













近日,首篇深度学习模型复杂度综述「Model Complexity of Deep Learning: A Survey」在arXiv上线。论文作者为著名大数据科学家裴健教授与他的两位学生,以及微软亚洲研究院的两位合作者。44页的综述从深度学习模型框架、模型规模、优化过程和数据复杂性对现有成果进行了回顾。
在机器学习、数据挖掘和深度学习中,模型复杂性始终是重要的基本问题。
模型的复杂性不仅会影响模型在特定问题和数据上的可学习性,模型在看不见的数据上的泛化能力也与之有关。
模型的复杂性不仅受模型体系结构的本身影响,还受到数据分布,数据复杂性和信息量的影响。
因此近年来,模型复杂性已成为一个越来越活跃的方向,在模型体系结构搜索、图形表示、泛化研究和模型压缩等领域都至关重要。
近日,首篇深度学习模型复杂度综述「Model Complexity of Deep Learning: A Survey」在arXiv上线。
并对这两个方向的最新进展进行了回顾。
论文作者为著名大数据科学家裴健教授与他的两位学生,以及微软亚洲研究院的两位合作者。
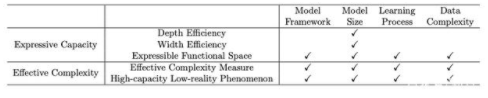
深度学习的模型复杂性可以解释为「表达能力」和「有效模型复杂度」。在这篇论文在,研究人员沿着模型框架、模型尺寸、优化过程、数据复杂度四个重要因素对这两类模型的现有研究进行回顾。
最后,作者再从理解模型泛化能力、优化策略、模型的选择与设计对其应用进行论述。
可以说,理解深度学习模型复杂度,看这一篇就够了。
首篇深度学习模型复杂度综述,四个重要因素
首先,我们先来看模型复杂度受哪些因素影响。
模型框架
模型框架的选择影响模型的复杂性。影响因素包括模型类型(如FCNN、CNN),激活函数(例如,Sigmoid、ReLU)等。不同的模型框架可能需要不同的复杂性度量标准和方法可能无法直接相互比较。
模型尺寸
深度模型的大小影响模型的复杂度。一些常见的所采用的模型尺寸测量方法包括参数个数、参数个数隐藏层的数量、隐藏层的宽度、过滤器的数量以及过滤器大小。在同一模型框架下,模型的复杂性对于不同的大小,可以通过相同的复杂性度量进行量化从而成为可比较的标准。
优化过程
优化过程影响模型的复杂度,包括目标函数的形式、学习算法的选择和超参数的设置。
数据复杂度
训练模型的数据也会影响模型的复杂性。主要影响因素包括数据维度、数据类型和数据类型分布、由Kolmogorov复杂性度量的信息量等。
通常来说,复杂度的研究模型选取有如下两种:
一是指定模型(model-specific)的方法关注于特定类型的模型,并基于结构特征探索复杂性。例如,Bianchini等人和Hanin等人研究了FCNNs的模型复杂性,Bengio和Delalleau关注和积网络的模型复杂性。此外,一些研究进一步提出了激活的限制条件约束非线性特性的函数。
还有一种方法是跨模型(cross-model),当它涵盖多种类型的模型时,而不是多个特定类型的模型,因此可以应用于比较两个或多个更多不同类型的模型。例如,Khrulkov等人比较了建筑物连接对一般RNN、CNN和浅层FCNN复杂性的影响在这些网络结构和张量分解中。
「表达能力」与「有效模型复杂度」
模型的表达能力
模型的表达能力意味着这个模型在不同数据上的表达能力,即性能,综述主要分析方法是从下面四个角度分析。
深度效率(depth efficiency)分析深度学习模型如何从架构的深度获得更好地性能(例如,精确度)。
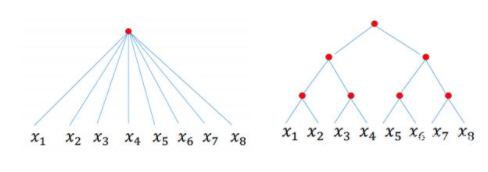
宽度效率(width efficiency)分析深度学习中各层的宽度对模型影响程度。
可表达功能空间(expressible functional space)研究可表达的功能由具有特定框架和指定大小的深模型表示,在不同参数的情况下。
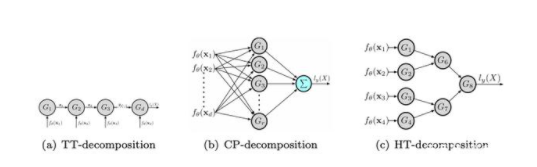
最后,VC维度和Rademacher复杂性是机器学习中表达能力的两个经典度量。
模型的有效复杂度
深度学习模型的有效复杂性也称为实际复杂性、实际表达能力和可用容量。
它反映了复杂性具有特定参数化的深部模型所代表的函数。深度学习模型的有效复杂性主要从以下两个方面进行了探讨。
有效复杂性的一般度量(general measures of effective complexity)设计深度学习模型有效复杂性的量化度量。
对高容量低现实现象的调查发现深度学习模型的有效复杂性可能远低于他们的表达能力。一些研究探讨了深度学习模型的有效复杂性和表达能力之间的差距。
模型复杂度的应用
这篇论文主要介绍了三个应用,理解模型泛化能力、模型优化、模型选择和设计。
理解模型泛化能力
深度学习模型总是过于参数化,也就是说,它们的参数要多得多,模型参数比最优解和训练样本数多。然而,人们经常发现大型的过参数化神经网络具有良好的泛化能力。一些研究甚至发现更大、更复杂的网络通常更具通用性。这一观察结果与函数复杂性的经典概念相矛盾,例如著名的奥卡姆剃须刀原则,更喜欢简单的定理。
什么导致过度参数化深度学习模型的良好泛化能力?
1、在训练误差为零的情况下,一个网络训练在真实的标签上,导致良好的泛化能力,其复杂度比在随机标签上训练的网络要低得多。
2、增加隐藏单元的数量或参数的数量,从而减少了泛化误差,有望降低复杂度。
3、使用两种不同的优化算法,如果都导致零训练误差,具有较好泛化能力的模型具有较低的复杂度。
优化策略
模型优化关注的是神经网络模型如何建立以及为什么建立,为什么可以成功训练。具体来说,优化一个深度学习模型一般是确定模型参数,使损失函数最小化非凸的。损失函数的设计通常基于一个问题和模型的要求,因此一般包括在训练集上评估的性能度量和其他约束条件。
模型复杂度被广泛用于提供一个度量来进行优化可追踪。例如,有效模型复杂性的度量指标神经网络有助于监测优化过程中模型的变化处理并理解优化过程是如何进行的。这样的度量也有助于验证优化算法新改进的有效性。
Nakkiran等人研究了训练过程中的双下降现象利用有效复杂度度量数据集的最大大小,在该数据集上可以得到零训练误差实现。结果表明,双下降现象是可以表示的作为有效复杂性的函数。Raghu等人和Hu等人提出了新的正则化方法,并证明了这些方法对减小复杂度是有效的。
模型选择和设计
给定一个具体的学习任务,研究人员如何为这个任务确定一个可行的模型结构。给出了各种不同体系结构和不同性能的模型复杂性,研究人员如何从中挑选出最好的模型?这就是模型选择和设计问题。
一般来说,模型的选择和设计是基于两者之间的权衡,预测性能和模型复杂性。

一方面,高精度的预测是学习模型的基本目标。模型应该能够捕获隐藏在模型中的底层模式训练数据和实现预测的精度尽可能高。为了表示大量的知识并获得较高的准确度,一个模型具有较高的表达能力,自由度大,体积大,需要更大训练集。在这个程度上,一个具有更多参数和更高的复杂性是有利的。
另一方面,过于复杂的模型可能很难进行训练,可能会导致不必要的资源消耗,例如存储、计算和时间成本。不必要的资源消耗特别是在实际的大规模应用中,应避免使用。为了这个目标,一个更简单的模型比一个更精确的模型更可取。
数据价值和数据资产管理
综述的作者裴健是数据科学领域的世界顶尖学者,加拿大西蒙弗雷泽大学计算机科学学院教授,还是加拿大皇家学会、加拿大工程院、ACM和IEEE的院士。
近日,在O'Reilly媒体集团原首席数据科学家Ben Lorica 罗瑞卡主持的podcast中,裴健教授谈论了数据价值和数据资产管理的问题。
他认为,第一,数据作为企业的核心资源,CFO和CDO要一起来关注数据资源的运转、使用和效益。第二,数据不仅仅是技术,企业急需组建有经济学家参与的核心团队来研发运营数据产品和数据资产。第三,每一家企业都有大量的上游和下游数据应用,企业的数据往往比自己所认知价值大得多,数字化数据化企业的业务并运营好数据资产具有重大的投资价值。
2021年4月29日至5月1日,裴健教授与论文的其他作者还将在SDM (SIAM International Conference on Data Mining ,SIAM数据挖掘国际会议)上进行演讲,对论文内容进行解读。
参考资料:
https://www.sfu.ca/~huxiah/sdm21_tutorial.html
https://youtu.be/VNesYXw-6hQ






















