












本文转载自公众号“读芯术”(ID:AI_Discovery)
想要使用人工智能咨询服务,就要先理解这六个人工智能术语,才能很大程度地利用好咨询内容。
1. 数据整理(Data Wrangling)
数据整理是指获取元数据,并将其转换为机器学习和人工智能可以识别的形式和架构的过程。为了获取客户所收集的数据,并用这些数据建立软件解决方案所需的任何模型,数据整理是任何人工智能顾问都会采取的前期步骤之一。
这个过程包含了许多步骤,包括数据输入、数据结构化、清理不良数据,以及处理数据来创建更多有效字段。这部分看起来简单,但可能是最重要的一部分,其间需要客户输入的数据来引导新顾问整理这些数据。
2.人工智能模型的数据插补
大部分数据集都存在缺值字段,这就让数据集显得稀疏零落。最快速的解决方法就是干脆从数据集中清除掉这种字段或者属性,但是通常来说这种解决方案非常低级,毕竟顾问起初能够获取的任何数据都是很宝贵的。
在这种情况下,大多数人工智能咨询公司会根据其余数据,通过数据加工技术赋予缺值最合理的数值。最通用的技术是均值插补法,即取该字段已知数据的均值,填充进空缺处。很多数据科学顾问都采用这种技术,这是一种在不影响当前数据架构的情况下填补空缺的好方法。
3.数据分区
许多采用人工智能和机器学习的模型会将数据进行分组处理,以便用于模型训练和测试。很多人工智能咨询公司会要求提供的数据,无论是文件大小还是行数都要符合一定的数量要求,从而确保有足够的数据用于分组。
有时候他们会同客户一起收集未来的数据作为测试集,将其添加到已建立的数据集中。在Scalr.ai,特别是在未来数据可以轻易地通过容易掌控的数据流来获取的情况下,我们会试着将两者结合起来。
4.监督学习
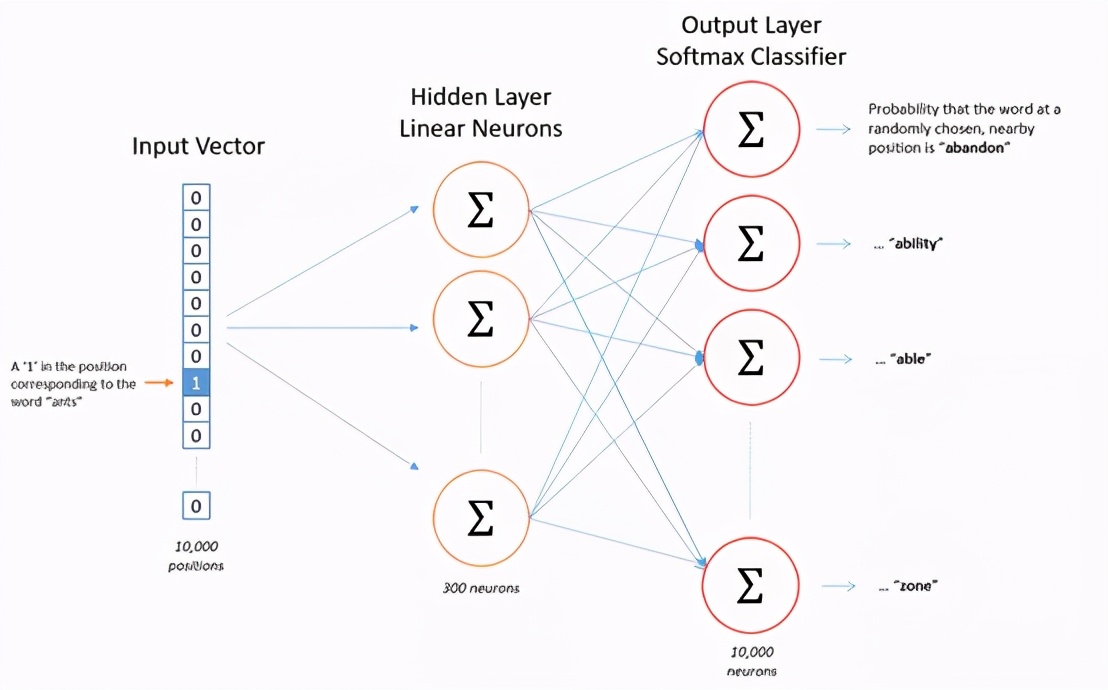
很多人工智能咨询服务都是使用机器学习或者数据科学,并且采用算法根据属性(又称为字段)和最终已知目标来查找二者之间的联系。大多数人工智能顾问在AI软件解决方案中使用这其中至少一种方法。
这种方法有一个典型例子,就是以房屋的平方英尺、层数和房门数作为字段的一种模型。目标变量是已知的房屋价值,运用这种模型,就能预测未来的房价。
5.无监督学习
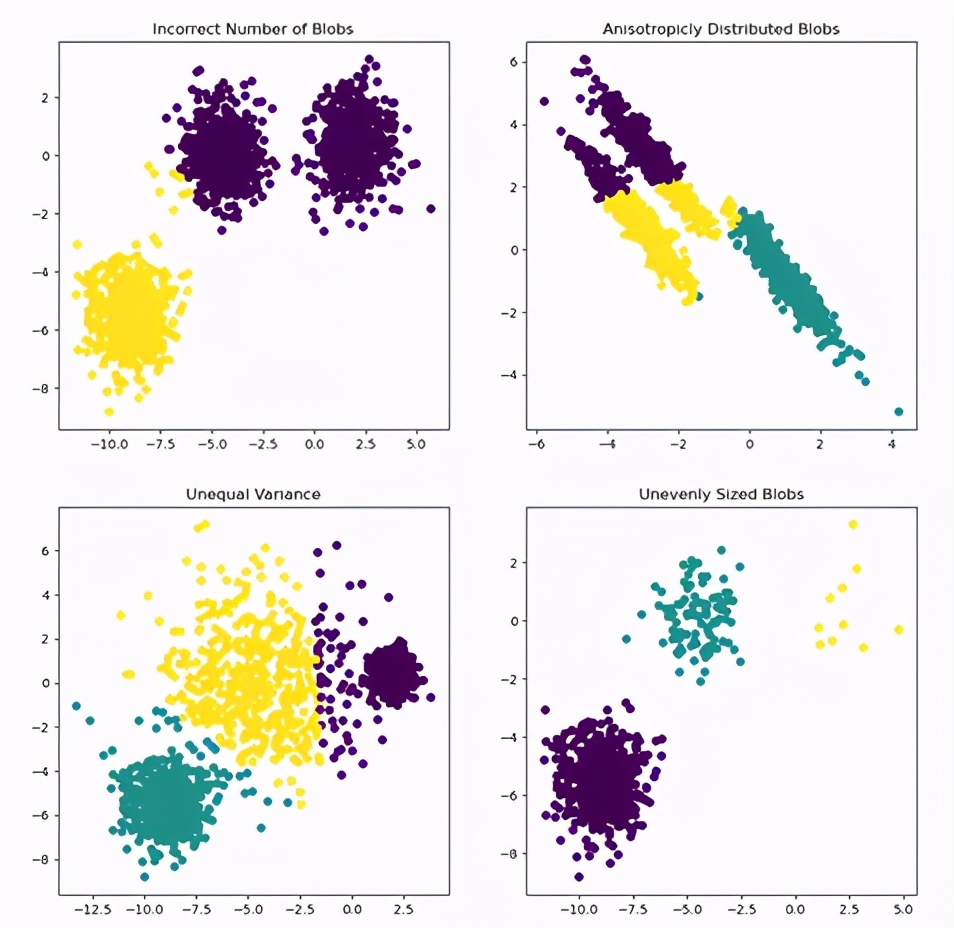
你估计能猜到了,这个过程中使用的是上面那组输入数据,但是没有使用目标变量,从而得到了不一样的结论。一般而言,这么做是因为目标变量未知,有关数据的总体信息未知,却要开始构建一些目标变量。
大多数人工智能咨询公司会使用这些算法查找出数据中的离群值,比如安全系统中超出范围的数据点,这些点有可能是危险信号。
6.模型的评估指标
最后,雇人来构建有效的模型和算法,得到想要的结果。人工智能顾问可以通过评估指标,掌握所完成工作的实际进展,并且根据出现的问题就如何调整解决做出决策。
大多数时候,你能听到的用来评估模型的术语有准确性、AUC和精度,但其实,评估软件中的模型的方法还有很多。
























