













数据分析师的工作中最离不开的就是数据,业务中所有的情况都离不开数据这个载体,今天就来看下数据的都有哪些类型以及它们有什么特点。
数据是用某种计量尺度对事物测度的结果,采用不同的计量尺度会得到不同类型的数据,数据包括:各种数字、文字、图像、音频、视频及它们的组合等多种格式。
1.数据的分类
由于事物有简单和复杂的,如用户的外貌高矮等特征较直观,用户的偏好则不直观;有的差异可以用数量度量,有的则只能用分类度量。所以统计量就有定性、定量之分,对统计数据的属性、特征进行分类、标示和计算叫度量,分类见下图:
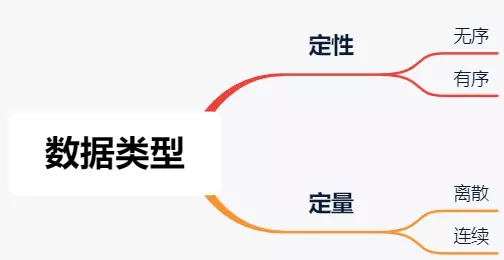
(1)定性数据,又叫分类数据。它用于确定数据的属性,不支持算术运算,只用于说明事物的品质,可能是文字或数字,可以细分为两类:
①无序数据。如:人的性别可以分为:男,女,未知3类,也可以把它们记为0,1,2;学生的成绩可以分为:及格,不及格……为了便于理解,一般可按惯例来定义,也可以按具体的业务需求等。该类数据的用数字表示时仅表示不同类别的品质是什么,而不表示量的顺序或大小,该类数据尺度的数学特征是“=”或“≠”。
②顺序数据,无序分类数据不要求有顺序,顺序数据是有序的。如:空气污染可以分为:优,良,轻度污染,中度污染,重度污染,其中后面一级都比前面一级的程度更严重,也可以用1,2,3,4,5来标识这几种分类;学生的成绩也可以分为:优秀,良好,及格,不及格,后面一级的数据也都比前面的更差。此时的尺度不能表明级别的量,仅能表明其等级差异,该类数据尺度的数学特征是“>”或“<”。
(2)定量数据,又称为数值型数据,用于说明事物的数量,形式是数字,也可以分为两类,主要按数值是否连续划分:
①离散型数据,离散型是通过计数得到的,增长量不固定,比如:北京市上月的空气质量有20天是优,本月共10天优;北京市去年净流出200万人,今年净流出100万人。它不仅能对事物区分不同的类型,还能对其排序,做数学运算。
②连续型数据,这是一直叠加上去的,增长量可以划分为固定的单位。如:人的年龄是1岁,1.2岁,1.5岁,2岁......人的身高1.5米,1.51,1.52......
不管是什么类型的数据,定义数据时,有逻辑地划分、表达更易让人理解、方便计算。
定性与定量数据的关系:定性数据与定量数据相互补充,定性是定量的前提、依据,定量使定性更加具体、准确,结合使用才能通过比较来分析、说明问题。这四类数据的层次一类比一类高。
因不同类型的数据采用的处理、分析的统计方法不同,所以区分度量的层次、数据的类型很重要。如,对无序数据,通常计算出各组的频数或频率,计算其众数和异众比率,进行列联表分析和x2检验等;对顺序数据,可以通过其中位数和四分位差,从而估计样本数据的总体;对离散数据还可以用更多的统计方法进行处理,如计算各种统计量、进行参数估计和检验等。
适用于低层次测量数据的统计方法,也适用于较高层次的测量数据,因为后者具有前者的数学特性,但前者不具备后者的特性,所以反之不成立。如:描述数据的集中趋势时,对无序数据通常计算众数,对顺序数据通常是计算中位数,但对连续、离散类的定量数据也可以计算众数和中位数。反之,对于离散和连续数据可以计算平均数,但对于无序数据和顺序数据则不能计算平均数。理解这一点,则有助于分析时选择合适的统计分析方法。
2.数据的质量
数据质量的好坏甚至能决定我们分析的成功与否。评价数据的质量主要从内容质量、表述质量、约束标准三方面着手。

内容质量是数据最基本的特征,包括相关性、准确性、及时性,这是数据质量的基本特征,缺少其中一个,数据就失去了转化为信息的作用。
①相关性
相关性指数据是否正是用户感兴趣的统计数据,它反映了数据满足需求的程度,相关性与可用数据是否是用户最关心的主题有关。由于对相关性的评价是主观的,会随用户需求目标的改变而改变,所以要平衡不同用户的需求目标,在给定的资源条件限制下,尽可能满足大部分用户的大部分需求。
②准确性
准确性指观测值或估计值与未知的真实值之间的距离(接近程度),通常用统计误差来衡量,它是数据质量的基础和核心。一般地,误差分为系统误差和随机误差。因可能会受到成本、环境等各种限制,完全准确几乎是不可能的。所以只要是误差已降低到用户可以接受的地步即可。
③及时性
与用户需求相关且准确的数据如果没有在用户做出决策之前传递给他,那么该数据对用户来说就是没用的。所以,及时性也是统计数据能否满足用户需求的重要特征。如果要统计的现象变化较快,则对该类统计数据的及时性要求高;如果该现象变化较缓慢,则对及时性要求不高。
(2)表述质量
仅考虑数据内容的质量是不够的,多个人一起做需求时,要想被人看到、看懂,必然离不开描述需求相关的多个数据,这时就要考虑表述的质量问题。如:单个数据的内容是正确的,但表述不清晰、不充分,就会影响整套数据的质量,甚至引起误解。统计数据的表述质量包括可比性、可衔接性和可理解性,这些都是我们做需求、对外提供数据或分析报告时需要注意的点。
①可比性
可比性指同一项目的统计数据在时间上、空间上的可比程度。这要求统计的概念和方法要相对稳定,使用统一的统计制度方法和分类标准,确保统计数据的口径范围、计算方法一致,可比较。
②可衔接性
可衔接性指同一统计机构内部不同项目、不同机构及与国际组织间统计数据的衔接程度。这要求所有专业统计项目在统一的统计框架体系、 分类标准下,按统一的方法统计、调查、加工整理、使用统一的方法和程序,同时采用国际统计标准,如国际标准时间等。
③可理解性
可理解性指统计数据便于用户正确理解、使用的程度。统计数据是提供给用户使用的,如果用户看不懂数据、分析报告,也就谈不上使用数据。为了恰当地使用从统计机构得到的数据,用户必须了解所获得数据的性质。这就要求统计机构在提供统计数据时附带提供对数据的补充说明。如:提供隐含在有关概念下面的说明、使用到的分类方法、数据收集和加工过程中使用的方法及统计机构自身对数据质量的评价等。
(3)约束标准
在实现统计数据目标的过程中,除了注意统计数据的内容质量和表述质量这两方面外,还需注意以下两项约束标准,这体现了数据的质量特征。
①可取得性
可取得性是指用户获取数据的便利程度。对于有用的数据,用户必然要考虑:能得到哪些数据,如何得到这些数据。因此,统计数据必须以一种用户方便使用且能够负担的形式提供给用户。这要求提供统计数据时,必须列明用户从统计机构可以取得的统计数据内容,同时方便用户获取。
②有效性
有效性指利用统计数据所产生的效益要大于提供该数据的成本。如果相反,则提供这种数据对提供方和使用方来说都是不值得的,这要求在统计数据的其他质量不受大的影响的前提下,尽可能降低统计数据的生产费用,提高效率。



















