













这一篇文章的内容是在 Week05: 评论系统架构设计 当中的可用性设计当中提到的,但是这个属于 Go 官方扩展同步包 (golang.org/x/sync/singleflight) 的一个库,为了让内容统一就放到这里了。
SingleFlight
为什么我们需要 SingleFlight(使用场景)?
一般情况下我们在写一写对外的服务的时候都会有一层 cache 作为缓存,用来减少底层数据库的压力,但是在遇到例如 redis 抖动或者其他情况可能会导致大量的 cache miss 出现。
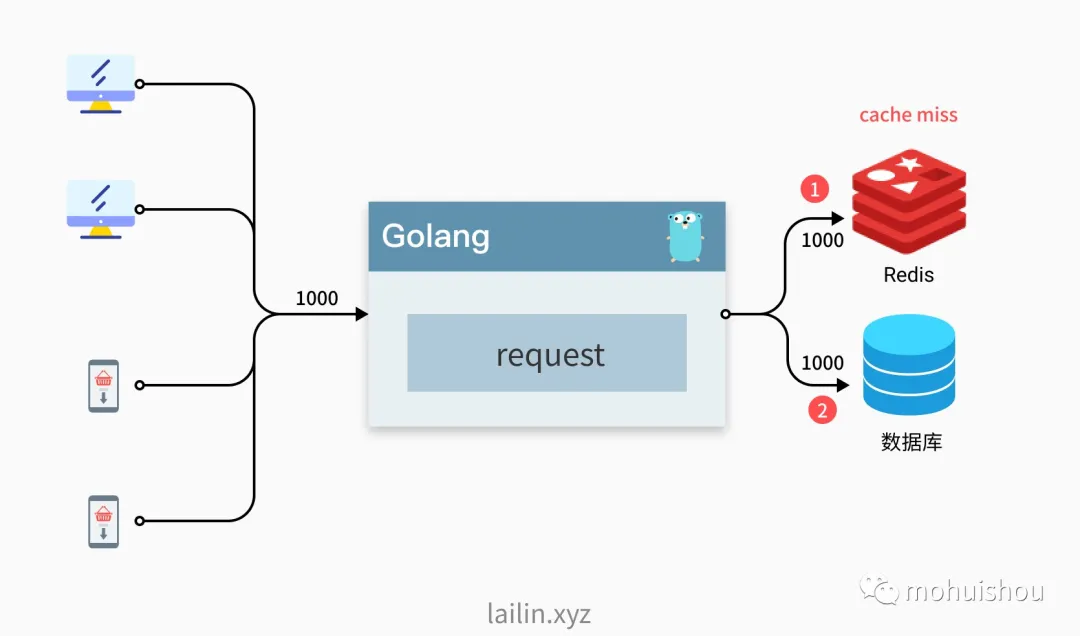
如下图所示,可能存在来自桌面端和移动端的用户有 1000 的并发请求,他们都访问的获取文章列表的接口,获取前 20 条信息,如果这个时候我们服务直接去访问 redis 出现 cache miss 那么我们就会去请求 1000 次数据库,这时可能会给数据库带来较大的压力(这里的 1000 只是一个例子,实际上可能远大于这个值)导致我们的服务异常或者超时。
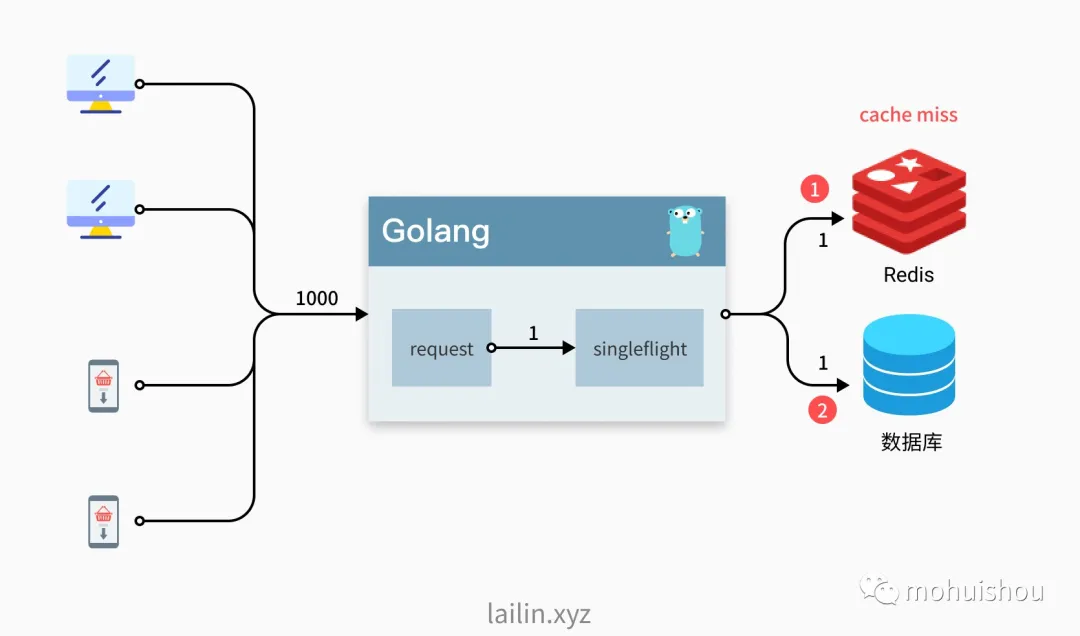
这时候就可以使用 singleflight 库了,直译过来就是单飞,这个库的主要作用就是将一组相同的请求合并成一个请求,实际上只会去请求一次,然后对所有的请求返回相同的结果。如下图所示,使用 singleflight 之后,我们在一个请求的时间周期内实际上只会向底层的数据库发起一次请求大大减少对数据库的压力。
SingleFlight 包怎么用(使用教程)?
函数签名
主要是一个 Group 结构体,三个方法,具体信息看下方注释
- type Group
- // Do 执行函数, 对同一个 key 多次调用的时候,在第一次调用没有执行完的时候
- // 只会执行一次 fn 其他的调用会阻塞住等待这次调用返回
- // v, err 是传入的 fn 的返回值
- // shared 表示是否真正执行了 fn 返回的结果,还是返回的共享的结果
- func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool)
- // DoChan 和 Do 类似,只是 DoChan 返回一个 channel,也就是同步与异步的区别
- func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result
- // Forget 用于通知 Group 删除某个 key 这样后面继续这个 key 的调用的时候就不会在阻塞等待了
- func (g *Group) Forget(key string)
使用示例
接下来我们看看实际上我们是怎么使用的,先使用一个普通的例子,这时一个获取文章详情的函数,我们在函数里面使用一个 count 模拟不同并发下的耗时的不同,并发越多请求耗时越多
- func getArticle(id int) (article string, err error) {
- // 假设这里会对数据库进行调用, 模拟不同并发下耗时不同
- atomic.AddInt32(&count, 1)
- time.Sleep(time.Duration(count) * time.Millisecond)
- return fmt.Sprintf("article: %d", id), nil
- }
我们使用 singleflight 的时候就只需要 new(singleflight.Group) 然后调用一下相对应的 Do 方法就可了,是不是很简单
- func singleflightGetArticle(sg *singleflight.Group, id int) (string, error) {
- v, err, _ := sg.Do(fmt.Sprintf("%d", id), func() (interface{}, error) {
- return getArticle(id)
- })
- return v.(string), err
- }
效果测试
光说不练假把式,写一个简单的测试代码,下面我们启动 1000 个 Goroutine 去并发调用这两个方法
- var count int32
- func main() {
- time.AfterFunc(1*time.Second, func() {
- atomic.AddInt32(&count, -count)
- })
- var (
- wg sync.WaitGroup
- now = time.Now()
- n = 1000
- sg = &singleflight.Group{}
- )
- for i := 0; i < n; i++ {
- wg.Add(1)
- go func() {
- // res, _ := singleflightGetArticle(sg, 1)
- res, _ := getArticle(1)
- if res != "article: 1" {
- panic("err")
- }
- wg.Done()
- }()
- }
- wg.Wait()
- fmt.Printf("同时发起 %d 次请求,耗时: %s", n, time.Since(now))
- }
可以看到这个是调用 getArticle 方法的耗时,花费了 1s 多
- # 直接调用的请求耗时
- ❯ go run ./1.go
- 同时发起 1000 次请求,耗时: 1.0022831s
而使用 singleflight 的方法,花费了不到 3ms
- # 使用 singleflight 的请求耗时
- ❯ go run ./1.go
- 同时发起 1000 次请求,耗时: 2.5119ms
当然每个库都有自己的使用场景,软件领域里面没有银弹,如果我们用的不太好的话甚至可能会得到适得其反的效果,而多看源码不仅能够帮助我们进行学习,也可以尽量少踩坑
它是如何实现的(源码分析)?
本文基于 [https://pkg.go.dev/golang.org/x/sync@v0.0.0-20210220032951-036812b2e83c/singleflight](https://pkg.go.dev/golang.org/x/sync@v0.0.0-20210220032951-036812b2e83c/singleflight) 进行分析,这个库的实现很简单,但是功能很强大,还有一些小技巧,非常值得学习
Group
- type Group struct {
- mu sync.Mutex // protects m
- m map[string]*call // lazily initialized
- }
Group 结构体由一个互斥锁和一个 map 组成,可以看到注释 map 是懒加载的,所以 Group 只要声明就可以使用,不用进行额外的初始化零值就可以直接使用。call 保存了当前调用对应的信息,map 的键就是我们调用 Do 方法传入的 key
- type call struct {
- wg sync.WaitGroup
- // 函数的返回值,在 wg 返回前只会写入一次
- val interface{}
- err error
- // 使用调用了 Forgot 方法
- forgotten bool
- // 统计调用次数以及返回的 channel
- dups int
- chans []chan<- Result
- }
Do
- func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
- g.mu.Lock()
- // 前面提到的懒加载
- if g.m == nil {
- g.m = make(map[string]*call)
- }
- // 会先去看 key 是否已经存在
- if c, ok := g.m[key]; ok {
- // 如果存在就会解锁
- c.dups++
- g.mu.Unlock()
- // 然后等待 WaitGroup 执行完毕,只要一执行完,所有的 wait 都会被唤醒
- c.wg.Wait()
- // 这里区分 panic 错误和 runtime 的错误,避免出现死锁,后面可以看到为什么这么做
- if e, ok := c.err.(*panicError); ok {
- panic(e)
- } else if c.err == errGoexit {
- runtime.Goexit()
- }
- return c.val, c.err, true
- }
- // 如果我们没有找到这个 key 就 new call
- c := new(call)
- // 然后调用 waitgroup 这里只有第一次调用会 add 1,其他的都会调用 wait 阻塞掉
- // 所以这要这次调用返回,所有阻塞的调用都会被唤醒
- c.wg.Add(1)
- g.m[key] = c
- g.mu.Unlock()
- // 然后我们调用 doCall 去执行
- g.doCall(c, key, fn)
- return c.val, c.err, c.dups > 0
- }
doCall
这个方法的实现有点意思,使用了两个 defer 巧妙的将 runtime 的错误和我们传入 function 的 panic 区别开来避免了由于传入的 function panic 导致的死锁
- func (g *Group) doCall(c *call, key string, fn func() (interface{}, error)) {
- normalReturn := false
- recovered := false
- // 第一个 defer 检查 runtime 错误
- defer func() {
- }()
- // 使用一个匿名函数来执行
- func() {
- defer func() {
- if !normalReturn {
- // 如果 panic 了我们就 recover 掉,然后 new 一个 panic 的错误
- // 后面在上层重新 panic
- if r := recover(); r != nil {
- c.err = newPanicError(r)
- }
- }
- }()
- c.val, c.err = fn()
- // 如果 fn 没有 panic 就会执行到这一步,如果 panic 了就不会执行到这一步
- // 所以可以通过这个变量来判断是否 panic 了
- normalReturn = true
- }()
- // 如果 normalReturn 为 false 就表示,我们的 fn panic 了
- // 如果执行到了这一步,也说明我们的 fn recover 住了,不是直接 runtime exit
- if !normalReturn {
- recovered = true
- }
- }
再来看看第一个 defer 中的代码
- defer func() {
- // 如果既没有正常执行完毕,又没有 recover 那就说明需要直接退出了
- if !normalReturn && !recovered {
- c.err = errGoexit
- }
- c.wg.Done()
- g.mu.Lock()
- defer g.mu.Unlock()
- // 如果已经 forgot 过了,就不要重复删除这个 key 了
- if !c.forgotten {
- delete(g.m, key)
- }
- if e, ok := c.err.(*panicError); ok {
- // 如果返回的是 panic 错误,为了避免 channel 死锁,我们需要确保这个 panic 无法被恢复
- if len(c.chans) > 0 {
- go panic(e)
- select {} // Keep this goroutine around so that it will appear in the crash dump.
- } else {
- panic(e)
- }
- } else if c.err == errGoexit {
- // 已经准备退出了,也就不用做其他操作了
- } else {
- // 正常情况下向 channel 写入数据
- for _, ch := range c.chans {
- ch <- Result{c.val, c.err, c.dups > 0}
- }
- }
- }()
DoChan
Do chan 和 Do 类似,其实就是一个是同步等待,一个是异步返回,主要实现上就是,如果调用 DoChan 会给 call.chans 添加一个 channel 这样等第一次调用执行完毕之后就会循环向这些 channel 写入数据
- func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result {
- ch := make(chan Result, 1)
- g.mu.Lock()
- if g.m == nil {
- g.m = make(map[string]*call)
- }
- if c, ok := g.m[key]; ok {
- c.dups++
- c.chans = append(c.chans, ch)
- g.mu.Unlock()
- return ch
- }
- c := &call{chans: []chan<- Result{ch}}
- c.wg.Add(1)
- g.m[key] = c
- g.mu.Unlock()
- go g.doCall(c, key, fn)
- return ch
- }
Forget
forget 用于手动释放某个 key 下次调用就不会阻塞等待了
- func (g *Group) Forget(key string) {
- g.mu.Lock()
- if c, ok := g.m[key]; ok {
- c.forgotten = true
- }
- delete(g.m, key)
- g.mu.Unlock()
- }
有哪些注意事项(避坑指南)?
单飞虽好但也不要滥用哦,还是存在一些坑的
1. 一个阻塞,全员等待
使用 singleflight 我们比较常见的是直接使用 Do 方法,但是这个极端情况下会导致整个程序 hang 住,如果我们的代码出点问题,有一个调用 hang 住了,那么会导致所有的请求都 hang 住
还是之前的例子,我们加一个 select 模拟阻塞
- func singleflightGetArticle(sg *singleflight.Group, id int) (string, error) {
- v, err, _ := sg.Do(fmt.Sprintf("%d", id), func() (interface{}, error) {
- // 模拟出现问题,hang 住
- select {}
- return getArticle(id)
- })
- return v.(string), err
- }
执行就会发现死锁了
- fatal error: all goroutines are asleep - deadlock!
- goroutine 1 [select (no cases)]:
这时候我们可以使用 DoChan 结合 select 做超时控制
- func singleflightGetArticle(ctx context.Context, sg *singleflight.Group, id int) (string, error) {
- result := sg.DoChan(fmt.Sprintf("%d", id), func() (interface{}, error) {
- // 模拟出现问题,hang 住
- select {}
- return getArticle(id)
- })
- select {
- case r := <-result:
- return r.Val.(string), r.Err
- case <-ctx.Done():
- return "", ctx.Err()
- }
- }
调用的时候传入一个含 超时的 context 即可,执行时就会返回超时错误
- ❯ go run ./1.go
- panic: context deadline exceeded
2. 一个出错,全部出错
这个本身不是什么问题,因为 singleflight 就是这么设计的,但是实际使用的时候 如果我们一次调用要 1s,我们的数据库请求或者是 下游服务可以支撑 10rps 的请求的时候这会导致我们的错误阈提高,因为实际上我们可以一秒内尝试 10 次,但是用了 singleflight 之后只能尝试一次,只要出错这段时间内的所有请求都会受影响
这种情况我们可以启动一个 Goroutine 定时 forget 一下,相当于将 rps 从 1rps 提高到了 10rps
- go func() {
- time.Sleep(100 * time.Millisecond)
- // logging
- g.Forget(key)
- }()
总结
这篇文章从使用场景,到使用方法,再到源码分析和可能存在的坑给大家介绍了 singleflight,希望你能有所收获,没事看看官方的代码还是很有收获的,这次又学到了一个骚操作,用双重 defer 来避免死锁,你学废了么?
我们下一篇会开启一个新的系列,Go 可用性,敬请期待!
文章博客地址:https://lailin.xyz























