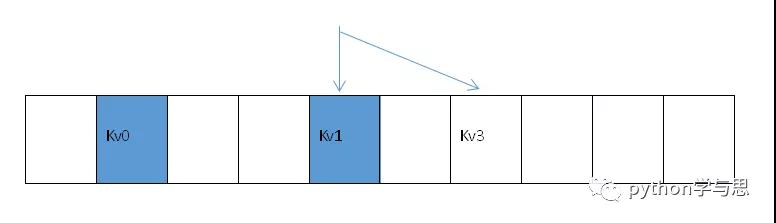
元素存放在哈希表中,若发现冲突,从冲突位置(如 kv1 所在位置)开始通过某种策略查找下一个可用的位置(如 kv3)。
CPython 采用的是开放寻址方式,并且使用了一种优化的存储结构。
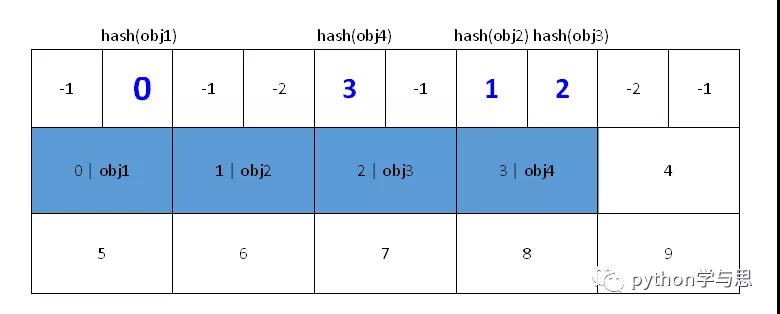
dk_indices 数组的前部分用来存储键值对的位置索引,后部分用来存储键值对。这是一种高效紧凑的存储结构。
我们从 dictobject.c 的 insert_dict() 函数中截取一段代码,来验证这个结构。
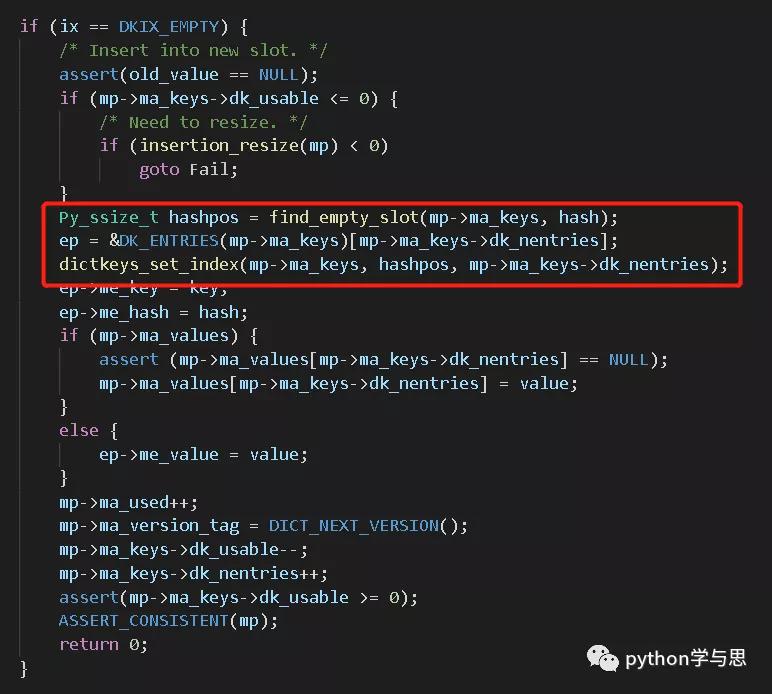
insertdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject *value) 函数用于向字典 mp 中插入一个哈希值为 hash 的 key-value 键值对。
这个片段开头的 if (ix == DKIX_EMPTY) 表明可以将这个键值对插入哈希表的一个未曾使用过的位置(称为 slot)中。
代码接下来检查哈希表剩余空间是否可用,不足则 resize。
接下来调用 find_empty_slot() 获取 slot 在哈希表索引内存块中的位置索引 hashpos,这个函数实现了冲突算法。
通过 DK_ENTRIES 宏获取 ma_keys 中下一块可用的内存 ep,由于哈希表键值对内存块是连续的,下一块可用的内存可通过当前已存储的键值对个数 dk_nentries 加上 dk_indices 前部分的偏移计算而来。
- #define DK_ENTRIES(dk) \
- ((PyDictKeyEntry*)(&((int8_t*)((dk)->dk_indices))[DK_SIZE(dk) * DK_IXSIZE(dk)]))
我们通过 DK_ENTRIES 的宏定义能清楚地看到它是在访问 dk_indices 的键值对内存块。
现在,我们知道了元素在哈希表索引内存块中的位置 hashpos 和在键值对内存块中的“相对位置” dk_nentries,调用 dictkeys_set_index() 即可在哈希表中设置这两者的关系:indices[hashpos] = dk_nentries.
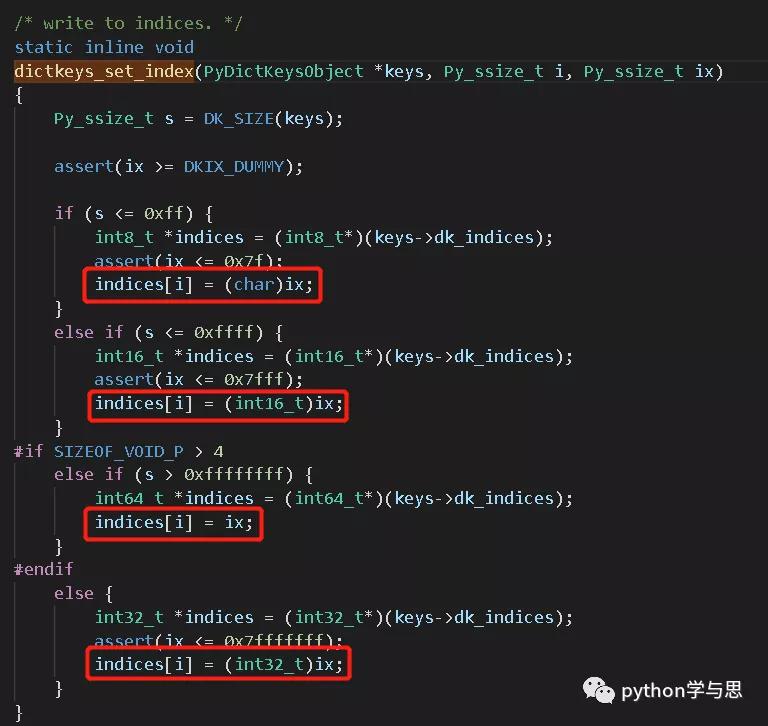
接下来的代码对 ep 指向的内存数据进行了更新,并累加 dk_nentries。
大家可仔细体会一下这个过程。
这种存储结构,也保证了使用 key 访问元素的效率。
由 key 的哈希值能快速映射到元素在哈希表索引内存块的位置 hashpos,再由 hashpos 中保存的键值对内存块的位置偏移“索引”就可以直接访问对应的键值对。
【hash 算法和冲突算法】
实现哈希表有三个重要的元素:数据结构、hash 算法和冲突算法。
我们已经了解了数据结构。那么,CPython 使用什么 hash 算法呢?
如果你没有手动实现 __hash__ 方法,它就使用内置的 hash() 函数来计算 key 的哈希值。
CPython 采用开放寻址的方法来解决冲突。
其冲突算法如下:
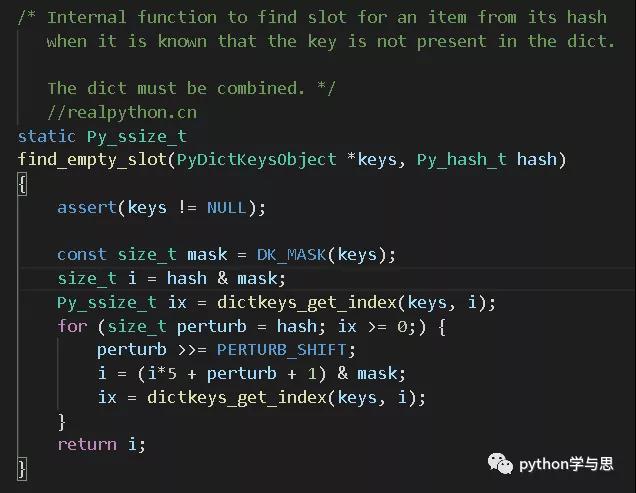
首先初始化哈希表的位置索引 i,然后获取 i 处存放的键值对内存块的索引 ix。在循环中不断更新 i 并检测 ix 的值,直到 ix < 0,即此时哈希表索引内存块的 i 处代表着一个从未使用的 slot。
更新 i 的算法不太容易理解,可不用深究。
【如何保持元素插入顺序】
dict 一个有趣的特性就是会保持元素插入时的位置顺序:
- >>> d={}
- >>> d[3]="Three"
- >>> d[1]="One"
- >>> d[2]="Two"
- >>> d[0]="Zero"
- >>> d
- {3: 'Three', 1: 'One', 2: 'Two', 0: 'Zero'}
- >>>
- >>> list(d.keys())
- [3, 1, 2, 0]
从上边对哈希表的分析中,我们很容易就能明白其中的原因:元素被逐个追加到键值对内存块的尾部。
当我们打印 dict,或调用其 keys() 方法时,dict 直接访问键值对内存块。因而可按照元素插入时的顺序将它们返回。
【resize】
既然 dict 使用了连续的内存块来实现哈希表,那么当插入较多元素时,其内存空间有可能不足,这时就需要扩大内存。另一方面,如果之前已分配了较大内存空间,而后执行了大量删除元素的操作,这时候也有必要减小内存,避免浪费。
- static int
- insertion_resize(PyDictObject *mp)
- {
- return dictresize(mp, GROWTH_RATE(mp));
- }
insertion_resize() 调用 dictresize() 来调整 dict 的大小。dictresize() 的第二个参数就是调整后的大小,这里是一个宏。在 CPython 3.9.2 中,其定义为:
#define GROWTH_RATE(d) ((d)->ma_used*3)
可以看到,dict 的大小会被调整为原来已使用(包含有效键值对)内存的 3 倍。
这个调整幅度还是蛮大的,其好处是可以避免频繁 resize。
【结语】
本文简单介绍了 Python 字典的底层数据结构和实现算法,通过使用内存优化的哈希表,dict 很好地支持了快速查找和插入有序等特性。这种数据结构设计方法非常很值得我们在开发中借鉴使用。
本文转载自微信公众号「python学与思」,可以通过以下二维码关注。转载本文请联系python学与思公众号。