本文转载自微信公众号「新钛云服」,作者祝祥 翻译。转载本文请联系新钛云服公众号。
Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。
RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。同时Ceph也为Kubernetns提供块,文件,对象存储。
当在各种生产场景中使用Ceph作为网络存储时,我们可能会面临着很多的生产场景。这里有一些案例:
- 在新集群中部分使用旧的服务器的情况下,将数据迁移到新的Ceph新的实例节点中;
- 解决Ceph中磁盘空间分配的问题。
为了处理这些问题,我们需要在保持数据完整的同时正确删除OSD。在海量数据的情况下,这一点尤其重要。这就是我们将在本文中介绍的内容。
下述方法适用于各种版本的Ceph (除非特别说明)。另外,我们将考虑到大量数据可以存储在Ceph中这一场景,因此我们将把某些步骤分解成较小的步骤——以防止数据丢失和其他问题。
关于OSD的几句话
由于本文所涉及的三种场景中有两种是与OSD(对象存储守护程序)有关,因此在深入探讨之前,我们先简单讨论一下OSD及其重要性。
首先,应该注意,整个Ceph集群由一组OSD组成。它们越多,Ceph中的可用数据量就越大。因此,OSD的主要目的是跨群集节点存储对象数据,并提供对其的网络访问(用于读取,写入和其他查询)。
通过在不同OSD之间复制对象,可以将复制参数设置为同一级别。这也是您可能会遇到问题的地方(我们将在本文后面提供解决方案)。
案例1:优雅地从Ceph集群中移除OSD
当需要从群集中移除OSD的时候,这很可能是集群硬件变更的需求(例如,将一台服务器替换为另一台服务器)。这也正是我们当前所遇到的场景,同时也是这一实际场景触发我们写了这篇文章。
因此,我们的最终目标是删除服务器上的所有OSD和监视器,以便可以将服务器安全下架。
为了方便起见并避免在执行命令时选择错误的OSD,让我们定义一个单独的变量,其中包含所需OSD的编号。我们将其称为${ID}。从现在开始,此变量将替换我们正在使用的OSD的数量。
首先,让我们看一下OSD映射关系:
- root@hv-1 ~ # ceph osd tree
- ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- -1 0.46857 root default
- -3 0.15619 host hv-1
- -5 0.15619 host hv-2
- 1 ssd 0.15619 osd.1 up 1.00000 1.00000
- -7 0.15619 host hv-3
- 2 ssd 0.15619 osd.2 up 1.00000 1.00000
为了使OSD安全脱离群集,我们必须将reweight缓慢降低到零。这样,我们就可以通过重新均衡的方式,将当前需要移除的OSD数据迁移到其他OSD中。
为此,请运行以下命令:
- ceph osd reweight osd.${ID} 0.98
- ceph osd reweight osd.${ID} 0.88
- ceph osd reweight osd.${ID} 0.78
…依此类推,直到权重为零。
但是,如果使用norebalance呢?
另外,还有一个解决方案是使用norebalance+backfill。首先,禁用重新均衡:
- ceph osd set norebalance
现在,您必须将新的OSD添加到CRUSH MAP中,并将旧OSD的权重设置为0。对于要删除和添加的OSD,将主要亲和力设置为0:
- ceph osd primary-affinity osd.$OLD 0
- ceph osd primary-affinity osd.$NEW 0
然后减小backfill到1并取消norebalance:
- ceph tell osd.* injectargs --osd_max_backfill=1
- ceph osd unset norebalance
之后,Ceph集群将开始数据迁移。
注意:这个解决方案是非常可行的,但是你必须考虑到具体的情况与需求。当我们不想在任何OSD Down时造成过多的网络负载时,我们就可以使用norebalance。
`osd_max_backfill`允许您限制再均衡速度。因此,重新均衡将减慢速度从而降低网络负载。
遵循的步骤
我们必须要逐步重新均衡从而避免数据丢失。如果OSD包含大量数据,则更要如此。如果要确保在运行reweight命令后是否一切正常,可以运行ceph -s查看集群当前的健康状态。
此外,您可以在单独的终端窗口中运行ceph -w以实时监视数据迁移的过程。
清空OSD之后,您可以开始按照标准操作来删除它。为此,将选定的OSD设置为以下down状态:
- ceph osd down osd.${ID}
现在是时将OSD移出群集了:
- ceph osd out osd.${ID}
停止OSD并卸载其卷:
- systemctl stop ceph-osd@${ID}
- umount /var/lib/ceph/osd/ceph-${ID}
从CRUSH MAP中删除OSD:
- ceph osd crush remove osd.${ID}
删除OSD身份验证密钥:
- ceph auth del osd.${ID}
最后,删除OSD:
- ceph osd rm osd.${ID}
注意:对于Luminous(及更高版本)的Ceph版本,可以将上述步骤简化为:
- ceph osd out osd.${ID}
- ceph osd purge osd.${ID}
现在,如果您运行ceph osd tree命令,您应该看到服务器的OSD已经被移除:
- root@hv-1 ~ # ceph osd tree
- ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- -1 0.46857 root default
- -3 0.15619 host hv-1
- -5 0.15619 host hv-2
- -7 0.15619 host hv-3
- 2 ssd 0.15619 osd.2 up 1.00000 1.00000
请注意,您的Ceph群集状态将变为HEALTH_WARN,OSD的数量以及可用磁盘空间的数量将减少。
下面,我们将提供完全停止服务器并将其从Ceph中删除所需的步骤。我们必须提醒您,在停止服务器之前,必须移除该服务器上的所有OSD。
从服务器中移除所有OSD之后,可以通过运行以下命令从CRUSH MAP中删除服务器hv-2:
- ceph osd crush rm hv-2
通过在另一台服务器(即 hv-1)上运行以下命令,从服务器hv-2上删除监视器:
- ceph-deploy mon destroy hv-2
之后,您可以停止服务器并继续执行其他操作(例如重新部署等)。
案例2:在现有的Ceph集群中分配磁盘空间
现在,让我们从第二个案例开始,详细讲讲放置组PG(https://docs.ceph.com/docs/mimic/rados/operations/placement-groups/)。PG(Placement Group)是 Ceph 中非常重要的概念,它可以看成是一致性哈希中的虚拟节点,维护了一部分数据并且是数据迁移和改变的最小单位。
它在 Ceph 中承担着非常重要的角色,在一个 Pool 中存在一定数量的 PG (可动态增减),这些 PG 会被分布在多个 OSD ,分布规则可以通过 CRUSH RULE 来定义。
Monitor 维护了每个Pool中的所有 PG 信息,比如当副本数是3时,这个 PG 会分布在3个 OSD 中,其中有一个 OSD 角色会是 Primary ,另外两个 OSD 的角色会是 Replicated。
Primary PG负责该 PG 的对象写操作,读操作可以从 Replicated PG获得。而 OSD 则只是 PG 的载体,每个 OSD 都会有一部分 PG 角色是 Primary,另一部分是 Replicated,当 OSD 发生故障时(意外 crash 或者存储设备损坏),Monitor 会将PG的角色为 Replicated的 OSD 提升为 Primary PG,而这个故障 OSD 上所有的 PG 都会处于 Degraded 状态。
然后等待管理员的下一步操作, 如果原来所有Replicated的 OSD 无法启动, OSD 会被踢出集群,这些 PG 会被 Monitor 根据 OSD 的情况分配到新的 OSD 上。
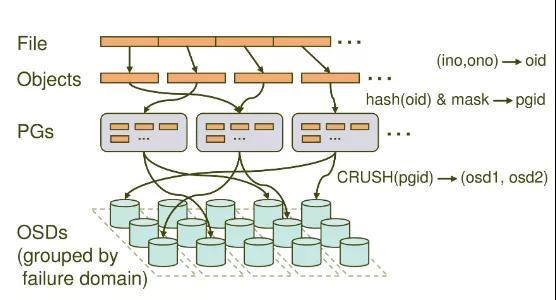
从上面可以看出,Ceph中的放置组主要聚合Ceph对象并在OSD中执行数据复制。Ceph文档(https://docs.ceph.com/docs/mimic/rados/operations/placement-groups/#choosing-the-number-of-placement-groups)中提供了如何选择PG数量的公式。
您还可以在其中找到有关如何计算所需PG数量的案例。
Ceph的存储池之间的OSD和PG数量不一致是Ceph运行过程中最常见的问题之一。总体而言,正确数量的PG是Ceph集群健康运行的必要条件。下面,我们将看看不正确的PG数量配置会发生什么?
通常,PG的数量设置与以下两个问题密切相关:
PG数量太少会导致均衡大数据块的问题。
另一方面,数量过多的PG则会导致性能问题。
实际上,还有另一个更危险的问题:其中一个OSD中的数据溢出。其原因是,Ceph在估算可写入池中的理论数据量时依赖于OSD中的可用数据量。您可以通过命令ceph df 查看每个存储池的MAX AVAIL字段,从而获知每个存储池的最大可用量。如果出现一个OSD容量不足,则在所有OSD之间正确分配数据之前,您将无法写入更多数据。
事实上在配置Ceph集群时可以解决以上问题。Ceph PGCalc(https://ceph.io/pgcalc/)是推荐使用的工具之一。它可以帮助您配置正确的PG。有一点需要特别注意,修复PG的常见场景之一是您很可能需要减少PG的数量。但是,较早的Ceph版本并不支持此功能(从Nautilus版本开始可用)。
好的,让我们想象一下这种场景:由于某一个OSD空间不足(如HEALTH_WARN: 1 near full osd),集群处于HEALTH_WARN状态。下面介绍了处理这种情况的方法。
首先,您需要在可用的OSD之间重新分配数据。当从集群中移除OSD时,在案例1中我们做了同样的事情。唯一的区别是,现在我们需要稍微减少weight权重。例如,降至0.95:
- ceph osd reweight osd.${ID} 0.95
这样,您可以释放OSD中的磁盘空间并修复ceph运行状况错误。但是,正如之前提到的,此问题主要是由于Ceph的初始配置不正确引起的。最佳的做法是重新配置群集,以防止以后再次发生此类错误。
在我们的场景中,所有这些都归结为以下的两种原因:
其中一个池的replication_count过高,
其中一个池中的PG数量过多,而另一个池中的PG数量不足。
下面,让我们使用PGCalc计算器。它非常简单,在指定了所有必需的参数之后,我们得到以下建议:
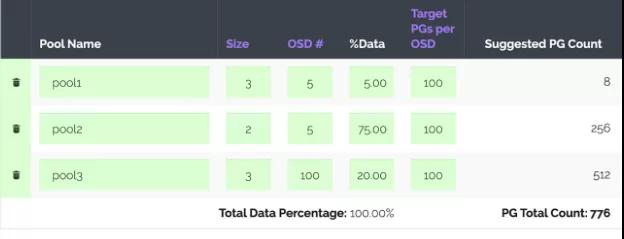
注意:PGCalc能够生成一组命令,这些命令可以快速创建存储池,这对那些从头开始安装与配置Ceph集群的人可能会是一个非常有用的功能。
最后一栏Suggested PG Count输出推荐的PG数量值。在我们的场景中,您还应该注意第二列(Size),该列指定每个池的副本数(因为我们已经修改了副本数)。
因此,首先,我们需要更改存储池的副本,我们可以通过减小replication_size参数来释放磁盘空间。在命令处理过程中,您将看到可用磁盘空间会增加:
- ceph osd pool $pool_name set $replication_size
命令运行结束后,我们还必须修改pg_num和pgp_num参数,如下所示:
- ceph osd pool set $pool_name pg_num $pg_number
- ceph osd pool set $pool_name pgp_num $pg_number
注意:我们必须依次更改每个池中的PG数量,直到“n-number of pgs degraded”和“Degraded data redundancy”告警消失。
您可以使用ceph health detail和ceph -s命令检查一切是否顺利。
案例3:将VM从LVM迁移到Ceph RBD
Ceph的很多问题都是出现在虚拟化平台的使用上。在这样的存储使用场景中有充足的空间也是非常必要的。另外一种常见的情况是服务器使用的是本地存储的VM。您想扩展它的磁盘,但是也没有足够的可用空间。
有很多种方法可以解决此类问题。例如,您可以将虚拟机迁移到另外一台物理服务器(如果有匹配条件的物理服务器节点),或在物理服务器上添加新的物理磁盘。但是,有时候,这些方法都不可行。在这种情况下,从LVM到Ceph的迁移可能是一个比较好的解决方案。通过这种方法,不需要将本地存储从一个虚拟化节点迁移到另一个虚拟化节点,因此我们简化了跨节点迁移。但是,有一个注意点:您必须停止VM,直到迁移完成。
我们的后续步骤是基于这个指南(http://blog.easter-eggs.org/index.php/post/2013/09/27/Libvirt-Migrating-from-on-disk-raw-images-to-RBD-storage)。我们已经成功测试了此处提供的解决方案。顺便说一句,它还描述了无停机迁移的方式。但是,由于我们不要求使用此功能,因此我们尚未对其进行验证。
那么实际步骤是什么?在我们的示例中,我们使用virsh命令。首先,确保目标Ceph池已连接到libvirt:
- virsh pool-dumpxml $ceph_pool
存储池的描述必须包含所有必需的信息和凭据才能连接到Ceph。
下一步涉及将LVM镜像转换为Ceph RBD。转换过程的持续时间主要取决于镜像的大小:
- qemu-img convert -p -O rbd /dev/main/$vm_image_name
- rbd:$ceph_pool/$vm_image_name
转换完成后,将仍然保留LVM镜像。如果将VM迁移到RBD失败,这将派上用场,而您必须回滚所做的更改。为了能够快速回滚更改,让我们备份VM的配置文件:
- virsh dumpxml $vm_name > $vm_name.xml
- cp $vm_name.xml $vm_name_backup.xml
编辑原始的vm_name.xml文件。查找磁盘的描述(以<disk type='file' device='disk'>开头和以</disk>结尾),并按如下所示进行修改:
- <disk type='network' device='disk'>
- <driver name='qemu'/>
- <auth username='libvirt'>
- <secret type='ceph' uuid='sec-ret-uu-id'/>
- </auth>
- <source protocol='rbd' name='$ceph_pool/$vm_image_name>
- <host name='10.0.0.1' port='6789'/>
- <host name='10.0.0.2' port='6789'/>
- </source>
- <target dev='vda' bus='virtio'/>
- <alias name='virtio-disk0'/>
- <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/>
- </disk>
仔细查看细节:
- source协议字段中包含Ceph的RBD存储池的路径。
- secret字段包含ceph密码的类型以及UUID。您可以使用以下virsh secret-list命令找出UUID 。
- host字段包含Ceph监视器的地址。
编辑完配置文件并将LVM成功转换为RBD后,您可以应用修改后的xml文件并启动虚拟机:
- virsh define $vm_name.xml
- virsh start $vm_name
现在该检查虚拟机是否正常运行了。为此,您可以通过SSH或使用virsh直接连接到物理节点。
如果VM正常运行,并且没有任何其他问题的提示,则可以删除LVM镜像,因为不再需要它:
- lvremove main/$vm_image_name
结论:在生产环境中,我们遇到了以上这些问题。我们希望我们的解决方式能够帮助到您。当然,在Ceph的运维过程中所遇到的问题不仅仅是这些,还可能会更多,但只要遵循标准化操作,问题最终都能被圆满解决。