












美国的 DARPA(US Defense Advanced Research Projects Agency)曾经提出过第三波 AI 的概念,在其论述中,第三波 AI 里很重要的一部分就是达到通用人工智能。换句话说,当下的人工智能更多还是依赖于统计学信息,当传入模型的数据分布发生变化时(任务变化),就很难达到理想的效果。传统的 AI 中,大部分的 AI 算法都渴望找到一个生物学依据来进行对应,尽管有很多人质疑这种对应的必要性,而且就如飞机的发明一样,其实飞机的飞行方式跟鸟类有很大不同,但在发现更好的算法之前,向人脑学习或许是更好地选择。既然要向人脑学习,那么人类探索世界的过程就可以成为 AI 最好的老师,而哲学就是人类探索世界最神秘也最牢固的基石,很多学者也开始注意到哲学,除了将其作为虚无缥缈的 “底蕴” 外,他们也开始试着将哲学的思路真正融入到 AI 算法中来。
因此,本文也选择了一个角度,从科学认知的不变性(Hard To Vary, HTV)入手,然后介绍 HTV 存在的必要性以及在广义上如何基于内部可变性(internal variablity)和外部可变性(external variability)在 AI 中衡量并实现这种不变性,最后会介绍几个刚刚提出的具体的实现认知不变性的标准。
什么是科学认知不变性(HTV)

图 1:David Deutsch 在其 TED Talk 中提出了 HTV 的必要性 [4]
简单来说,科学认知不变性的意思就是我们提出的理论应该是不易变化的。下面是 Wiki 对于 HTV 相对完整的定义:
Theorists should seek explanations that are hard to vary. By that expression, the author intended to state that a hard-to-vary explanation provides specific details that fit together so tightly that it is impossible to change any detail without affecting the whole theory.
(如果学者们想要确定一个理论,那么这个理论最好是具有不变性的(难以被撼动,也就是 hard to vary)。这样的理论应该是这样的:所有的细节都很清晰而且相互紧密联系,如果你想推出这个理论的结果,你只有这一条路可以走,替换这条路(本理论)中的任何细节都会让这个理论不再成立。)[5]
基于这个角度来看,神话就是人类在认知世界时的一个极端的反面例子了(至少目前看来)。举个例子,在古希腊神话中。季节是这么来的:冥界之神哈迪斯(Hades)绑架了春天之神珀尔塞福涅(Persephone),并强迫她结婚。结婚后哈迪斯放走了春天之神,但是要求她定期回来。因此很神奇的,每年她真的就就会被迫回到冥界。而她的母亲,大地女神得墨忒耳 (Demeter) 悲伤不已,使大地变得寒冷而贫瘠,也就变成了人间的冬天。先不说这之中的不变性是否存在,就只说其内在逻辑,如果冬天是因得墨忒耳的悲伤而造成的,那么它必须同时发生在地球上的所有地方。所以如果古希腊人知道澳大利亚在得墨忒尔最悲伤的时候是最热的...... 他们就会知道他们的理论是错误的。
除了事实给这个故事带来的矛盾之外,四季的解释还可以由其他各种各样的故事来代替,比如说在新的故事里强迫春天之神回去的理由不是那一纸婚约,而是为了复仇,因为这里的珀尔塞福涅没有被释放,但是她逃跑了。从此之后,每年春天她会回来用她的春天之力向哈迪斯复仇——她用春天的空气给它的领地降温,这些热量散发到地面,创造了我们的夏天。这和最初的神话解释了相同的现象,同样是跟现实相符的。然而,它对现实的断言,在许多方面是相反的。这是可能的,因为原始神话的细节与季节无关,除了通过神话本身。
如果上面的故事太长太难理解,那么就再举个更简洁的例子,过去的神话中,下雨是龙王控制的,还有雷公电母负责雷电,这种故事都是很容易变的,只要改个人就行了,比如雷公改成雷神,就可以实现完全相同的结果,只不过内在的解释却全然不同,分别代表着中国古代神话和漫威。
这就是为什么 HTV 会被提出来,如果现在的科学也像这类故事一样内在逻辑其实很容易被篡改,然后还能达到完全相同的结果,那将会是很恐怖的,这也解释了为什么当下的 AI 黑盒模型很难被除 AI 从业者之外的人信任。那么为了实现不变性,这些神话里缺了什么?回到开始对于季节的解释上,它们缺失的一个关键元素是该理论内部演绎逻辑所产生的约束。现代科学对季节的解释就是一个很好的例子,因为它涉及到太阳光线和地轴倾斜的一系列紧密的几何推导。尽管它也有一些自由的参数,如倾斜的角度等,但大多数的解释都来源于于不能改变的几何推论。当然,这类约束存在的前提是我们要建立的知识的一致性。
HTV 能做什么
现在的 AI 行业其实正在蓬勃发展,有几家公司已经推出了全自动驾驶汽车,而谷歌的 Duplex 系统凭借其能够进行自然语言对话的能力赢得了很多受众。而最近的 GPT3 模型已经证明能够编写非常令人信服的故事,并在测试期间甚至可以执行语料外的任务(论文中的零样本学习部分)。然而,仍有许多人工智能无法做到的事情。今天的人工智能系统缺乏人类水平的常识理解,在机器人操作物体方面很笨拙,在任意推理方面也很差。另一个问题是,如今的人工智能无法从人类这样的少数例子中学习,需要大量数据来进行训练。然而,最重要的是,今天的人工智能系统都很狭窄,也就是 DARPA 提到的 Narrow AI——它们只能在训练数据分布的范围内执行它们被训练完成的任务。只要今天的人工智能系统被要求在训练数据分布之外工作,它们通常就会失败。
换句话说,当前的 AI 更注重归纳(Induction)出来的结果。但是矛盾点就在这里,如果 AI 真的要向人脑学习,那学者们就很难绕开波普尔(Popperian)提出的认知论,而在这个认知论中,他反对归纳法,认为归纳法不是科学知识增长和发展所必需的。而目前的很多机器学习甚至很多科学研究,其实本质上都相当于贝叶斯归纳法,而且当下一个很流行的观点就是,所有的人工智能系统都是近似的索罗门诺夫归纳法(Solomonoff induction)。
就像某辩论节目中说的那样,哲学更多是用来证伪,而不是用来证实。而 AI 正是在为了几乎为了几乎不可能的 “证实” 在努力。简单来说,AI 希望能够产生理论,而且理论完全准确。但这显然是不可能的。在波普尔看来,理论向来都是为了解决问题而出现的“大胆猜想”,而不是直接从经验中学来的。举个例子,星星其实也是一个个太阳,只不过他们比太阳离我们更远,这是阿纳萨哥拉斯(Anaxagoras)在公元前 450 年首次提出的大胆猜想。尽管人工智能研究人员对如何产生这样的猜测非常感兴趣,但波普尔并不太关心如何产生猜测,相反,他认为这是一个心理学家需要回答的问题。毕竟,一个猜想的真实性与它的来源无关。虽然经验能够并且确实告诉我们哪些猜想应该保留,哪些应该抛弃,特别是以经验检验的形式,但在波普尔看来,经验总是带有理论色彩的。换句话说,不可能像弗朗西斯 · 培根所说的那样,以一种完全客观的方式进行观察。
对波普尔来说,理论和观测哪个先出现的问题很像先有鸡还是先有蛋的问题。科学理论是建立在观察的基础上的,但从某种程度上说,这些观察又是由之前的科学理论提供的,这样不断追溯我们甚至可以追溯到史前科学的神话中。因此,尽管理论的实证检验在证明某些理论是错误的同时保留其他理论方面发挥着作用,但波普尔认为,从根本上说,所有的理论都来源于 “内部”,而不是来自外部的印象。如果可证伪性是一个理论是否科学的关键,那么建立在神话之上的理论,能够对神、魔鬼和鬼魂的行为做出可证伪的预测,就应该被认为是科学的吗?波普尔通过他的“可证伪性的程度” 概念,在一定程度上解决了将这些明显不科学的理论从科学领域中移除的任务,但这一原则的有效性我们依然不清楚。
于是 HTV 的存在就很有必要了,因为它好像可以用于作为区分科学理论和不科学理论的替代标准。对应的,AI 既然声称自己的模型要成为智能,那么 HTV 也可以用来证明 AI 模型输出的有效性。
AI 与 HTV 的关系
通常来说,HTV 可以这么解释:对应一个特定的理论,有多少个等价的解释存在。例如,在机器学习的环境中,HTV 原理可以分别应用于各种类型的模型架构,每一种都有固定数量的参数。有更多参数的模型能够表达更大的函数类,因此更容易变化。
从表面上看,HTV 原理似乎与经典统计中的偏 - 方差权衡(bias-variance trade-off)的其中一方面有关,即参数过多的模型更容易对其训练数据进行过拟合,导致对测试数据的泛化能力较差。然而,回想一下,我们感兴趣的是外推(分布外的模型能力),而不是训练分布范围内的经典泛化。偏差 - 方差权衡只针对分布中的泛化,因此与 HTV 原理是基本不相干的。而且在机器学习中,随着更多的参数添加到模型中,偏见 - 方差权衡已经被证明会失效——如超过某个阈值,导致 “双下降” 曲线的发生[6]。因此目前来说,更多的参数总是有帮助的,而不会有坏处。所以,偏差 - 方差权衡本身的存在也变得值得怀疑了。如何区分适用偏差 - 方差权衡的模型和不适用偏差 - 方差权衡的模型仍然是一个正在进行的研究领域。同时,过度拟合的问题通常可以用更大的数据集来补偿。因此,大型模型在本质上并不是不好的,这取决于可用数据的数量。
因此,其实 HTV 与奥卡姆剃刀(Occam’s razor)原则似乎更接近。简单来说,这个原则所表达的意思就是模型(参数)越简单越好,简单的模型可以完成的事情没必要用复杂的东西来完成。Kolmogorov complexity 可以很好地衡量这一原则(具体在 AI 中如何应用会在后面说)。
如果字符串 s 的描述 d(s)具有最小长度 (即使用最小比特数),则称为 s 的最小描述,d(s) 的长度 (即最小描述中的比特数) 为 s 的 Kolmogorov 复杂度,写成 K(s)。而最短描述的长度取决于描述语言的选择; 但是改变语言的影响是有限度的(这个结果被称为不变性定理)。这在 AI 中,这种简单性的衡量可以有有两种方式:
- 一是利用所有已有的解释框架,或者看这个训练好的模型有多复杂。Hochreiter 和 Schmidhuber 发现,在参数空间的损失函数表面上存在平面极小值的深度学习模型更易于推广。这一点很好解释,平面极小值表示该模型拥有较低复杂度(更易于压缩)。但是,最近发现了与以下观点相反的例子:损失函数曲率较低的深度学习模型具有更高的通用性。如果结合 Popper 的观点,这种利用具有较低曲率的函数比具有较高曲率的函数 “更简单” 等观点来证明简单性是不对的,Popper 认为,通过简单性来进行函数排序的做法是出于美学或实践考虑,但并没有在任何深层次的认知原理中建立良好的基础。
- 衡量简单性的另一种方法是查看模型中自由参数的数量。这项措施似乎更符合 Deutsch 的可变性概念。带有更多自由参数的模型(或使用 Occam 的语言 “实体”)更具可变性,因为可以轻松地调整参数以适合不同的数据。Deutsch 却反驳了这一观点 - 实体较少的模型可变性较小,他说:“有很多简单的解释都是高度可变的,例如'Demeter did it'。” 看起来 Deutsch 正在研究的是理论上的各种约束,包括内部和外部,以及参数的微小变化改变模型预测的程度。弗朗索瓦 · 乔列(Fran Ocois Chollet)辩称,奥卡姆(Occam)的剃刀与推断是对立的。例如,如果模型是在训练数据上取得良好性能的最简单方法,那么在新情况下就不太可能取得良好的效果。Chollet 认为模型应该包含 “外部” 信息,以便能够进行推断。
怎样衡量 AI 模型的 HTV 性
要衡量 AI 模型的 HTV 性,就要先明确 HTV 性在 AI 模型中的表现形式是什么。深度学习在工业界应用的常见问题就是极其不稳定,就比如图像识别领域,照明条件、图像分辨率、图像的呈现形式等等等等,都有可能成为深度学习模型的拦路虎。另外一个比较出名的例子就是 DeepMind 为了电脑游戏《星际争霸》而开发的 AlphaStar 系统了。对于给定的地图和角色,模型可以轻松战败人类,但这种能力不能泛化到其他的角色和地图中,必须分别重新训练。这些问题都在向我们说明,AI 模型很难在训练数据的分布外完成其任务,也就是很难完成条件跟训练时不同的任务。而 HTV 则指引我们,一个好的模型,应该在一个新的场景下以最小的代价最高程度地完成新的任务。
因此对应于训练好的模型,[1]中定义了两个概念:
- 内部灵活性(internal variability):一个模型 / 理论在多大程度上可以内部改变,同时仍然产生相同的预测。很明显这个越小越好,如果以上面的神话为例,神话的内部灵活性显然极大;
- 外部灵活性(external variability):为了适应新的数据,模型必须改变多少。很显然,这个条件是越小越好,也就是说以最低的代价完成新任务。
对应于这两个性质,如果能够很好地衡量 AI 模型中这两个性质的实现程度,那么就能更好的达到所谓的通用人工智能(Artificial General Intelligence, AGI)。本小节的剩下内容会分开介绍这两个性质在 AI 中对应什么,以及一些概念上对这些性质进行衡量的方式。
内部灵活性
内部灵活性的定义是一个模型 / 理论在多大程度上可以内部改变,同时仍然产生相同的预测。考虑一个基于输入变量 x 预测输出 y 的常见问题。科学家首先会引入与现有系统相关的先验知识,并且通常会引入先验已知的科学定律。然后,利用这些先验知识,他们将为该关系派生或猜测一种功能形式,使其适合数据,并查看其工作情况。重要的是,该功能保持相对简单,因此仍然可以理解 - 除了准确预测之外,还存在理解的隐含需求。相比之下,在机器学习中,从业人员仅关注预测准确性,因此可以接受大的黑匣子功能。Leo Brieman 指出,使用大型多参数函数(例如神经网络)时会出现一个奇怪的事实–大量模型在任何数据集 {x,y} 上都可能具有相等的误差(损失)[8]。每当数据嘈杂时都是如此,就像在任何实际应用程序中一样。他称这是罗生门效应,是在一部日本电影中,四个人都目睹了一个人死亡的事件。在法庭上,他们都报告看到相同的事实,但是对于所发生的事情,他们的解释截然不同。在神经网络中也可以发现这种有趣的现象——用不同的随机初始化训练的深度神经网络可以达到相同的精度,但内部工作方式不同(例如,使用不同的功能),这是一个未被充分认识的事实。测量深度学习模型的罗生门集的大小,相当于确定等价最小值的数量。这是一个水平集问题,据我们所知,在这一领域还没有做太多的研究,并且没有简便的方法来计算此集合的大小。
外部灵活性
那么怎么实现分布外的预测能力呢,那模型需要更勇敢的向外进行推理,也就是外断(Extrapolation)。为了衡量外断的能力,也有了外部灵活性的概念。为了衡量外部灵活性,我们可以再次假设我们正在为一个简单的函数 y = f(x)建模,并试图将它拟合到一个数据集 {(x, y)}。为了测量外部可变性,我们希望直观的知道我们需要改变多少 f(x) 来使模型适应数据集的变化。我们可以通过考虑两种截然不同的预测模型来进一步了解这一点——k 最近邻和基于物理的模拟来计算核塌超新星中作为其质量函数的最大压力。第一种模型可以灵活地适用于任何函数 y = f(x),而第二种模型则是为特定用途量身定制的。另一个高度灵活模型的例子是基于优化器的神经网络(在给定数据集的情况下做出预测,神经网络得先在数据上拟合)。
为了进行量化,我们必须有一种方法来量化模型中的变化,以适应新的数据集。算法信息理论可以帮助解决这两个问题。给定一个图灵机和数据集 D1, D1 中的算法信息,也称为 Kolmogorov 复杂度,是用我们选择的特定图灵机复制 D1 的最短程序的比特串 s1 的长度。记为 H(D1) = length(s1)。现在假设我们有一个在不同数据集 DAI 上训练过的人工智能算法 sAI,我们希望测量它需要改变多少才能在 D2 上工作得最优。s1 与 sAI 之间的相对算法信息,记为 H(s1|sAI)是给定 sAI 复制 s1 的最短的改变算法的长度。因此,它是一种使 sAI 在 D2 上发挥最优作用所需的变化量的测量方法。不幸的是,这种复杂性是无法计算的。然而,我们可以利用这个复杂性的近似值,而不是试图找到复制 D2 的最优程序。我们指定一个精度边际(尽可能多地列举所有可能性),然后,在我们设定的范围内寻找重现 D2 所需的 sAI 长度的最小变化。注意,我们不关心 sAI 有多大,只关心它需要改变多少来适应新的数据 DAI。因此,这种 “HTV” 性的概念与 “奥卡姆剃刀” 是不同的。我们还没有指定如何设置 DAI (AI 设计的初始数据集)和 D2。显然,这些数据集不能随机生成。无免费午餐定理说明所有算法在对每个可能的问题平均时都是等价的。因此,当试图从一个随机选择的数据集推断到另一个数据集时,所有算法都将处于平等的基础上。我们所处的情况与 Chollet 试图严格定义智力时所面临的情况非常相似。Chollet 的解决方案是将问题空间限制为一组人类可以解决的问题。乔列指出,自然世界符合一系列非常基本的先验,如客体性(存在不同的对象)、基本物理学、主体性(存在有目标的主体)、数字和算术、基本几何和拓扑。我们同样可以断言 D1 和 D2 的生成必须符合一组先验规则。或者更简单一点,我们可以说 D1 和 D2 是由物理现象产生的。这充分限制了问题 / 数据空间,使外推变得可行。
如何让模型学习到 HTV 解

- 论文地址:https://arxiv.org/pdf/2009.00329.pdf
- Code: https://github.com/gibipara92/learning-explanations-hard-to-vary
前面较为表面地论述了 HTV 与 AI 的关系,为了让 HTV 真正对 AI 算法产生效果,还有很多细节需要确定,比如说 HTV 可以解决 AI 的具体什么问题,怎么解决等等。LEARNING EXPLANATIONS THAT ARE HARD TO VARY 给出了一个很好地尝试,它首先清楚地定义了在 AI 中 HTV 可以帮助解决的问题(如图 2 所示):
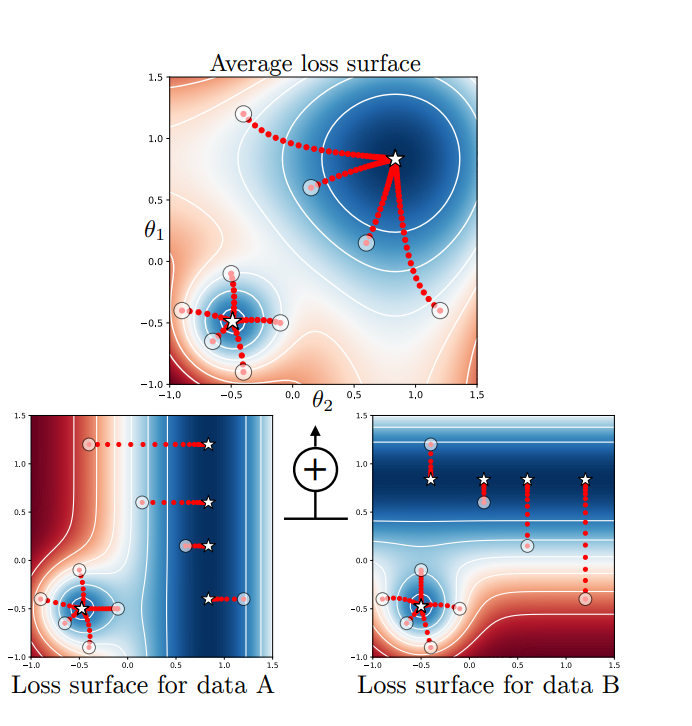
图 2:HTV 对应 AI 中的问题 [7]
这个问题简单来说就是当数据分布变化时,最优解可能会发生变化,从而也就失去了不变性。为了验证这一点,作者特意生成了两组数据,然后按照传统的训练方法在不同的初始化参数(白色圆圈)下获得了两个局部最优解(星星),但是当这两组数据分开训练的时候,由于生成数据的特殊性,两组数据的损失曲面会在一条线(左下的图是一条竖线,右下图是一条横线)上达到最小值,那么这一条线上的所有点都是局部最优解,会产生很多很多个局部最优解,这种情况下基本就很难在找到最上面图右上角的那个最优解了,除非初始化的参数正好让他们得到了 (0.8,0.8) 这个最优解(概率几乎为 0,相当于 1/*∞*)。
在这个例子里,显然下面两张图中左下角的解符合 HTV 的原则,而其他的解都极其易于变化,而当数据变多时,这些极易变化的解大多数都不在有用了。作者也用了一个更加现实主义的例子解释了 HTV 在 AI 中到底需要实现什么效果(如图 3 所示):

图 3:HTV 可以解决什么[7]
图 3 展示了两种笔记,左边那种笔记很难用再其他的棋谱上(如果棋谱尺寸变化,就不再有用了),但是右图的笔记是可以的。比如如果有第三本棋谱,棋谱的大小比例跟图 3 中的棋谱完全不同,这时出现了跟左图中类似的场景,用箭头就很可能会出错。想象一个比图 3 大一倍的棋谱,那箭头指向的位置可能正好比原来少一半的格子,而用符号描述的方法就不存在这种问题。
上面的例子也从侧面论证了 HTV 的重要性,图示类的笔记很容易改变,如果箭头弯一下或者棋谱变一下都会产生问题,而用文字的表述时,想要表达每一步棋的方法是确定的,也就更易于广泛地推广到更多的棋谱。因此,作者希望找到类似于右图的笔记作为最优解。
为了解决这个问题,作者提出了一种 AND mask,这种 mask 不是 mask 输入,而是对梯度进行 mask。作者先把数据分成多份,每一份被认定为一个环境中产生的数据(类似于平时训练时的 batch),在正常的训练中,我们会对每个 batch 进行类似于 average 的操作,这样就会导致图 4 所示的问题,Batch A 和 Batch B 的梯度方向完全不一致,但最终他们的影响都被保留了。
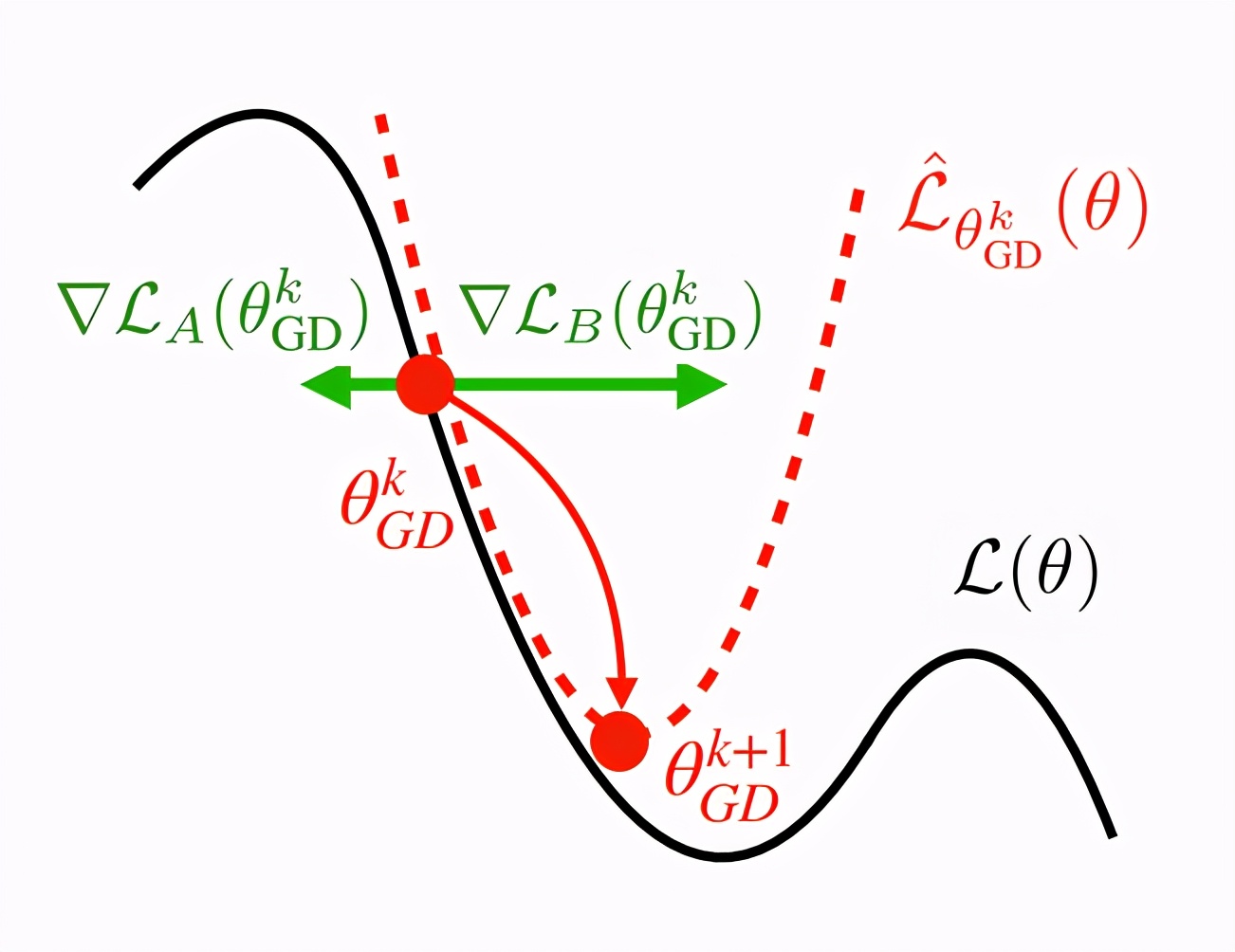
图 4:非一致性[7]
为了确认哪些梯度要被 mask,对于每个环境(batch)下得到的参数θ,作者在参数θ的情况下对每个环境(下式中的 e,也就是 batch)的损失函数进行比较从而得到这个参数 ILC(Invariant Learning Consistency, 学习的一致性)。简单来说,就是只保留那些被更多数据认可的梯度方向,作者提到的 geometric average 也是为了表达这个意思。
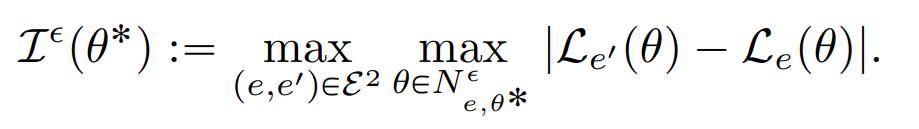
除了前面提到的具体解决方案(AND mask)外,文中也提纲挈领的提出了几个导致训练结果不能 HTV 的常见问题(有些其实已经被解决了):
- 没找到最优解就停止了训练。既然没找到最优解,那么更别说找到 HTV 解了。
- 梯度聚合方式。如果在训练的时候,信号是独立学习的(batch),那么这些信号的聚合方式就很重要了,合理的聚合方式才能保证所有信息不被丢失。如前文(图 4)所示,我们常用的 average 在很多情况下会丢失重要的信息,比如图 4 中向左的信息就被丢失了,如果更多的 batch 希望向左,但是值却很小,那么 average 下还是向右,但是更 general 的方案显然是向左。
最后作者在自己生成的数据上验证了自己的想法,也在 CIFAR 10 上确定了自己的方式有一定的优势,虽然所有的实验对比都是在一定的限制下的,但是本文提出的思路,以及将 HTV 嵌入到 AI 中的思路,都很值得学习。
总结
对于 HTV 性,如果将来可以将这一性质定量的加入到模型的损失函数中去,那么可以预见的,AGI 将离人类更进一步。当然,本文全篇的假设还是基于如果 AI 的学习对象还是人脑,如果 AI 研究过程中能够发现一些跟人脑功能无关,但是依旧有效的算法,也未尝不可。总而言之,为了实现 DARPA 所说的第三波 AI 甚至更高级的 AI,我们需要发现一种更综合的 loss 来完成我们预期的任务。






















