孩童时候,看哆啦A梦印象比较深的一集就是「翻译年糕」,那时候就希望自己能吃一块能读懂各种外语,次次考满分......如今来看,实现这个「小目标」有希望了!
赫尔辛基大学语言技术教授Jörg Tiedemann于2021年3月3号宣布,他已经发布了188种语言的5亿多个翻译句子。
这是一个自动翻译数据集,可用于数据增强翻译。
机器翻译(MT)属于计算机语言的范畴,其研究借由计算机程序将文字或演说从一种自然语言翻译成另一种自然语言。
研究机器翻译的研究人员经常依靠反向翻译来增加训练数据。
反向翻译是指,给定源语言句子x,目标语言句子y, 用训练好的目标语言到源语言的翻译模型得到伪句对(x’, y),加入到平行句对中一起训练。
这种训练方式也能起到去噪的作用,即不完美的机翻模型的输出包含了噪声。
在有噪声的情况下,训练(x', y)和(x, y)的翻译模型如果都能得到y的输出,则提升了泛化性能。
当更多的单语目标语言数据被翻译成源语言时,反向翻译使得深度学习系统 CUBITT 能够“超越人工翻译”。
反向翻译的有用性取决于目标语言数据的广泛可获得性,这对于使用人数少的小语种来说比较麻烦。
反向翻译对于检测机器翻译内容的方法也很关键,尤其是现在初创公司将人工智能驱动的「文本生成」技术逐渐商业化。
目前,Tiedemann的论文和数据集已经发布在了GitHub上。
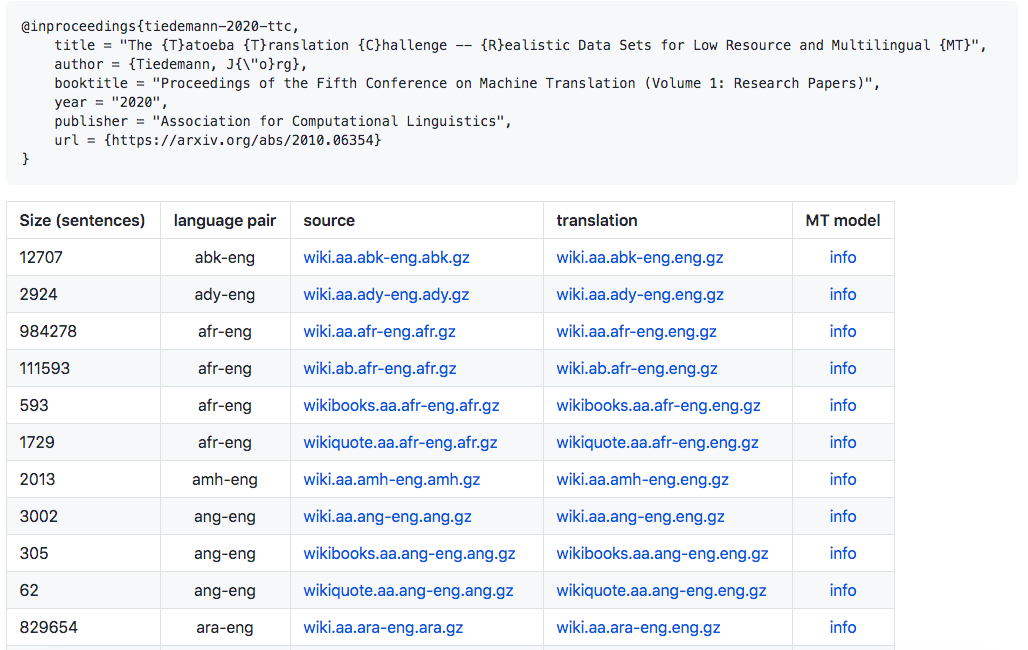
这并不是Tiedemann第一次试图通过MT为各种语言创造一个「地球村」。自2018年以来,Masakhane项目一直在专门针对NLP中代表不足的非洲语言收集语言数据并微调语言模型。

这个语言模型取得了不错的效果,这位德国在读博士就对这个模型给予了肯定。
Tatoeba 是一个庞大的句子和翻译数据库。Tatoeba 提供了一个工具,可以让你看到你所需要的单词在句子上下文中是如何使用的。
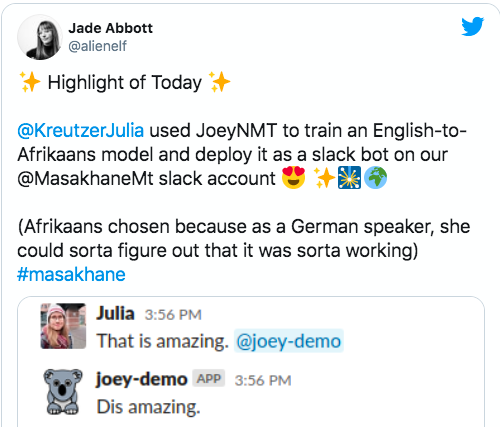
在2020年10月关于Tatoeba翻译挑战的相关论文中,Tiedemann写道,“我们的主要目标是促进开放翻译工具和模型的开发,从而更广泛地覆盖世界各种语言。”
有多宽泛?训练和测试数据涵盖500种语言和语言变体,以及大约3000种语言对。忍不住唱一句「你看这个数据集它又大又宽」。
根据 Tiedemann 的说法,还有很多工作要做。他在推特上写道: “无论如何,这不会是我将要发布的最后一套翻译版本”。“很快还会有更多语言从英语转向其它语言... ...”