最近拜读了一些Java Map的相关源码,不得不惊叹于JDK开发者们的鬼斧神工。他山之石可以攻玉,这些巧妙的设计思想非常有借鉴价值,可谓是最佳实践。然而,大多数有关Java Map原理的科普类文章都是专注于“点”,并没有连成“线”,甚至形成“网状结构”。因此,本文基于个人理解,对所阅读的部分源码进行了分类与总结,归纳出Map中的几个核心特性,包括:自动扩容、初始化与懒加载、哈希计算、位运算与并发,并结合源码进行深入讲解,希望看完本文的你也能从中获取到些许收获(本文默认采用JDK1.8中的HashMap)。
一 自动扩容
最小可用原则,容量超过一定阈值便自动进行扩容。
扩容是通过resize方法来实现的。扩容发生在putVal方法的最后,即写入元素之后才会判断是否需要扩容操作,当自增后的size大于之前所计算好的阈值threshold,即执行resize操作。

通过位运算<<1进行容量扩充,即扩容1倍,同时新的阈值newThr也扩容为老阈值的1倍。
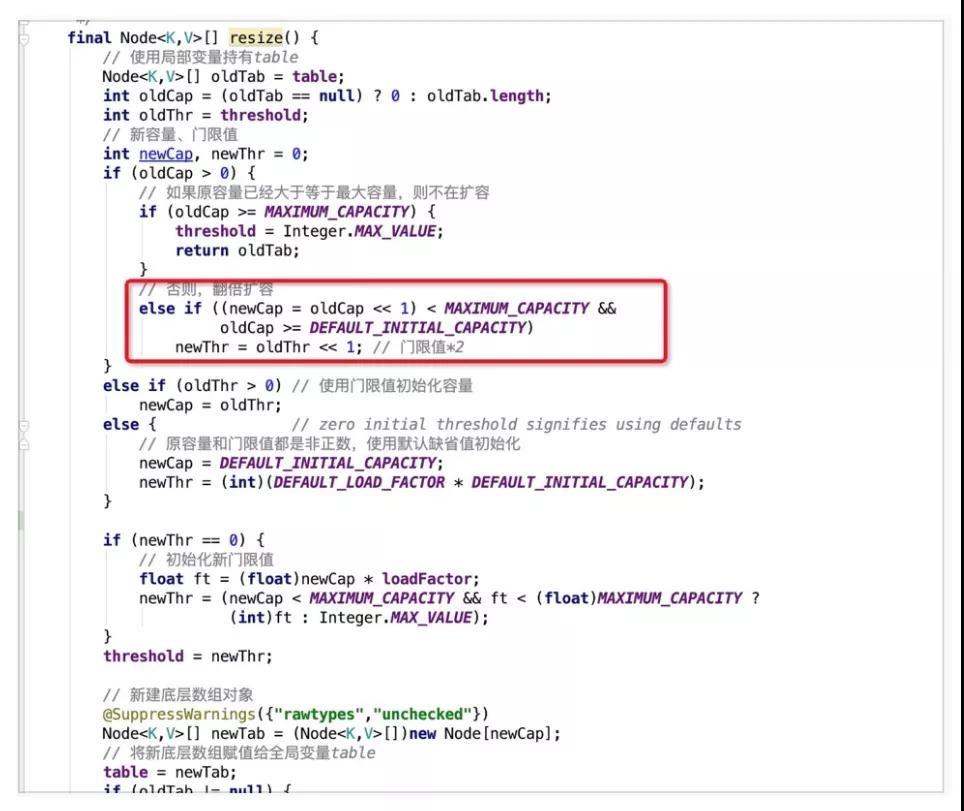
扩容时,总共存在三种情况:
- 哈希桶数组中某个位置只有1个元素,即不存在哈希冲突时,则直接将该元素copy至新哈希桶数组的对应位置即可。
- 哈希桶数组中某个位置的节点为树节点时,则执行红黑树的扩容操作。
- 哈希桶数组中某个位置的节点为普通节点时,则执行链表扩容操作,在JDK1.8中,为了避免之前版本中并发扩容所导致的死链问题,引入了高低位链表辅助进行扩容操作。
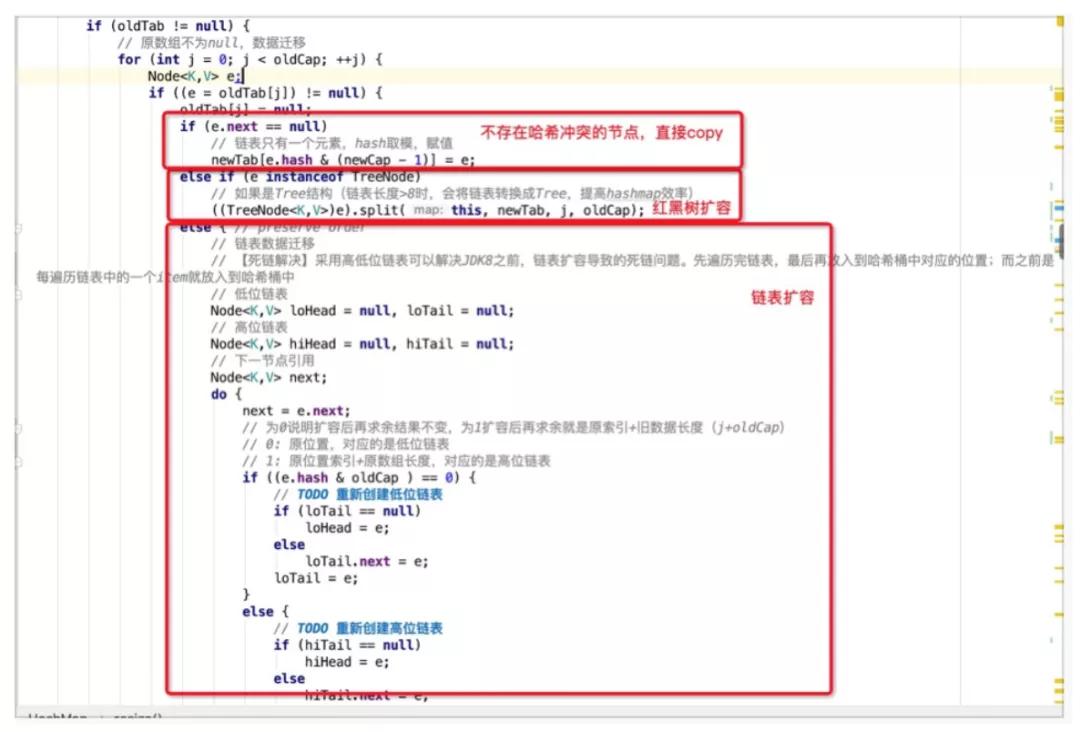
在日常的开发过程中,会遇到一些bad case,比如:
当hashMap设置最后一个元素3的时候,会发现当前的哈希桶数组大小已经达到扩容阈值2*0.75=1.5,紧接着会执行一次扩容操作,因此,此类的代码每次运行的时候都会进行一次扩容操作,效率低下。在日常开发过程中,一定要充分评估好HashMap的大小,尽可能保证扩容的阈值大于存储元素的数量,减少其扩容次数。
二 初始化与懒加载
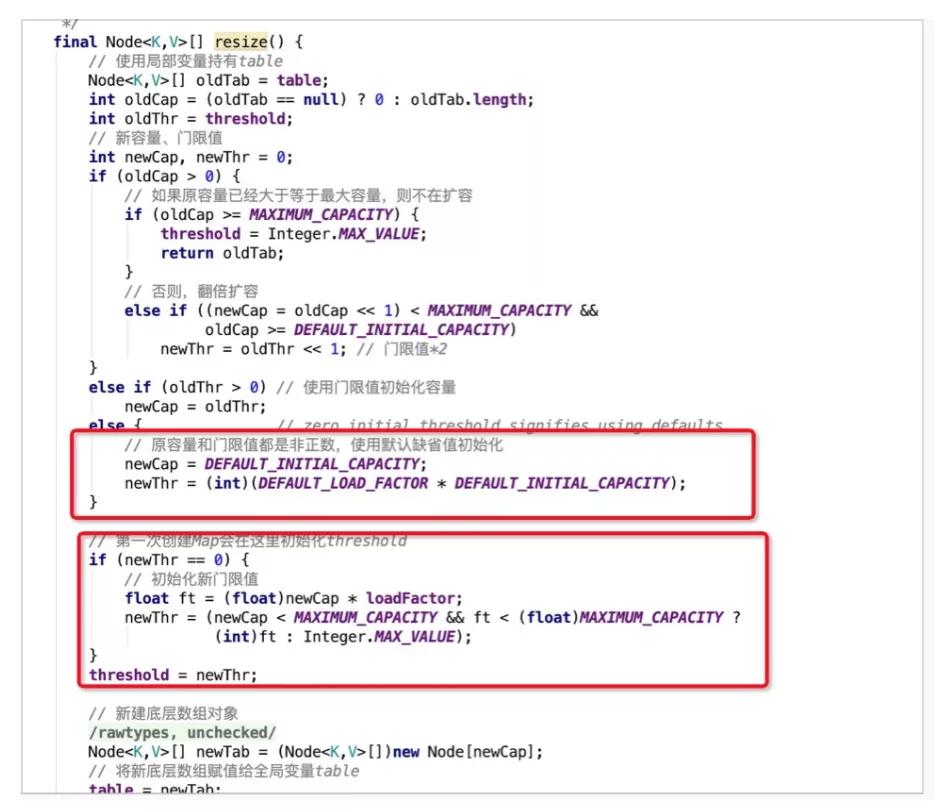
初始化的时候只会设置默认的负载因子,并不会进行其他初始化的操作,在首次使用的时候才会进行初始化。
当new一个新的HashMap的时候,不会立即对哈希数组进行初始化,而是在首次put元素的时候,通过resize()方法进行初始化。
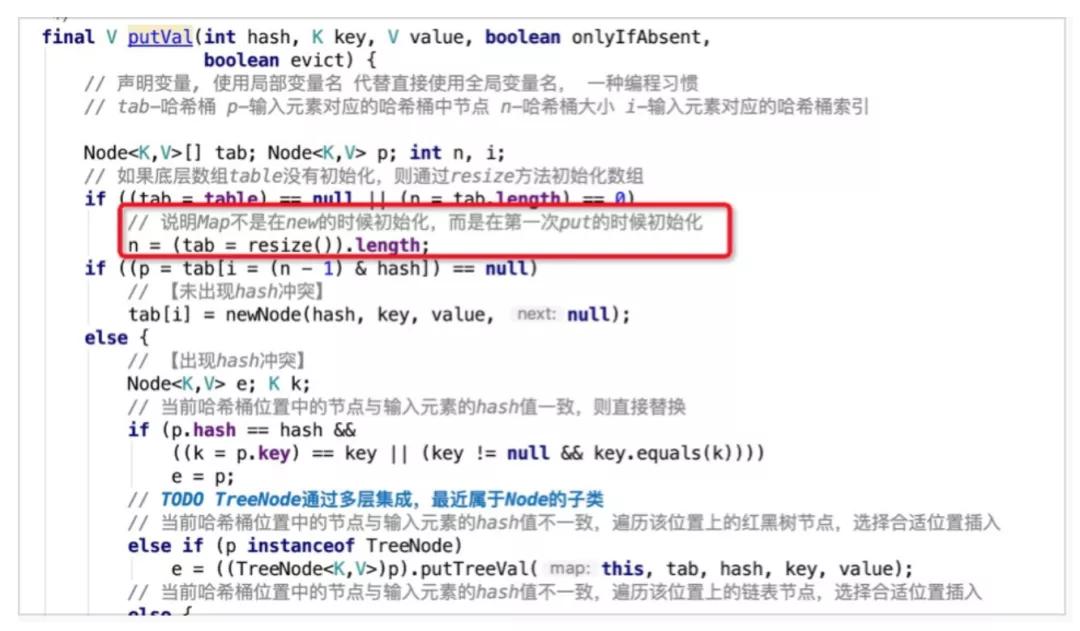
resize()中会设置默认的初始化容量DEFAULT_INITIAL_CAPACITY为16,扩容的阈值为0.75*16 = 12,即哈希桶数组中元素达到12个便进行扩容操作。
最后创建容量为16的Node数组,并赋值给成员变量哈希桶table,即完成了HashMap的初始化操作。
三 哈希计算
哈希表以哈希命名,足以说明哈希计算在该数据结构中的重要程度。而在实现中,JDK并没有直接使用Object的native方法返回的hashCode作为最终的哈希值,而是进行了二次加工。
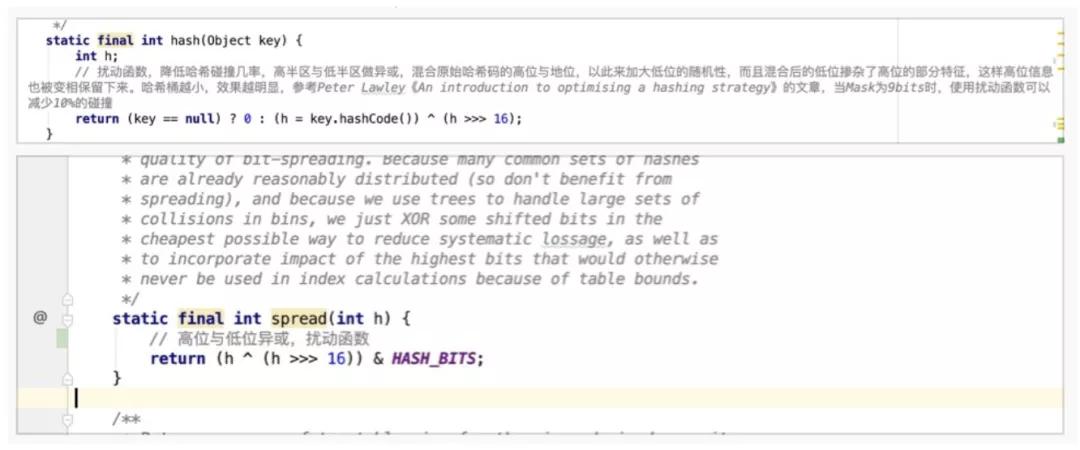
以下分别为HashMap与ConcurrentHashMap计算hash值的方法,核心的计算逻辑相同,都是使用key对应的hashCode与其hashCode右移16位的结果进行异或操作。此处,将高16位与低16位进行异或的操作称之为扰动函数,目的是将高位的特征融入到低位之中,降低哈希冲突的概率。
举个例子来理解下扰动函数的作用:
若HashMap容量为4,在不使用扰动函数的情况下,key1与key2的hashCode注定会冲突(后两位相同,均为01)。
经过扰动函数处理后,可见key1与key2 hashcode的后两位不同,上述的哈希冲突也就避免了。
这种增益会随着HashMap容量的减少而增加。《An introduction to optimising a hashing strategy》文章中随机选取了哈希值不同的352个字符串,当HashMap的容量为2^9时,使用扰动函数可以减少10%的碰撞,可见扰动函数的必要性。
此外,ConcurrentHashMap中经过扰乱函数处理之后,需要与HASH_BITS做与运算,HASH_BITS为0x7ffffff,即只有最高位为0,这样运算的结果使hashCode永远为正数。在ConcurrentHashMap中,预定义了几个特殊节点的hashCode,如:MOVED、TREEBIN、RESERVED,它们的hashCode均定义为负值。因此,将普通节点的hashCode限定为正数,也就是为了防止与这些特殊节点的hashCode产生冲突。
1 哈希冲突
通过哈希运算,可以将不同的输入值映射到指定的区间范围内,随之而来的是哈希冲突问题。考虑一个极端的case,假设所有的输入元素经过哈希运算之后,都映射到同一个哈希桶中,那么查询的复杂度将不再是O(1),而是O(n),相当于线性表的顺序遍历。因此,哈希冲突是影响哈希计算性能的重要因素之一。哈希冲突如何解决呢?主要从两个方面考虑,一方面是避免冲突,另一方面是在冲突时合理地解决冲突,尽可能提高查询效率。前者在上面的章节中已经进行介绍,即通过扰动函数来增加hashCode的随机性,避免冲突。针对后者,HashMap中给出了两种方案:拉链表与红黑树。
拉链表
在JDK1.8之前,HashMap中是采用拉链表的方法来解决冲突,即当计算出的hashCode对应的桶上已经存在元素,但两者key不同时,会基于桶中已存在的元素拉出一条链表,将新元素链到已存在元素的前面。当查询存在冲突的哈希桶时,会顺序遍历冲突链上的元素。同一key的判断逻辑如下图所示,先判断hash值是否相同,再比较key的地址或值是否相同。

(1)死链
在JDK1.8之前,HashMap在并发场景下扩容时存在一个bug,形成死链,导致get该位置元素的时候,会死循环,使CPU利用率高居不下。这也说明了HashMap不适于用在高并发的场景,高并发应该优先考虑JUC中的ConcurrentHashMap。然而,精益求精的JDK开发者们并没有选择绕过问题,而是选择直面问题并解决它。在JDK1.8之中,引入了高低位链表(双端链表)。
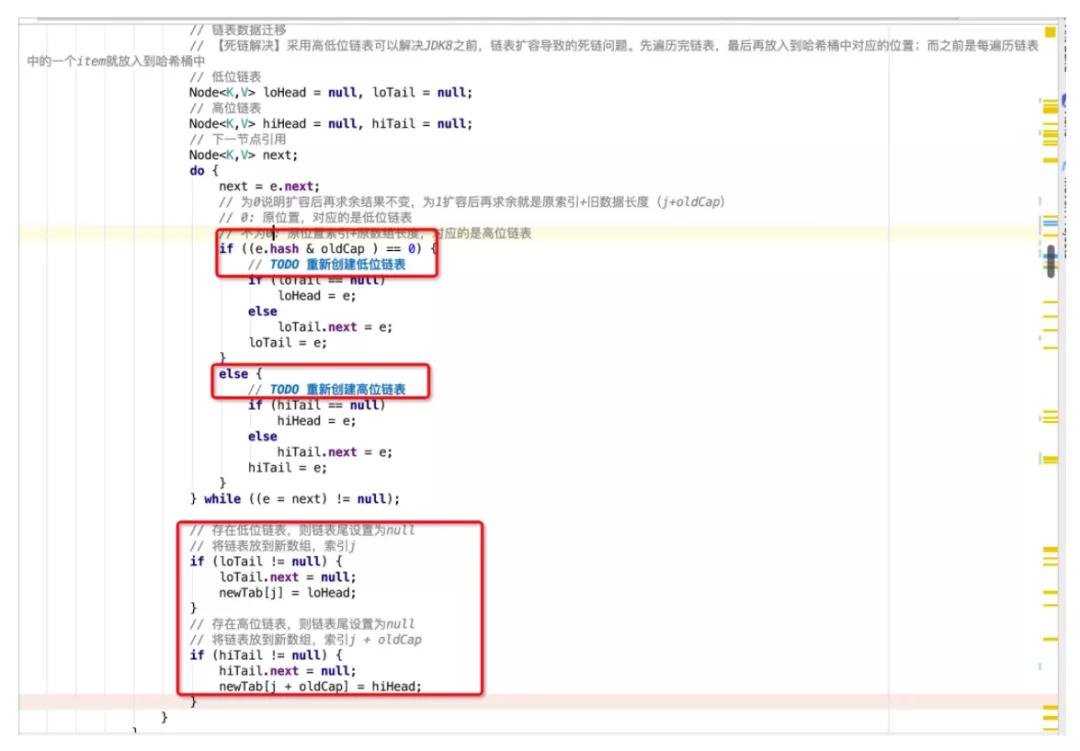
什么是高低位链表呢?在扩容时,哈希桶数组buckets会扩容一倍,以容量为8的HashMap为例,原有容量8扩容至16,将[0, 7]称为低位,[8, 15]称为高位,低位对应loHead、loTail,高位对应hiHead、hiTail。
扩容时会依次遍历旧buckets数组的每一个位置上面的元素:
- 若不存在冲突,则重新进行hash取模,并copy到新buckets数组中的对应位置。
- 若存在冲突元素,则采用高低位链表进行处理。通过e.hash & oldCap来判断取模后是落在高位还是低位。举个例子:假设当前元素hashCode为0001(忽略高位),其运算结果等于0,说明扩容后结果不变,取模后还是落在低位[0, 7],即0001 & 1000 = 0000,还是原位置,再用低位链表将这类的元素链接起来。假设当前元素的hashCode为1001, 其运算结果不为0,即1001 & 1000 = 1000 ,扩容后会落在高位,新的位置刚好是旧数组索引(1) + 旧数据长度(8) = 9,再用高位链表将这些元素链接起来。最后,将高低位链表的头节点分别放在扩容后数组newTab的指定位置上,即完成了扩容操作。这种实现降低了对共享资源newTab的访问频次,先组织冲突节点,最后再放入newTab的指定位置。避免了JDK1.8之前每遍历一个元素就放入newTab中,从而导致并发扩容下的死链问题。
红黑树
在JDK1.8之中,HashMap引入了红黑树来处理哈希冲突问题,而不再是拉链表。那么为什么要引入红黑树来替代链表呢?虽然链表的插入性能是O(1),但查询性能确是O(n),当哈希冲突元素非常多时,这种查询性能是难以接受的。因此,在JDK1.8中,如果冲突链上的元素数量大于8,并且哈希桶数组的长度大于64时,会使用红黑树代替链表来解决哈希冲突,此时的节点会被封装成TreeNode而不再是Node(TreeNode其实继承了Node,以利用多态特性),使查询具备O(logn)的性能。
这里简单地回顾一下红黑树,它是一种平衡的二叉树搜索树,类似地还有AVL树。两者核心的区别是AVL树追求“绝对平衡”,在插入、删除节点时,成本要高于红黑树,但也因此拥有了更好的查询性能,适用于读多写少的场景。然而,对于HashMap而言,读写操作其实难分伯仲,因此选择红黑树也算是在读写性能上的一种折中。
四 位运算
1 确定哈希桶数组大小
找到大于等于给定值的最小2的整数次幂。
tableSizeFor根据输入容量大小cap来计算最终哈希桶数组的容量大小,找到大于等于给定值cap的最小2的整数次幂。乍眼一看,这一行一行的位运算让人云里雾里,莫不如采用类似找规律的方式来探索其中的奥秘。

当cap为3时,计算过程如下:
当cap为5时,计算过程如下:
因此,计算的意义在于找到大于等于cap的最小2的整数次幂。整个过程是找到cap对应二进制中最高位的1,然后每次以2倍的步长(依次移位1、2、4、8、16)复制最高位1到后面的所有低位,把最高位1后面的所有位全部置为1,最后进行+1,即完成了进位。
类似二进制位的变化过程如下:
找到输入cap的最小2的整数次幂作为最终容量可以理解为最小可用原则,尽可能地少占用空间,但是为什么必须要2的整数次幂呢?答案是,为了提高计算与存储效率,使每个元素对应hash值能够准确落入哈希桶数组给定的范围区间内。确定数组下标采用的算法是 hash & (n - 1),n即为哈希桶数组的大小。由于其总是2的整数次幂,这意味着n-1的二进制形式永远都是0000111111的形式,即从最低位开始,连续出现多个1,该二进制与任何值进行&运算都会使该值映射到指定区间[0, n-1]。比如:当n=8时,n-1对应的二进制为0111,任何与0111进行&运算都会落入[0,7]的范围内,即落入给定的8个哈希桶中,存储空间利用率100%。举个反例,当n=7,n-1对应的二进制为0110,任何与0110进行&运算会落入到第0、6、4、2个哈希桶,而不是[0,6]的区间范围内,少了1、3、5三个哈希桶,这导致存储空间利用率只有不到60%,同时也增加了哈希碰撞的几率。
2 ASHIFT偏移量计算
获取给定值的最高有效位数(移位除了能够进行乘除运算,还能用于保留高、低位操作,右移保留高位,左移保留低位)。
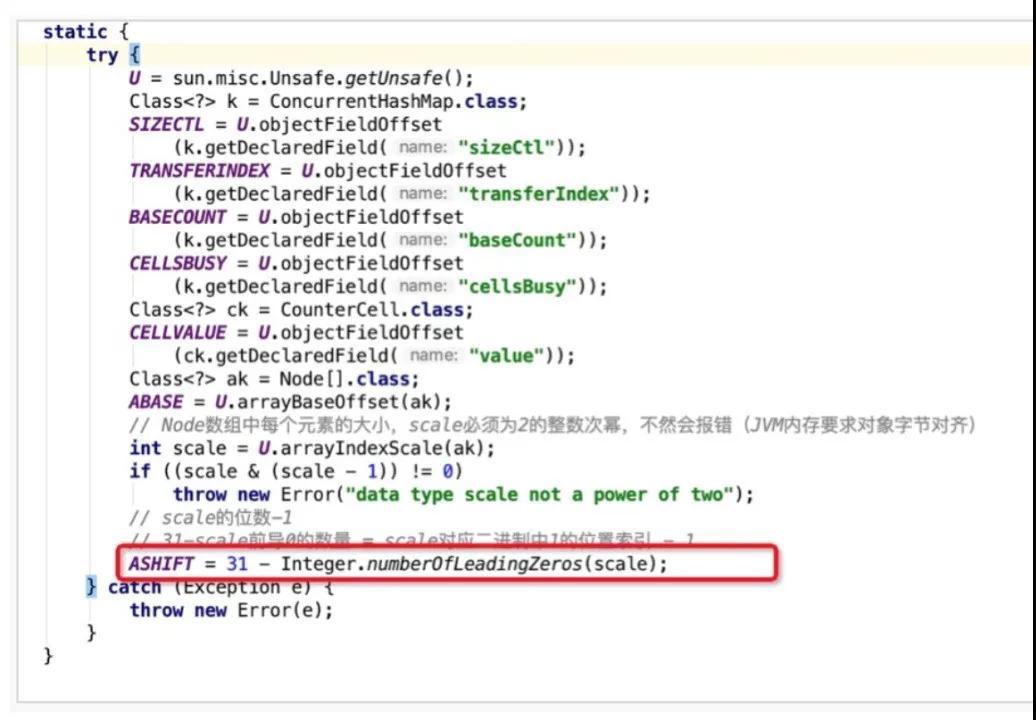
ConcurrentHashMap中的ABASE+ASHIFT是用来计算哈希数组中某个元素在实际内存中的初始位置,ASHIFT采取的计算方式是31与scale前导0的数量做差,也就是scale的实际位数-1。scale就是哈希桶数组Node[]中每个元素的大小,通过((long)i << ASHIFT) + ABASE)进行计算,便可得到数组中第i个元素的起始内存地址。
我们继续看下前导0的数量是怎么计算出来的,numberOfLeadingZeros是Integer的静态方法,还是沿用找规律的方式一探究竟。
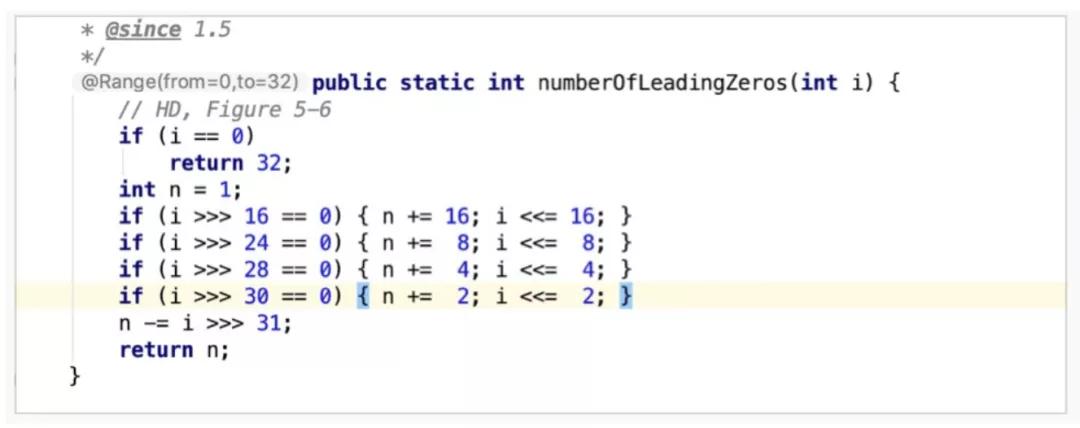
假设 i = 0000 0000 0000 0100 0000 0000 0000 0000,n = 1
右移了24位等于0,说明24位到31位之间肯定全为0,即n = 1 + 8 = 9,由于高8位全为0,并且已经将信息记录至n中,因此可以舍弃高8位,即 i <<= 8。此时,
类似地,i >>> 28 也等于0,说明28位到31位全为0,n = 9 + 4 = 13,舍弃高4位。此时,
继续运算,
最终可得出n = 13,即有13个前导0。n -= i >>> 31是检查最高位31位是否是1,因为n初始化为1,如果最高位是1,则不存在前置0,即n = n - 1 = 0。
总结一下,以上的操作其实是基于二分法的思想来定位二进制中1的最高位,先看高16位,若为0,说明1存在于低16位;反之存在高16位。由此将搜索范围由32位(确切的说是31位)减少至16位,进而再一分为二,校验高8位与低8位,以此类推。
计算过程中校验的位数依次为16、8、4、2、1,加起来刚好为31。为什么是31不是32呢?因为前置0的数量为32的情况下i只能为0,在前面的if条件中已经进行过滤。这样一来,非0值的情况下,前置0只能出现在高31位,因此只需要校验高31位即可。最终,用总位数减去计算出来的前导0的数量,即可得出二进制的最高有效位数。代码中使用的是31 - Integer.numberOfLeadingZeros(scale),而不是总位数32,这是为了能够得到哈希桶数组中第i个元素的起始内存地址,方便进行CAS等操作。
五 并发
1 悲观锁
全表锁
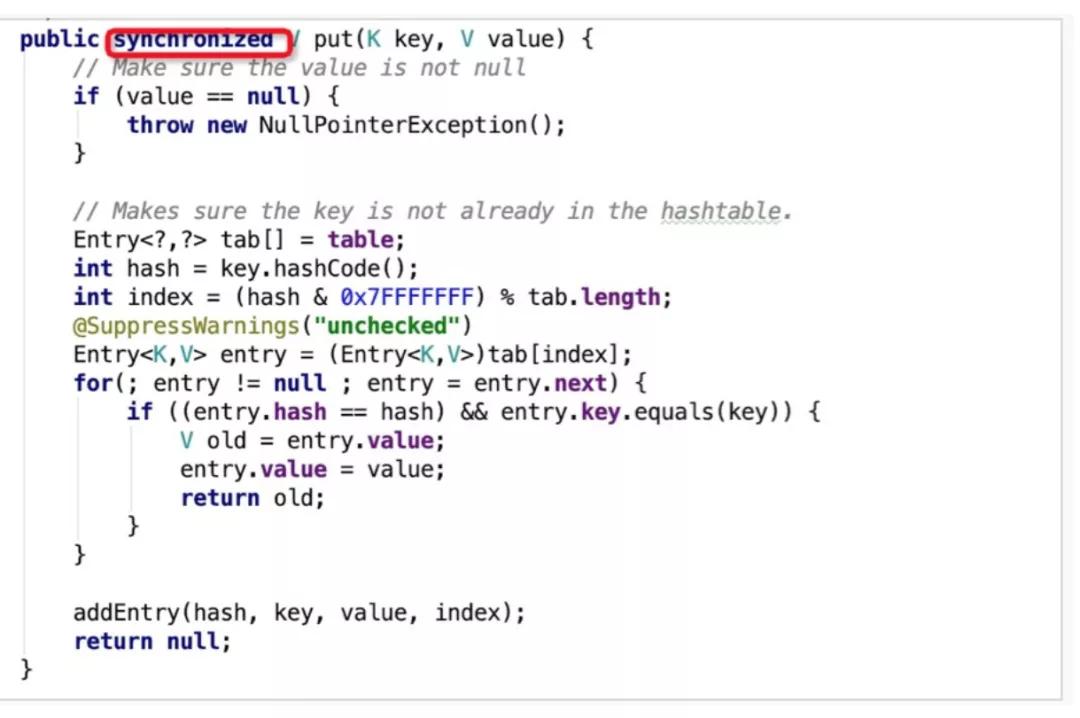
HashTable中采用了全表锁,即所有操作均上锁,串行执行,如下图中的put方法所示,采用synchronized关键字修饰。这样虽然保证了线程安全,但是在多核处理器时代也极大地影响了计算性能,这也致使HashTable逐渐淡出开发者们的视野。
分段锁
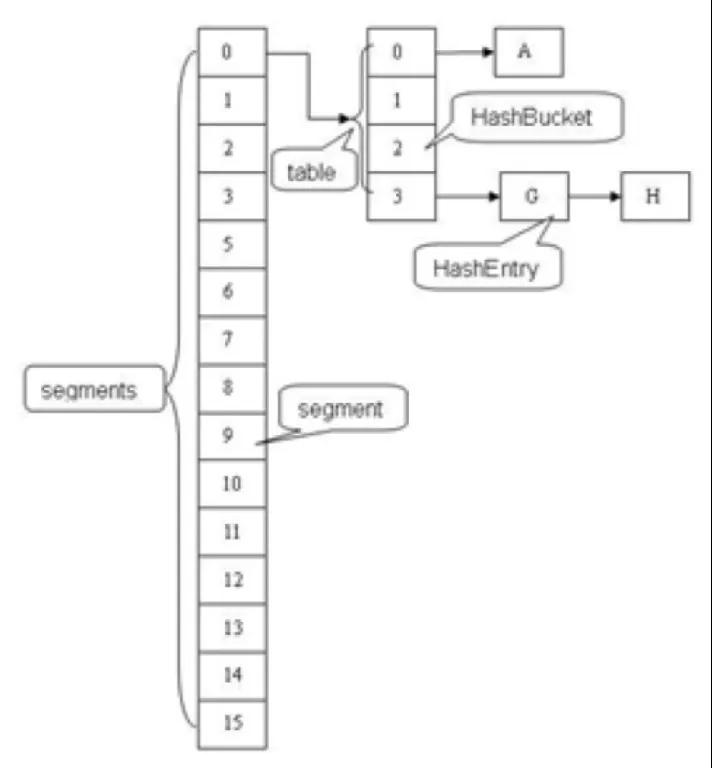
针对HashTable中锁粒度过粗的问题,在JDK1.8之前,ConcurrentHashMap引入了分段锁机制。整体的存储结构如下图所示,在原有结构的基础上拆分出多个segment,每个segment下再挂载原来的entry(上文中经常提到的哈希桶数组),每次操作只需要锁定元素所在的segment,不需要锁定整个表。因此,锁定的范围更小,并发度也会得到提升。
2 乐观锁
Synchronized+CAS
虽然引入了分段锁的机制,即可以保证线程安全,又可以解决锁粒度过粗导致的性能低下问题,但是对于追求极致性能的工程师来说,这还不是性能的天花板。因此,在JDK1.8中,ConcurrentHashMap摒弃了分段锁,使用了乐观锁的实现方式。放弃分段锁的原因主要有以下几点:
- 使用segment之后,会增加ConcurrentHashMap的存储空间。
- 当单个segment过大时,并发性能会急剧下降。
ConcurrentHashMap在JDK1.8中的实现废弃了之前的segment结构,沿用了与HashMap中的类似的Node数组结构。

ConcurrentHashMap中的乐观锁是采用synchronized+CAS进行实现的。这里主要看下put的相关代码。
当put的元素在哈希桶数组中不存在时,则直接CAS进行写操作。
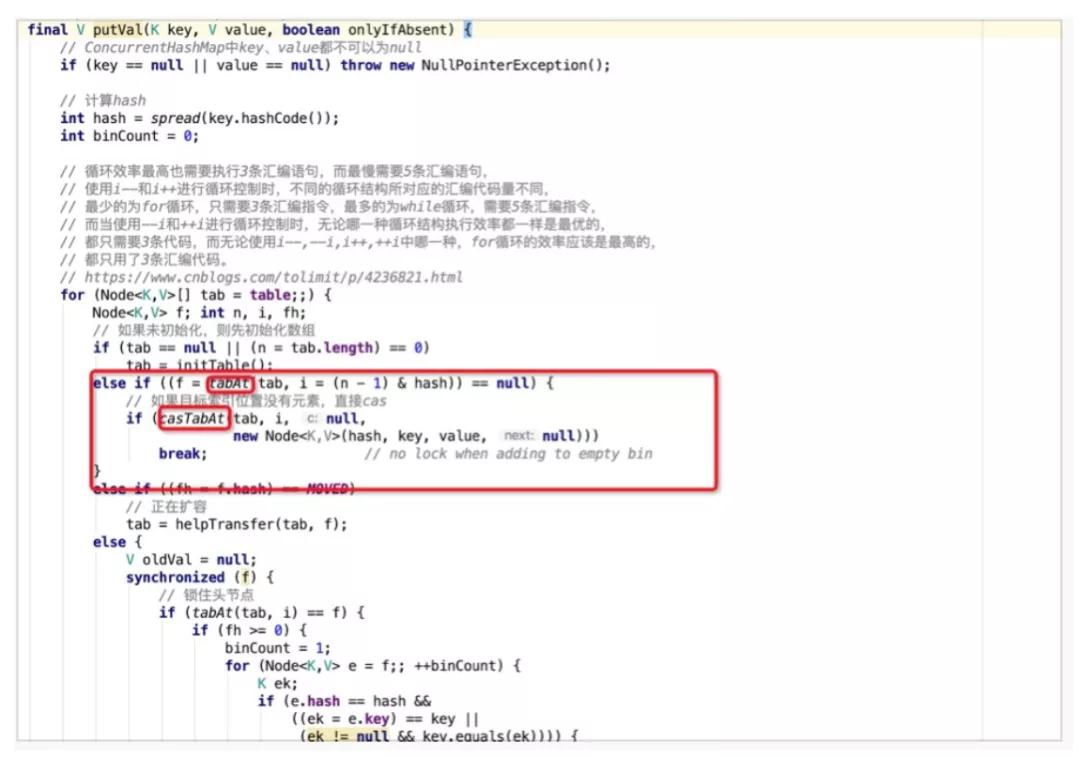
这里涉及到了两个重要的操作,tabAt与casTabAt。可以看出,这里面都使用了Unsafe类的方法。Unsafe这个类在日常的开发过程中比较罕见。我们通常对Java语言的认知是:Java语言是安全的,所有操作都基于JVM,在安全可控的范围内进行。然而,Unsafe这个类会打破这个边界,使Java拥有C的能力,可以操作任意内存地址,是一把双刃剑。这里使用到了前文中所提到的ASHIFT,来计算出指定元素的起始内存地址,再通过getObjectVolatile与compareAndSwapObject分别进行取值与CAS操作。
在获取哈希桶数组中指定位置的元素时为什么不能直接get而是要使用getObjectVolatile呢?因为在JVM的内存模型中,每个线程有自己的工作内存,也就是栈中的局部变量表,它是主存的一份copy。因此,线程1对某个共享资源进行了更新操作,并写入到主存,而线程2的工作内存之中可能还是旧值,脏数据便产生了。Java中的volatile是用来解决上述问题,保证可见性,任意线程对volatile关键字修饰的变量进行更新时,会使其它线程中该变量的副本失效,需要从主存中获取最新值。虽然ConcurrentHashMap中的Node数组是由volatile修饰的,可以保证可见性,但是Node数组中元素是不具备可见性的。因此,在获取数据时通过Unsafe的方法直接到主存中拿,保证获取的数据是最新的。

继续往下看put方法的逻辑,当put的元素在哈希桶数组中存在,并且不处于扩容状态时,则使用synchronized锁定哈希桶数组中第i个位置中的第一个元素f(头节点2),接着进行double check,类似于DCL单例模式的思想。校验通过后,会遍历当前冲突链上的元素,并选择合适的位置进行put操作。此外,ConcurrentHashMap也沿用了HashMap中解决哈希冲突的方案,链表+红黑树。这里只有在发生哈希冲突的情况下才使用synchronized锁定头节点,其实是比分段锁更细粒度的锁实现,只在特定场景下锁定其中一个哈希桶,降低锁的影响范围。
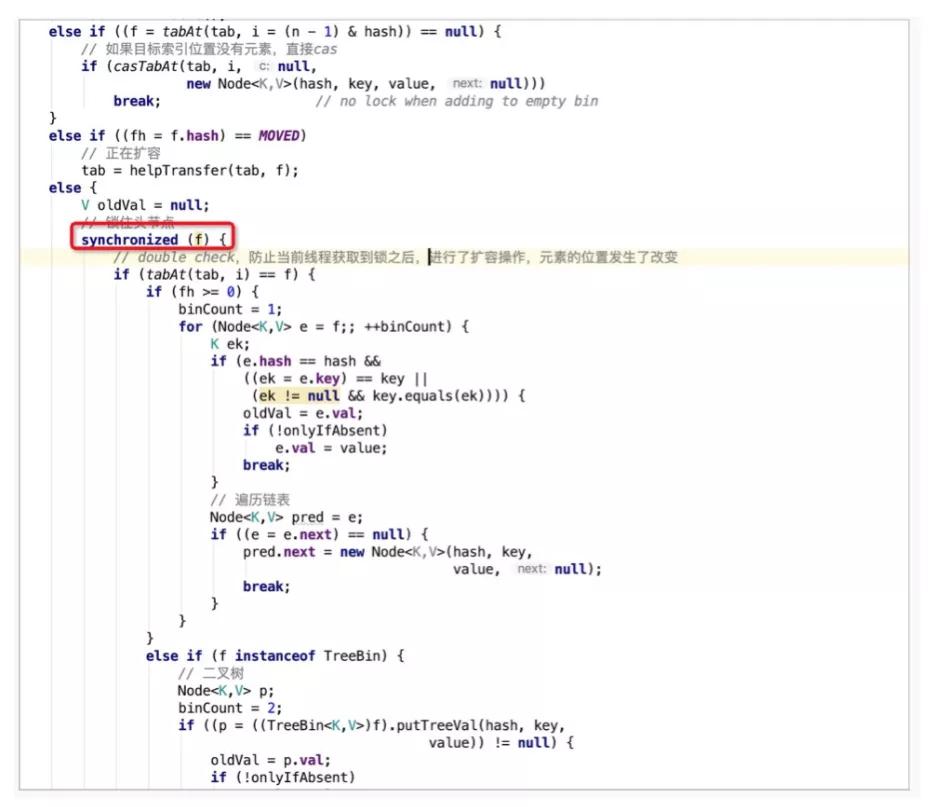
Java Map针对并发场景解决方案的演进方向可以归结为,从悲观锁到乐观锁,从粗粒度锁到细粒度锁,这也可以作为我们在日常并发编程中的指导方针。
3 并发求和
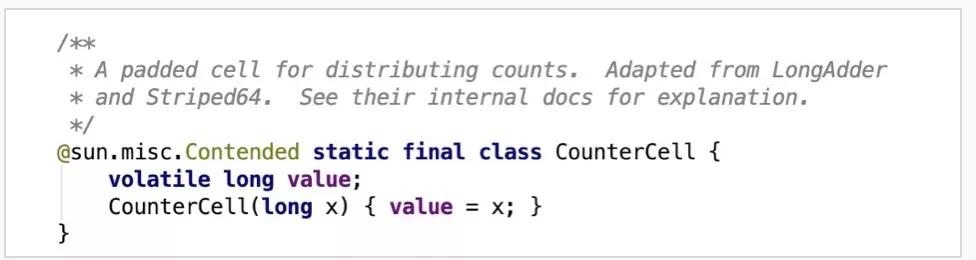
CounterCell是JDK1.8中引入用来并发求和的利器,而在这之前采用的是【尝试无锁求和】+【冲突时加锁重试】的策略。看下CounterCell的注释,它是改编自LongAdder和Striped64。我们先看下求和操作,其实就是取baseCount作为初始值,然后遍历CounterCell数组中的每一个cell,将各个cell的值进行累加。这里额外说明下@sun.misc.Contender注解的作用,它是Java8中引入用来解决缓存行伪共享问题的。什么是伪共享呢?简单说下,考虑到CPU与主存之间速度的巨大差异,在CPU中引入了L1、L2、L3多级缓存,缓存中的存储单位是缓存行,缓存行大小为2的整数次幂字节,32-256个字节不等,最常见的是64字节。因此,这将导致不足64字节的变量会共享同一个缓存行,其中一个变量失效会影响到同一个缓存行中的其他变量,致使性能下降,这就是伪共享问题。考虑到不同CPU的缓存行单位的差异性,Java8中便通过该注解将这种差异性屏蔽,根据实际缓存行大小来进行填充,使被修饰的变量能够独占一个缓存行。
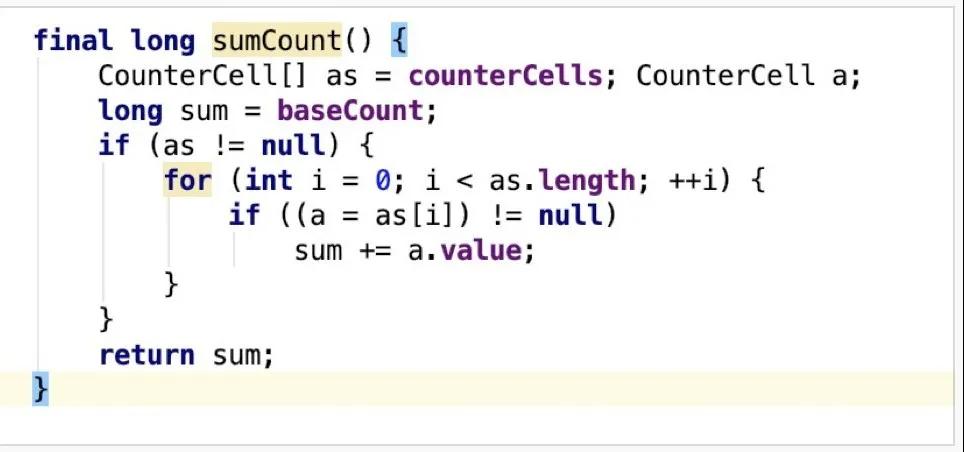
再来看下CounterCell是如何实现计数的,每当map中的容量有变化时会调用addCount进行计数,核心逻辑如下:
- 当counterCells不为空,或counterCells为空且对baseCount进行CAS操作失败时进入到后续计数处理逻辑,否则对baseCount进行CAS操作成功,直接返回。
- 后续计数处理逻辑中会调用核心计数方法fullAddCount,但需要满足以下4个条件中的任意一个:1、counterCells为空;2、counterCells的size为0;3、counterCells对应位置上的counterCell为空;4、CAS更新counterCells对应位置上的counterCell失败。这些条件背后的语义是,当前情况下,计数已经或曾经出现过并发冲突,需要优先借助于CounterCell来解决。若counterCells与对应位置上的元素已经初始化(条件4),则先尝试CAS进行更新,若失败则调用fullAddCount继续处理。若counterCells与对应位置上的元素未初始化完成(条件1、2、3),也要调用AddCount进行后续处理。
- 这里确定cell下标时采用了ThreadLocalRandom.getProbe()作为哈希值,这个方法返回的是当前Thread中threadLocalRandomProbe字段的值。而且当哈希值冲突时,还可以通过advanceProbe方法来更换哈希值。这与HashMap中的哈希值计算逻辑不同,因为HashMap中要保证同一个key进行多次哈希计算的哈希值相同并且能定位到对应的value,即便两个key的哈希值冲突也不能随便更换哈希值,只能采用链表或红黑树处理冲突。然而在计数场景,我们并不需要维护key-value的关系,只需要在counterCells中找到一个合适的位置放入计数cell,位置的差异对最终的求和结果是没有影响的,因此当冲突时可以基于随机策略更换一个哈希值来避免冲突。
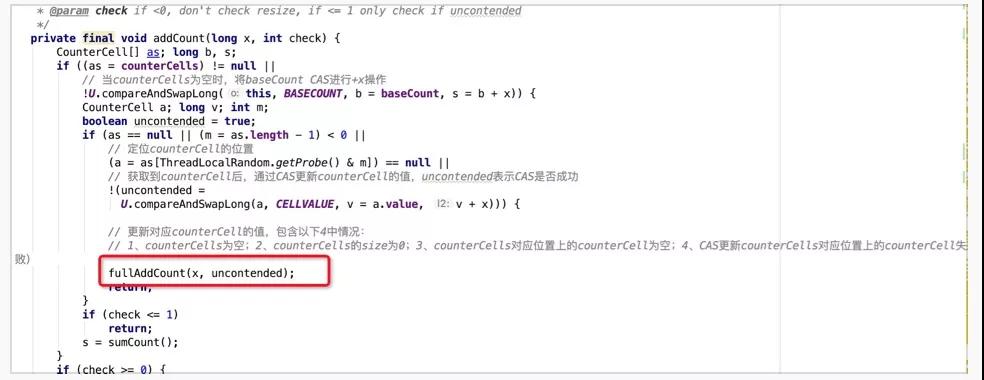
接着,我们来看下核心计算逻辑fullAddCount,代码还是比较多的,核心流程是通过一个死循环来实现的,循环体中包含了3个处理分支,为了方便讲解我将它们依次定义A、B、C。
- A:表示counterCells已经初始化完成,因此可以尝试更新或创建对应位置的CounterCell。
- B:表示counterCells未初始化完成,且无冲突(拿到cellsBusy锁),则加锁初始化counterCells,初始容量为2。
- C:表示counterCells未初始化完成,且有冲突(未能拿到cellsBusy锁),则CAS更新baseCount,baseCount在求和时也会被算入到最终结果中,这也相当于是一种兜底策略,既然counterCells正在被其他线程锁定,那当前线程也没必要再等待了,直接尝试使用baseCount进行累加。
其中,A分支中涉及到的操作又可以拆分为以下几点:
- a1:对应位置的CounterCell未创建,采用锁+Double Check的策略尝试创建CounterCell,失败的话则continue进行重试。这里面采用的锁是cellsBusy,它保证创建CounterCell并放入counterCells时一定是串行执行,避免重复创建,其实就是使用了DCL单例模式的策略。在CounterCells的创建、扩容中都需要使用该锁。
- a2:冲突检测,变量wasUncontended是调用方addCount中传入的,表示前置的CAS更新cell失败,有冲突,需要更换哈希值【a7】后继续重试。
- a3:对应位置的CounterCell不为空,直接CAS进行更新。
- a4:
- 冲突检测,当counterCells的引用值不等于当前线程对应的引用值时,说明有其他线程更改了counterCells的引用,出现冲突,则将collide设为false,下次迭代时可进行扩容。
- 容量限制,counterCells容量的最大值为大于等于NCPU(实际机器CPU核心的数量)的最小2的整数次幂,当达到容量限制时后面的扩容分支便永远不会执行。这里限制的意义在于,真实并发度是由CPU核心来决定,当counterCells容量与CPU核心数量相等时,理想情况下就算所有CPU核心在同时运行不同的计数线程时,都不应该出现冲突,每个线程选择各自的cell进行处理即可。如果出现冲突,一定是哈希值的问题,因此采取的措施是重新计算哈希值a7,而不是通过扩容来解决。时间换空间,避免不必要的存储空间浪费,非常赞的想法~
- a5:更新扩容标志位,下次迭代时将会进行扩容。
- a6:进行加锁扩容,每次扩容1倍。
- a7:更换哈希值。
CounterCell的设计很巧妙,它的背后其实就是JDK1.8中的LongAdder。核心思想是:在并发较低的场景下直接采用baseCount累加,否则结合counterCells,将不同的线程散列到不同的cell中进行计算,尽可能地确保访问资源的隔离,减少冲突。LongAdder相比较于AtomicLong中无脑CAS的策略,在高并发的场景下,能够减少CAS重试的次数,提高计算效率。
六 结语
以上可能只是Java Map源码中的冰山一角,但是基本包括了大部分的核心特性,涵盖了我们日常开发中的大部分场景。读源码跟读书一样,仿佛跨越了历史长河与作者进行近距离对话,揣摩他的心思,学习他的思想并加以传承。信息加工转化为知识并运用的过程是痛苦的,但是痛并快乐着。